
귀퉁이 서재
캐글 필사 - 4. Porto Seguro Safe Driver Prediction 본문

Porto Seguro는 브라질의 자동차 보험 회사입니다. 본 경진 대회의 목적은 어떤 차주가 내년에 보험 청구를 할 확률을 예측하는 겁니다.
데이터는 59만 개의 훈련 데이터와 89만 개의 테스트 데이터로 구성되어 있습니다. 테스트 데이터가 훈련 데이터보다 많습니다. 그리고 Null 값이 np.NaN이 아닌 -1로 되어있습니다. 또한, Feature가 무엇을 뜻하는지 제시하지 않았다는 것이 특징입니다. 보통은 특정 Feature가 무엇을 나타내는지 알려줍니다. 예를 들어 집 값을 예측하는 데이터에서 Feature 중 방 크기(Area)가 있습니다. 방 크기가 크면 집 값이 올라갈 것이라는 예상을 해볼 수 있습니다. 하지만 Porto Seguro 컴피티션에는 각 Feature가 무엇을 의미하는지 알 수 없습니다. 데이터를 안내한 부분에도 나와있지 않고, Feature의 이름으로 유추하기도 어렵습니다. 다만, Feature가 binary인지, categorical인지, oridnal인지, nominal인지만 구분할 수 있을 뿐입니다. 보안상 공개를 하지 않는 것 같습니다.
target은 보험 청구를 한다(=1), 보험 청구를 하지 않는다(=0)인 binary 데이터입니다. 0과 1로 구성되어 있으며 0이 1보다 압도적으로 많습니다.
아래 3명의 Top Ranker들의 커널을 필사하며 공부했습니다. 여러 커널을 필사하며 공부하는 것의 장점은 하나의 문제를 다양한 각도에서 해석할 수 있다는 점입니다.
1. Data Preparation & Exploration
Bert Carremans 커널로 EDA, Feature Engineering(Dummification, Interaction), Feature Selection(Zero and Low Variance 제거, SelectFromModel) 등을 했습니다.
Meta Data
본 커널의 특징은 데이터 관리를 위해 Meta Data를 만들어 활용했다는 점입니다. 각 feature들의 특징을 담은 Meta Data를 만들어 필요할 때마다 사용하는 것입니다. 어떤 조건의 feature만 사용하고 싶을 때 그때마다 코드를 작성하기 번거롭습니다. 편리성을 위해 Meta Data를 미리 만들어 놓고 간단한 코드로 원하는 feature를 가져올 수 있습니다. 본 경진대회에서 Meta Data를 구하는 코드는 아래와 같습니다. 다른 경진대회에서도 아래 코드만 일부 수정하면 충분히 응용할 수 있습니다.
data = []
for f in train.columns:
# Defining the role
if f == 'target':
role = 'target'
elif f == 'id':
role = 'id'
else:
role = 'input'
# Defining the level
if 'bin' in f or f == 'target':
level = 'binary'
elif 'cat' in f or f == 'id':
level = 'nominal'
elif train[f].dtype == 'float64':
level = 'interval'
elif train[f].dtype == 'int64':
level = 'ordinal'
# Initialize keep to True for all variables except for id
keep = True
if f == 'id':
keep = False
# Defining the data type
dtype = train[f].dtype
# Creating a Dict that contains all the metadata for the variable
f_dict = {
'varname': f,
'role': role,
'level': level,
'keep': keep,
'dtype': dtype
}
data.append(f_dict)
meta = pd.DataFrame(data, columns=['varname', 'role', 'level', 'keep', 'dtype'])
meta.set_index('varname', inplace=True)우선, 데이터의 role을 정합니다. target 값은 target, id값은 id 그리고 나머지 예측을 위한 feature들은 input이라는 role로 정했습니다. Feature들의 type에 따라 level을 binary(이진형), nominal(명목형), interval(연속형), oridnal(순서형)로 정했습니다. 또한 데이터를 활용할 것이냐 아니냐에 따라 keep을 True or False로 정해놓습니다. 추후 활용할 때는 아래와 같이 합니다.
# nominal 타입을 불러올 때
meta.loc[(meta.level == 'nominal') & (meta.keep)].indexHandling imbalanced classes
앞서 말씀드렸다시피 본 경진대회의 target 값은 보험청구를 할지 말지입니다. 보험 청구를 하는 경우는 1, 하지 않는 경우는 0으로 구성되어 있습니다. 훈련데이터든 테스트 데이터든 0이 1보다 압도적으로 많습니다. 사실 0이 1보다 압도적으로 많으면 모든 target 값을 0으로 예측해도 정확도가 높습니다. 그렇겠죠? 그런데 이는 아무런 가치가 없는 예측입니다. 우리가 원하는 건 1을 얼마나 잘 예측하는가입니다. 보험 청구를 하는 사람들을 잘 예측해야 그에 대한 대책을 세울 수 있기 때문입니다.
이렇게 데이터가 불균형할 때는 두가지 방법으로 해결할 수 있습니다.
1. target=1인 데이터를 오버샘플링하여 훈련
2. target=0인 데이터를 언더샘플링하여 훈련
본 커널에서는 데이터 사이즈가 아주 크므로 2번째 방법을 택했습니다.
2. Interactive Porto Insights
Anisotropic의 커널로 [Plot.ly](https://plot.ly/)에 대해 배울 수 있습니다. Plot.ly는 정적인 일반 Plot과 대조되게 동적입니다. 마우스 커서를 움직임에 따라 variable 이름을 보여주며, 드래그를 하면 해당 부분을 확대시켜 줍니다.
정수형 Feature/실수형 Feature의 상관계수, 이진 Feature의 0과 1 분포, Feature importance 등을 동적인 Plot.ly로 그렸습니다. 이 커널을 통해 Plot.ly에 대해 새롭게 배웠습니다. 그래프라 하면 응당 matplotlib이나 seaborn만 사용했었는데 보다 동적인 그래프에 대해 알게 된 것이죠.
결측 데이터 시각화
missingno라는 라이브러리를 활용해 결측 데이터를 시각화한 부분도 새로웠습니다.
import missingno as msno
train_copy = train
train_copy = train_copy.replace(-1, np.NaN)
# Nullity or missing values by columns
msno.matrix(df=train_copy.iloc[:, 2:39], figsize=(15,10), color=(0.42, 0.1, 0.05))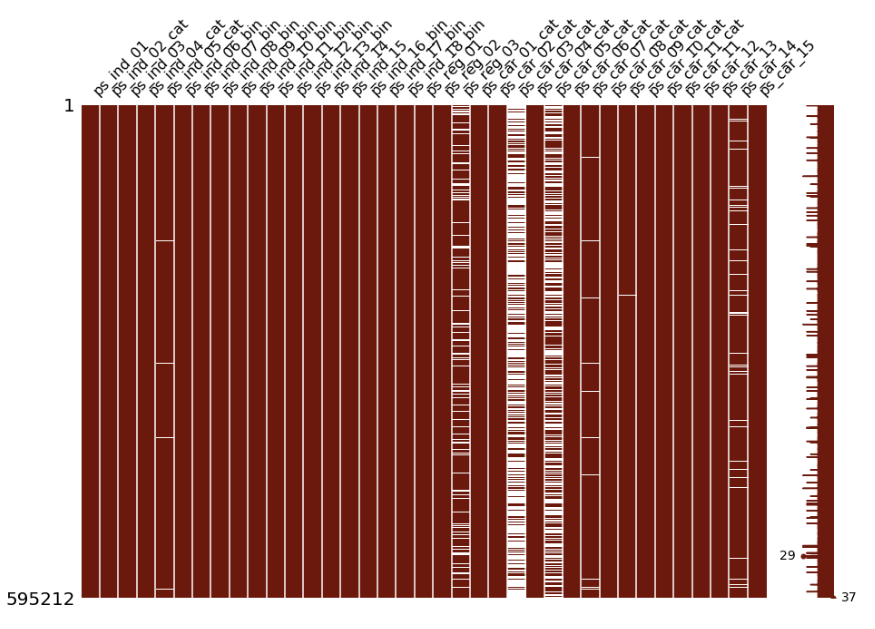
Null 값이 -1이라고 했으므로 이를 np.NaN으로 바꿨습니다. 그리고 missingno라는 라이브러리를 활용하여 결측치를 시각화했습니다. 흰색 부분이 np.NaN입니다. 즉, 데이터가 비어있는 부분입니다. 이렇게 결측치를 시각화하면 어떤 feature가 어떤 양식으로 비어있는지 확인할 수 있습니다.
3. EDA and Prediction
Gabriel Preda의 커널입니다. 첫 번째 커널과 마찬가지로 Meta-data를 활용했습니다. 데이터 타입별로 세부적으로 EDA를 했다는 특징이 있습니다. 각 타입별로 어떤 특징이 있는지 살펴볼 수 있습니다.
성능 향상을 위해 calc 타입의 feature를 drop 했고, 결측치가 많은 feature도 drop 했습니다. ps_car_11_cat feature는 target 인코딩을 했습니다. 또한, 첫 번째 커널과 마찬가지로 target = 0인 데이터를 언더 샘플링하는 방법을 취했습니다.
추가적으로 categorical feature는 Dummificiation하여 인코딩을 했으며, 필요 없는 feature는 drop을 했습니다.
가장 중요한 모델 부분은 LGBMClassifier와 XGBClassfier를 LogisticRegression으로 Stacking 했습니다.
본 커널은 전반적으로 첫번째 커널과 비슷하지만 Stacking을 사용했다는 점이 특이점입니다.
제 깃헙은 https://github.com/BaekKyunShin/Kaggle/tree/master/Porto_Seguro's_Safe_Driver_Prediction입니다.
'캐글 (Kaggle)' 카테고리의 다른 글
| 캐글 필사 - 6. Costa Rican Household Poverty Level Prediction (0) | 2020.01.25 |
|---|---|
| 캐글 필사 - 5. Home Credit Default Risk (0) | 2020.01.05 |
| 캐글 필사 - 3. San Francisco Crime Classification (0) | 2019.10.17 |
| 캐글 필사 - 2. Predict Future Sales (0) | 2019.10.06 |
| 캐글 필사 - 1. Bike Sharing Demand (0) | 2019.09.28 |



