
귀퉁이 서재
머신러닝 - 5. 랜덤 포레스트(Random Forest) 본문

이전 포스트에서 결정 트리(Decision Tree)에 대해 알아봤습니다. 랜덤 포레스트를 배우기 위해서는 우선 결정 트리부터 알아야 합니다. 결정 트리에 대해 잘 모른다면 이전 포스트를 먼저 보고 오시기 바랍니다. (머신러닝 - 4. 결정 트리)
랜덤 포레스트의 개념은 쉽습니다. 랜덤 포레스트의 포레스트는 숲(Forest)입니다. 결정 트리는 트리는 나무(Tree)입니다. 나무가 모여 숲을 이룹니다. 즉, 결정 트리(Decision Tree)가 모여 랜덤 포레스트(Random Forest)를 구성합니다. 결정 트리 하나만으로도 머신러닝을 할 수 있습니다. 하지만 결정 트리의 단점은 훈련 데이터에 오버피팅이 되는 경향이 있다는 것입니다. 여러 개의 결정 트리를 통해 랜덤 포레스트를 만들면 오버피팅 되는 단점을 해결할 수 있습니다.
원리
랜덤 포레스트의 예를 들어 보겠습니다. 건강의 위험도를 예측하기 위해서는 많은 요소를 고려해야 합니다. 성별, 키, 몸무게, 지역, 운동량, 흡연유무, 음주 여부, 혈당, 근육량, 기초 대사량 등등등... 수많은 요소가 필요할 것입니다. 이렇게 수많은 요소(Feature)를 기반으로 건강의 위험도(Label)를 예측한다면 분명 오버피팅이 일어날 것입니다. 예를 들어 Feature가 30개라고 합시다. 30개의 Feature를 기반으로 하나의 결정 트리를 만든다면 트리의 가지가 많아질 것이고, 이는 오버피팅의 결과를 야기할 것입니다. 하지만 30개의 Feature 중 랜덤으로 5개의 Feature만 선택해서 하나의 결정 트리를 만들고, 또 30개 중 랜덤으로 5개의 Feature를 선택해서 또 다른 결정 트리를 만들고... 이렇게 계속 반복하여 여러 개의 결정 트리를 만들 수 있습니다. 결정 트리 하나마다 예측 값을 내놓겠죠. 여러 결정 트리들이 내린 예측 값들 중 가장 많이 나온 값을 최종 예측값으로 정합니다. 다수결의 원칙에 따르는 것입니다. 이렇게 의견을 통합하거나 여러 가지 결과를 합치는 방식을 앙상블(Ensemble)이라고 합니다. 즉, 하나의 거대한 (깊이가 깊은) 결정 트리를 만드는 것이 아니라 여러 개의 작은 결정 트리를 만드는 것입니다. 여러 개의 작은 결정 트리가 예측한 값들 중 가장 많은 값(분류일 경우) 혹은 평균값(회귀일 경우)을 최종 예측 값으로 정하는 것입니다. 문제를 풀 때도 한 명의 똑똑한 사람보다 100 명의 평범한 사람이 더 잘 푸는 원리입니다.
아래는 랜덤 포레스트를 시각화한 것입니다.
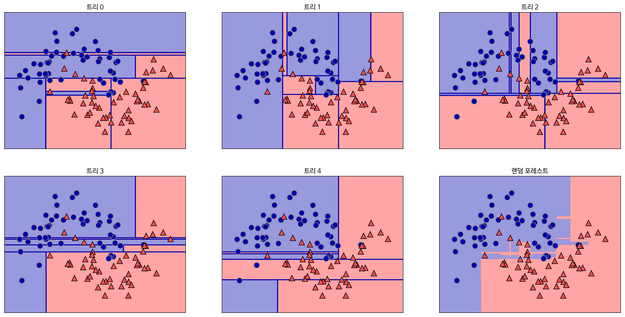
오른쪽 아래가 랜덤 포레스트의 Decision Boundary이고, 나머지는 결정 트리 각각의 Decision Boundary입니다. 보시면 아시겠지만 결정 트리의 경계는 다소 모호하고 오버피팅되어 있습니다. 5개의 결정 트리 경계를 평균 내어 만든 랜덤 포레스트의 경계는 보다 깔끔합니다.
파라미터
n_estimators: 랜덤 포레스트 안의 결정 트리 갯수
n_estimators는 클수록 좋습니다. 결정 트리가 많을수록 더 깔끔한 Decision Boundary가 나오겠죠. 하지만 그만큼 메모리와 훈련 시간이 증가합니다.
max_features: 무작위로 선택할 Feature의 개수
max_features가 전체 Feature 개수와 같으면 전체 Feature 모두를 사용해 결정 트리를 만듭니다. boostrap 파라미터가 False이면 비복원 추출하기 때문에 그냥 전체 Feature를 사용해 트리를 만듭니다. 반면 bootstrap=True이면 전체 Feature에서 복원 추출해서 트리를 만듭니다. 단, bootstrap=True는 default 값입니다. max_features 값이 크면 랜덤 포레스트의 트리들이 매우 비슷해지고, 가장 두드러진 특성에 맞게 예측을 할 것입니다. max_features 값이 작으면 랜덤 포레스트의 트리들이 서로 매우 달라집니다. 오버피팅이 줄어드는 효과가 있겠죠. max_features는 일반적으로 Defalut 값을 씁니다.
코드는 다른 모델과 매우 유사하므로 생략하겠습니다.
References
Reference1: 텐서 플로우 블로그 (결정 트리의 앙상블)
Reference2: 미디엄 (군중은 똑똑하다 - Random Forest)
Reference3: [파이썬][머신러닝][결정트리앙상블] 랜덤 포레스트
Reference4: sklearn.ensemble.RandomForestRegressor
'머신러닝' 카테고리의 다른 글
| 머신러닝 - 7. K-평균 클러스터링(K-means Clustering) (4) | 2019.07.29 |
|---|---|
| 머신러닝 - 6. K-최근접 이웃(KNN) (6) | 2019.07.27 |
| 머신러닝 - 4. 결정 트리(Decision Tree) (31) | 2019.07.22 |
| 머신러닝 - 3. 서포트 벡터 머신 (SVM) 실습 (0) | 2019.07.18 |
| 머신러닝 - 2. 서포트 벡터 머신 (SVM) 개념 (14) | 2019.07.15 |



