
귀퉁이 서재
DATA - 24. Data Wrangling (Assess Data) 본문

이전 챕터에서 데이터 모으기에 대해 배웠습니다. 이번 챕터는 데이터 랭글링의 두번째 단계, 데이터 평가하기입니다. Gathering한 데이터를 눈으로, 코드로 평가해야 합니다. 정제하기 전 데이터는 Dirty Data, Messy Data로 구분할 수 있습니다.
Dirty Data (Low Quality Data)
Dirty Data는 컨텐츠(Content) 자체에 문제가 있는 데이터입니다. 다른 말로 Low Quality Data라고도 합니다. 즉 데이터가 부정확하거나, 손상되었거나, 중복된 데이터를 의미합니다. Dirty Data는 다시 아래 4가지 문제로 구분할 수 있습니다.
Completeness: 모든 데이터가 채워져 있는가?
- 행, 열에 Null 값이 없는지 봐야합니다.
Validity: Schema를 충족하는가?
- 미리 정해놓은 constraint를 충족하는지를 봐야합니다. 가령, 사람의 키에 대한 데이터를 수집한다고 했을 때, height >=0 이라고 constraint를 정해놓을 것입니다. 이때 사람의 키가 -50(음수)이면 잘못된 값인 것이지요. 이 데이터는 Completeness문제는 없지만 (-50이라는 데이터가 존재하므로, 즉, Null이 아니므로) Validity는 충족하지 못한 것입니다.
Accuracy: 부정확한 데이터가 없는가?
- 홍길동의 키는 180인데, 170이라고 기록했다고 합시다. 이 데이터는 Completeness, Validity는 모두 충족했지만 Accuracy를 충족하지 못한 것입니다.
Consistency: 테이블 간, 테이블 내 표준 포맷(Standard format)을 지켰는가?
- 사람 키에 대한 데이터는 A라는 Table에서도 수집했고, B라는 Table에서도 수집했다고 합시다. 이때 A에서는 cm단위로 수집을 했고, B에서는 inch단위로 수집했다면 Completeness, Validity, Accuracy는 모두 충족했지만, Consistency를 충족하지 못한 것입니다. 테이블 간 혹은 테이블 내의 데이터 형식을 통일해야 합니다.
Messy Data (Untidy Data)
Messy Data는 구조(Structure)에 문제가 있는 데이터입니다. 다른 말로 Untidy data라고도 합니다. 즉, Messy Data는 Tidy Data가 아닌 데이터입니다. Tidy Data가 되기 위해서는 아래 3가지 조건을 충족해야 합니다.
Tidy Data 조건 (Reference1)
- Each variable forms a column.
- Each observation forms a row.
- Each type of observational unit forms a table.
아래 예제를 들어보겠습니다. 사람별로 A, B라는 약을 먹었을 때의 효과를 나타낸 표라고 해봅시다. 이때 표로 나타낼 수 있는 속성(variable)은 약의 종류, 복용후 결과치입니다. 각각의 속성은 하나의 Column을 구성해야 한다고 했습니다. (Each variable forms a column) 하지만, messy dataset은 '약 A를 먹었을 때 복용 후 결과치', '약 B를 먹었을 때 복용 후 결과치'가 column으로 되어 있습니다. 이것이 tidy data가 되기 위해서는 두번째 표처럼 하나의 속성이 하나의 column을 이루게 바꿔줘야 합니다. 약의 종류(Treatment)와 복용후 결과치(Result)가 각각의 Column이 되는 것입니다. 행이 더 길어졌을지라도 코드로 데이터 분석을 하기 위해서는 tidy dataset을 구성해줘야 합니다.
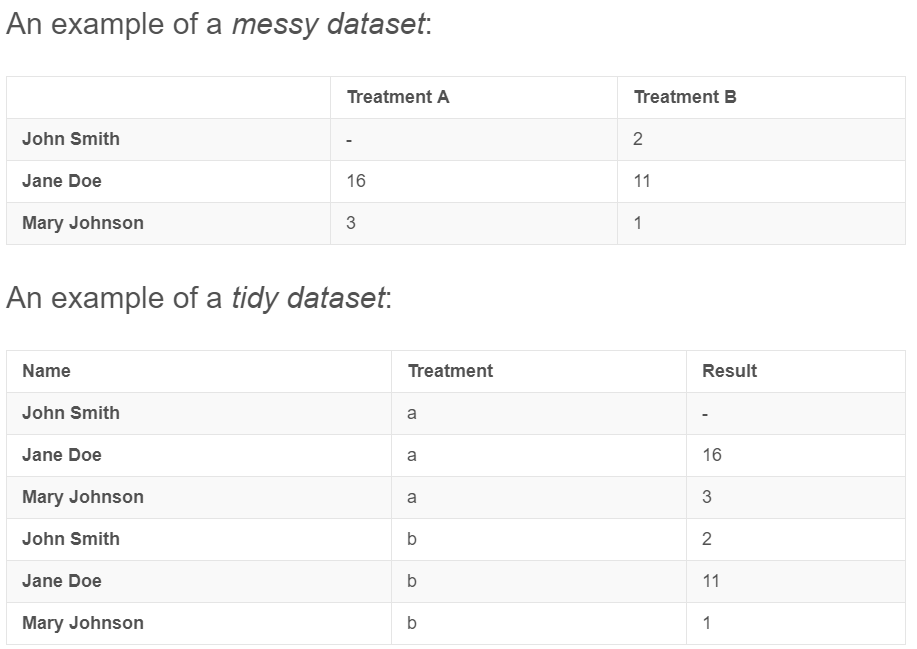
즉, Drity Data는 데이터 자체에 문제가 있는 것이고, Messy Data는 데이터 자체에는 문제가 없는데 Table의 구조적인 문제가 있는 것입니다. 이렇게 구분하여 데이터를 평가하면 보다 체계적으로 할 수 있습니다.
Reference
'데이터 분석' 카테고리의 다른 글
| DATA - 26. 데이터 시각화(Data Visualization)의 중요성 (0) | 2019.06.09 |
|---|---|
| DATA - 25. Data Wrangling (Cleaning Data) (0) | 2019.05.20 |
| DATA - 23. Data Wrangling (Gathering Data) II (4) | 2019.05.14 |
| DATA - 23. Data Wrangling (Gathering Data) (0) | 2019.05.10 |
| DATA - 22. 로지스틱 회귀(Logistic Regression) (8) | 2019.05.06 |


