
귀퉁이 서재
머신러닝 - 17. 회귀 평가 지표 본문

회귀의 평가를 위한 지표는 실제 값과 회귀 예측값의 차이를 기반으로 합니다. 회귀 평가지표 MAE, MSE, RMSE, MSLE, RMSLE는 값이 작을수록 회귀 성능이 좋은 것입니다. 값이 작을수록 예측값과 실제값의 차이가 없다는 뜻이기 때문입니다. 반면, R² 는 값이 클수록 성능이 좋습니다.
각 회귀 평가지표 별 구하는 공식은 아래와 같습니다. 캐글 회귀 문제에서도 아래의 평가 지표가 자주 사용됩니다.
MAE (Mean Absolue Error)
실제 값과 예측 값의 차이를 절댓값으로 변환해 평균한 것
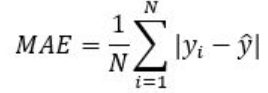
MSE (Mean Squared Error)
실제 값과 예측 값의 차이를 제곱해 평균한 것

RMSE (Root Mean Squared Error)
MSE 값은 오류의 제곱을 구하므로 실제 오류 평균보다 더 커지는 특성이 있어 MSE에 루트를 씌운 RMSE 값을 쓰는 것입니다.

MSLE (Mean Squared Log Error)
MSE에 로그를 적용해준 지표입니다. log(y)가 아니라 log(y+1)입니다. y=0일 때, log(y)는 마이너스 무한대이므로 이를 보정해주기 위해 +1을 한 것입니다.

RMSLE (Root Mean Squared Log Error)
RMSE에 로그를 적용해준 지표입니다.

R² (R Sqaure)
R² 는 분산 기반으로 예측 성능을 평가합니다. 1에 가까울수록 예측 정확도가 높습니다.
R² = 예측값 Variance / 실제값 Variance
RMSE와 비교해서 RMSLE가 가진 장점
1. 아웃라이어에 강건해진다.
RMSLE는 아웃라이어에 강건(Robust)합니다. 예를 들어보겠습니다.
예측값 = 67, 78, 91, 실제값 = 60, 80, 90일 때, RMSE = 4.242, RMSLE = 0.6466입니다.
예측값 = 67, 78, 91, 102, 실제값 = 60, 80, 90, 750일 때 RMSE = 374.724, RMSLE = 1.160입니다. 750이라는 아웃라이어 때문에 RMSE는 굉장히 증가했지만 RMSLE의 증가는 미미합니다. RMSLE는 아웃라이어가 있더라도 값의 변동폭이 크지 않습니다. 따라서 RMSLE는 아웃라이어에 강건하다고 말할 수 있습니다.
2. 상대적 Error를 측정해준다.
예측값과 실제값에 로그를 취해주면 로그 공식에 의해 아래와 같이 상대적 비율을 구할 수 있습니다.
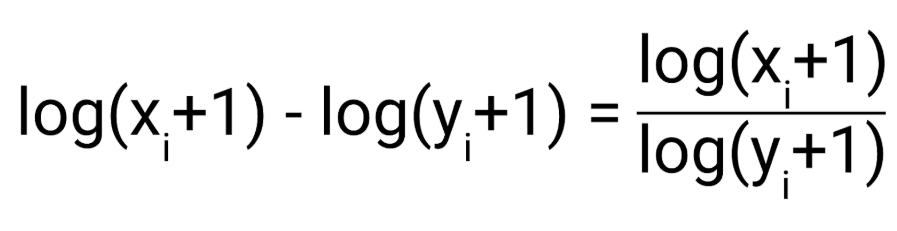
예측값 = 100, 실제값 = 90일 때, RMSLE = 0.1053, RMSE = 10입니다.
예측값 = 10,000, 실제값 = 9,000일 때, RMSLE = 0.1053, RMSE = 1,000입니다.
보시는 바와 같이 값의 절대적 크기가 변하더라도 상대적 크기가 동일하다면 RMSLE 값도 동일합니다. 반면, 상대적 크기가 동일하더라도 절대적 크기가 변하면 RMSE 값은 변합니다. 따라서 RMSE와 달리 RMSLE는 예측값과 실제값의 상대적 Error를 측정해줍니다.
3. Under Estimation에 큰 패널티를 부여한다.
RMSLE는 Over Estimation보다 Under Estimation에 더 큰 패널티를 부여합니다. 즉, 예측값이 실제값보다 클 때보다 예측값이 실제값보다 작을 때 더 큰 패널티를 부여합니다.
예측값 = 600, 실제값 = 1,000일 때 RMSE = 400, RMSLE = 0.510입니다.
예측값 = 1,400, 실제값 = 1,000일 때 RMSE = 400, RMSLE = 0.33입니다.
예측값과 실제값의 차이는 둘 다 400입니다. Over Estimation이든 Under Estimation이든 RMSE값은 동일합니다. 하지만 RMSLE는 Under Estimation일 때 (즉, 예측값이 실제값보다 작을 때) 더 높은 페널티가 주어집니다. 배달 음식을 시킬 때 30분이 걸린다고 했는데 실제로 20분이 걸리는 건 큰 문제가 되지 않지만, 30분이 걸린다고 했는데 40분이 걸리면 고객이 화가 날 수 있습니다. 이럴 때 RMSLE를 적용할 수 있습니다.
Python 예제
각 회귀 평가 지표는 sklearn을 통해 간단히 구현할 수 있습니다. MSLE, RMSLE를 사용할 때는 예측값이나 실제값에 음수가 있으면 오류가 날 수 있으니 주의하시기 바랍니다.
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error, mean_squared_log_error
origin = np.array([1, 2, 3, 2, 3, 5, 4, 6, 5, 6, 7])
pred = np.array([1, 1, 2, 2, 3, 4, 4, 5, 5, 7, 7])
MAE = mean_absolute_error(origin, pred)
# MAE = 0.45454545454545453
MSE = mean_squared_error(origin, pred)
# MSE = 0.45454545454545453
RMSE = np.sqrt(MSE)
# RMSE = 0.674199862463242
MSLE = mean_squared_log_error(origin, pred)
# MSLE = 0.029272467607503516
RMSLE = np.sqrt(mean_squared_log_error(origin, pred))
# RMSLE = 0.1710919858073531
R2 = r2_score(origin, pred)
# R2 = 0.868421052631579
References
Reference1: 파이썬 머신러닝 완벽가이드 (권철민 저)
Reference2: Medium (What's the difference between RMSE and RMSLE?)
'머신러닝' 카테고리의 다른 글
| 머신러닝 - 19. 고유값(eigenvalue), 고유벡터(eigenvector), 고유값 분해(eigen decomposition) (2) | 2020.02.24 |
|---|---|
| 머신러닝 - 18. 선형판별분석(LDA) (0) | 2020.01.01 |
| 머신러닝 - 16. NGBoost (16) | 2019.11.01 |
| 머신러닝 - 15. 그레디언트 부스트(Gradient Boost) (40) | 2019.10.23 |
| 머신러닝 - 14. 에이다 부스트(AdaBoost) (19) | 2019.10.04 |



