
귀퉁이 서재
OpenCV - 28. 특징 매칭(Feature Matching) 본문

이번 포스팅에서는 특징 매칭에 대해 알아보겠습니다. 이번 포스팅 역시 '파이썬으로 만드는 OpenCV 프로젝트(이세우 저)'를 정리한 것임을 밝힙니다.
코드: github.com/BaekKyunShin/OpenCV_Project_Python/tree/master/08.match_track
특징 매칭(Feature Matching)
특징 매칭이란 서로 다른 두 이미지에서 특징점과 특징 디스크립터들을 비교해서 비슷한 객체끼리 짝짓는 것을 말합니다.
OpenCV는 특징 매칭을 위해 아래와 같은 특징 매칭 인터페이스 함수를 제공합니다.
- matcher = cv2.DescriptorMatcher_create(matcherType): 매칭기 생성자
matcherType: 생성할 구현 클래스의 알고리즘 ("BruteForce": NORM_L2를 사용하는 BFMatcher, "BruteForce-L1": NORM_L1을 사용하는 BFMatcher, "BruteForce-Hamming": NORM_HAMMING을 사용하는 BRMatcher, "BruteForce-Hamming(2)": NORM_HAMMING2를 사용하는 BFMatcher, "FlannBased": NORM_L2를 사용하는 FlannBasedMatcher)
OpenCV 3.4에서 제공하는 특징 매칭기는 BFMatcher와 FLannBasedMatcher가 있습니다. 객체를 생성하기 위해 해당 클래스의 생성자를 호출해도 되지만 cv2.DescriptorMatcher_create()의 파라미터로 구현할 클래스의 알고리즘을 문자열로 전달해주어도 됩니다.
cv2.DescriptorMatcher_create() 함수를 통해 생성된 특징 매칭기는 두 개의 디스크립터를 서로 비교하여 매칭 해주는 함수를 갖습니다. 3개의 함수가 있는데, match(), knnMatch(), radiusMatch()가 그것입니다. 세 함수 모두 첫 번째 파라미터인 queryDescriptors를 기준으로 두 번째 파라미터인 trainDescriptors에 맞는 매칭을 찾습니다.
- matches: matcher.match(queryDescriptors, trainDescriptors, mask): 1개의 최적 매칭
queryDescriptors: 특징 디스크립터 배열, 매칭의 기준이 될 디스크립터
trainDescriptors: 특징 디스크립터 배열, 매칭의 대상이 될 디스크립터
mask(optional): 매칭 진행 여부 마스크
matches: 매칭 결과, DMatch 객체의 리스트 - matches = matcher.knnMatch(queryDescriptors, trainDescriptors, k, mask, compactResult): k개의 가장 근접한 매칭
k: 매칭할 근접 이웃 개수
compactResult(optional): True: 매칭이 없는 경우 매칭 결과에 불포함 (default=False) - matches = matcher.radiusMatch(queryDescriptors, trainDescriptors, maxDistance, mask, compactResult): maxDistance 이내의 거리 매칭
maxDistance: 매칭 대상 거리
match() 함수는 queryDescriptors 한 개당 최적의 매칭을 이루는 trainDescriptors를 찾아 결과로 반환합니다. 그러나 최적 매칭을 찾지 못하는 경우도 있기 때문에 반환되는 매칭 결과 개수가queryDescriptors의 개수보다 적을 수도 있습니다.
knnMatch() 함수는 queryDescriptors 한 개당 k개의 최근접 이웃 개수만큼 trainDescriptors에서 찾아 반환합니다. k는 세 번째 파라미터입니다. k개의 최근접 이웃 개수만큼이라는 말은 가장 비슷한 k개만큼의 매칭 값을 반환한다는 뜻입니다. CompactResult에 default값이 False가 전달되면 매칭 결과를 찾지 못해도 결과에 queryDescriptors의 ID를 보관하는 행을 추가합니다. True가 전달되면 아무것도 추가하지 않습니다.
radiusMatch() 함수는 queryDescriptors에서 maxDistance 이내에 있는 trainDescriptors를 찾아 반환합니다.
위 세 함수인 match(), knnMatch(), radiusMatch() 함수의 반환 결과는 DMatch 객체 리스트입니다.
- DMatch: 매칭 결과를 표현하는 객체
queryIdx: queryDescriptors의 인덱스
trainIdx: trainDescriptors의 인덱스
imgIdx: trainDescriptor의 이미지 인덱스
distance: 유사도 거리
DMatch 객체의 queryIdx와 trainIdx로 두 이미지의 어느 지점이 서로 매칭 되었는지 알 수 있습니다. 또한 distnace로 얼마나 가까운 거리 인지도 알 수 있습니다.
매칭 결과를 시각적으로 표현하기 위해 두 이미지를 하나로 합쳐서 매칭점끼리 선으로 연결하는 작업이 필요한데, 이를 위해 OpenCV에서는 아래의 함수를 제공합니다.
- cv2.drawMatches(img1, kp1, img2, kp2, matches, flags): 매칭점을 이미지에 표시
img1, kp1: queryDescriptor의 이미지와 특징점
img2, kp2: trainDescriptor의 이미지와 특징점
matches: 매칭 결과
flags: 매칭점 그리기 옵션 (cv2.DRAW_MATCHES_FLAGS_DEFAULT: 결과 이미지 새로 생성(default값), cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG: 결과 이미지 새로 생성 안 함, cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS: 특징점 크기와 방향도 그리기, cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS: 한쪽만 있는 매칭 결과 그리기 제외)
BFMatcher(Brute-Force Matcher)
Brute-Force 매칭기는 queryDescriptors와 trainDescriptors를 하나하나 확인해 매칭되는지 판단하는 알고리즘으로 OpenCV에서는 cv2.BFMatcher 클래스로 제공합니다. Brute-Force 매칭기는 아래와 같이 생성합니다.
- matcher = cv2.BFMatcher_create(normType, crossCheck)
normType: 거리 측정 알고리즘 (cv2.NORM_L1, cv2.NORM_L2(default), cv2.NORM_L2SQR, cv2.NORM_HAMMING, cv2.NORM_HAMMING2)
crosscheck: 상호 매칭이 되는 것만 반영 (default=False)
거리 측정 알고리즘을 전달하는 파라미터인 normType의 값은 다음과 같이 계산합니다.
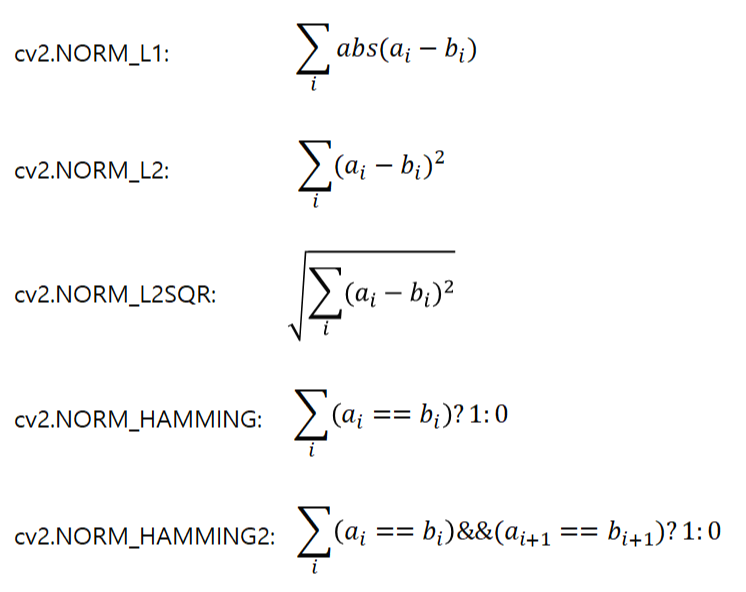
세 가지 유클리드 거리 측정법과 두 가지 해밍 거리 측정법 중에 선택을 할 수 있습니다. SIFT와 SURF 디스크립터 검출기의 경우 NORM_L1, NORM_L2가 적합하고 ORB로 디스크립터 검출기의 경우 NORM_HAMMING이 적합하며, NORM_HAMMING2는 ORB의 WTA_K가 3 혹은 4일 때 적합하다고 합니다. crosscheck가 True이면 양쪽 디스크립터 모두에게서 매칭이 완성된 것만 반영하므로 불필요한 매칭을 줄일 수 있지만 그만큼 속도가 느려진다는 단점이 있습니다.
아래는 SIFT 디스크립터 검출기로 검출한 두 이미지의 특징점 및 디스크립터를 사용하여 BFMatcher로 매칭되는 부분을 찾는 예제 코드입니다.
# BFMatcher와 SIFT로 매칭 (match_bf_sift.py)
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# SIFT 서술자 추출기 생성 ---①
detector = cv2.xfeatures2d.SIFT_create()
# 각 영상에 대해 키 포인트와 서술자 추출 ---②
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# BFMatcher 생성, L1 거리, 상호 체크 ---③
matcher = cv2.BFMatcher(cv2.NORM_L1, crossCheck=True)
# 매칭 계산 ---④
matches = matcher.match(desc1, desc2)
# 매칭 결과 그리기 ---⑤
res = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# 결과 출력
cv2.imshow('BFMatcher + SIFT', res)
cv2.waitKey()
cv2.destroyAllWindows()
우선 SIFT 디스크립터 검출기를 생성합니다. 그런 다음 각 이미지에 대해 특징점과 디스크립터를 추출합니다. BFMatcher 객체를 생성한 뒤 이를 활용하여 두 이미지의 디스크립터로 매칭 계산을 합니다. 매칭 결과를 화면에 표시까지 해주었습니다.
다음은 SURF 디스크립터 검출기로 얻은 디스크립터를 BFMatcher로 매칭하는 코드입니다.
# BFMatcher와 SURF로 매칭 (match_bf_surf.py)
import cv2
import numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# SURF 서술자 추출기 생성 ---①
detector = cv2.xfeatures2d.SURF_create()
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# BFMatcher 생성, L2 거리, 상호 체크 ---③
matcher = cv2.BFMatcher(cv2.NORM_L2, crossCheck=True)
# 매칭 계산 ---④
matches = matcher.match(desc1, desc2)
# 매칭 결과 그리기 ---⑤
res = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('BF + SURF', res)
cv2.waitKey()
cv2.destroyAllWindows()
매칭되는 부분이 더 많아진 걸 볼 수 있습니다. 다음으로 ORB를 통한 매칭코드를 살펴보겠습니다.
# BFMatcher와 ORB로 매칭 (match_bf_orb.py)
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# SIFT 서술자 추출기 생성 ---①
detector = cv2.ORB_create()
# 각 영상에 대해 키 포인트와 서술자 추출 ---②
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# BFMatcher 생성, Hamming 거리, 상호 체크 ---③
matcher = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
# 매칭 계산 ---④
matches = matcher.match(desc1, desc2)
# 매칭 결과 그리기 ---⑤
res = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('BFMatcher + ORB', res)
cv2.waitKey()
cv2.destroyAllWindows()
FLANN(Fast Library for Approximate Nearest Neighbors Matching)
BFMatcher는 모든 디스크립터를 전수 조사하므로 이미지 사이즈가 클 경우 속도가 굉장히 느립니다. 이를 해결하기 위해 FLANN을 사용할 수 있습니다. FLANN은 모든 디스크립터를 전수 조사하기 보다 이웃하는 디스크립터끼리 비교를 합니다. 이웃하는 디스크립터를 찾기 위해 FLANN 알고리즘 함수에 인덱스 파라미터와 검색 파라미터를 전달해야 합니다.
OpenCV는 FLANN 객체 생성을 위한 함수로 cv2.FlannBasedMatcher()를 제공합니다. 이 함수는 인덱스 파라미터로 indexParams를 전달받고 검색 파라미터로 searchParams를 전달받습니다. 두 파라미터 모두 딕셔너리 형태입니다.
matcher = cv2.FlannBasedMatcher(indexParams, searchParams)
파라미터로 전달 받는 인덱스 파라미터와 검색 파라미터는 다음과 같은 값을 갖습니다.
indexParams: 인덱스 파라미터 (딕셔너리)
- algorithm: 알고리즘 선택 키, 선택할 알고리즘에 따라 종속 키를 결정하면 됨
FLANN_INDEX_LINEAR=0: 선형 인덱싱, BFMatcher와 동일
FLANN_INDEX_KDTREE=1: KD-트리 인덱싱 (trees=4: 트리 개수(16을 권장))
FLANN_INDEX_KMEANS=2: K-평균 트리 인덱싱 (branching=32: 트리 분기 개수, iterations=11: 반복 횟수, centers_init=0: 초기 중심점 방식)
FLANN_INDEX_COMPOSITE=3: KD-트리, K-평균 혼합 인덱싱 (trees=4: 트리 개수, branching=32: 트리 분기 새수, iterations=11: 반복 횟수, centers_init=0: 초기 중심점 방식)
FLANN_INDEX_LSH=6: LSH 인덱싱 (table_number: 해시 테이블 수, key_size: 키 비트 크기, multi_probe_level: 인접 버킷 검색)
FLANN_INDEX_AUTOTUNED=255: 자동 인덱스 (target_precision=0.9: 검색 백분율, build_weight=0.01: 속도 우선순위, memory_weight=0.0: 메모리 우선순위, sample_fraction=0.1: 샘플 비율)
searchParams: 검색 파라미터 (딕셔너리)
- searchParams: 검색 파라미터 (딕셔너리)
checks=32: 검색할 후보 수
eps=0.0: 사용 안 함
sorted=True: 정렬해서 반환
인덱스 파라미터는 결정해야 할 값이 너무 많아 복잡합니다. 그래서 아래와 같이 설정하는 것을 권장합니다.
<SIFT나 SURF를 사용하는 경우>
FLANN_INDEDX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)<ORB를 사용하는 경우>
FLANN_INDEX_LSH = 6
index_params = dict(algorithm=FLANN_INDEX_LSH, table_number=6, key_size=12, multi_probe_level=1)아래 코드는 SIFT 검출기로 추출한 디스크립터를 cv2.FlannBasedMatcher로 매칭하는 예제입니다.
# FLANNMatcher와 SIFT로 매칭 (match_flann_sift.py)
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# SIFT 생성
detector = cv2.xfeatures2d.SIFT_create()
# 키 포인트와 서술자 추출
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# 인덱스 파라미터와 검색 파라미터 설정 ---①
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
# Flann 매처 생성 ---③
matcher = cv2.FlannBasedMatcher(index_params, search_params)
# 매칭 계산 ---④
matches = matcher.match(desc1, desc2)
# 매칭 그리기
res = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('Flann + SIFT', res)
cv2.waitKey()
cv2.destroyAllWindows()
아래 코드는 SURF 검출기로 추출한 디스크립터를 cv2.FlannBasedMatcher로 매칭하는 예제입니다.
# FLANNMatcher와 SURF로 매칭 (match_flann_surf.py)
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# SURF 생성
detector = cv2.xfeatures2d.SURF_create()
# 키 포인트와 서술자 추출
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# 인덱스 파라미터와 검색 파라미터 설정 ---①
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
# Flann 매처 생성 ---③
matcher = cv2.FlannBasedMatcher(index_params, search_params)
# 매칭 계산 ---④
matches = matcher.match(desc1, desc2)
# 매칭 그리기
res = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('Flann + SURF', res)
cv2.waitKey()
cv2.destroyAllWindows()
아래 코드는 ORB 검출기로 추출한 디스크립터를 cv2.FlannBasedMatcher로 매칭하는 예제입니다.
# FLANNMatcher와 ORB로 매칭 (match_flann_orb.py)
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# ORB 추출기 생성
detector = cv2.ORB_create()
# 키 포인트와 서술자 추출
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# 인덱스 파라미터 설정 ---①
FLANN_INDEX_LSH = 6
index_params= dict(algorithm = FLANN_INDEX_LSH,
table_number = 6,
key_size = 12,
multi_probe_level = 1)
# 검색 파라미터 설정 ---②
search_params=dict(checks=32)
# Flann 매처 생성 ---③
matcher = cv2.FlannBasedMatcher(index_params, search_params)
# 매칭 계산 ---④
matches = matcher.match(desc1, desc2)
# 매칭 그리기
res = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# 결과 출력
cv2.imshow('Flann + ORB', res)
cv2.waitKey()
cv2.destroyAllWindows()
지금까지 살펴본 매칭 결과에는 잘못된 매칭 정보가 너무 많습니다. 가령 바로 위 그림에서 로보트 태권V와 흰 가운을 입고 있는 인형과 매칭이 되는 부분도 있습니다. 이는 분명 잘못 매칭된 결과입니다. 따라서 잘못된 매칭 결과를 제거하여 올바른 매칭점을 찾아내는 작업이 추가로 필요합니다. 이에 대해서는 다음 포스팅에서 살펴보겠습니다.
'OpenCV' 카테고리의 다른 글
| OpenCV - 30. 배경 제거(Background Subtraction) (2) | 2020.11.29 |
|---|---|
| OpenCV - 29. 올바른 매칭점 찾기 (10) | 2020.11.21 |
| OpenCV - 27. 특징 디스크립터 검출기 (SIFT, SURF, ORB) (2) | 2020.11.09 |
| OpenCV - 26. 이미지의 특징점(Keypoints)과 특징점 검출기(Keypoints detector) (0) | 2020.11.04 |
| OpenCV - 25. 이미지 매칭 (평균 해시 매칭, 템플릿 매칭) (4) | 2020.10.27 |



