
귀퉁이 서재
논문 리뷰 - 캐스케이드 검출기 (Cascade Detector) 톺아보기 본문

캐스케이드 검출기는 물체(특히 얼굴)를 탐지하는 데 사용하는 검출기입니다. 통합 이미지(integral image), AdaBoost를 활용한 피처 선택, 캐스케이드 구조를 사용한다는 특징이 있는 검출기죠. 캐스케이드 검출기에 관한 논문은 CVPR(Computer Vision and Pattern Recognition) 2001에서 발표되었습니다. 캐스케이드 검출기 논문을 번역/설명해 봤습니다. 논문에 나온 글을 번역하면서 추가로 필요한 설명도 상세하게 덧붙였고요. 틀린 내용이 있으면 피드백 부탁드립니다(퇴고를 하지 않아 문장이 매끄럽진 않을 수도 있습니다).
- 논문 제목: Rapid Object Detection using a Boosted Cascade of Simple Features
- 저자: Paul Viola, Michael Jones
- 발표: 2001년
Abstract
이 논문에서는 이미지를 빠르고 정확하게 처리하는 객체 검출기(객체 탐지기)를 소개합니다. 머신러닝 방식으로 접근하는 객체 검출기죠. 이 객체 검출기는 세 가지 주요 특징이 있습니다. 첫 번째 특징은 '통합 이미지(Integral Image)'라는 새로운 이미지 표현법을 사용한다는 점입니다. 통합 이미지 덕분에 검출기에서 사용하는 피처(특징, features)를 빠르게 계산할 수 있습니다. 두 번째는 AdaBoost 기반의 훈련 알고리즘을 사용한다는 점입니다. AdaBoost를 활용해 수많은 피처 가운데 객체 검출에 필요한 몇 가지 중요 피처만 선택할 수 있습니다. 그만큼 효율적인 분류기가 되는 것이죠. 세 번째 특징은 '캐스케이드' 구조를 통해 여러 분류기를 결합한다는 것입니다. 결합 구조를 활용해 관심 영역에 더 집중하고, 관심 없는 영역은 바로 버릴 수 있습니다. 실시간 애플리케이션에서는 초당 15 프레임의 속도를 나타냅니다.
1. Introduction
이 논문에서는 강건하면서 빠른 객체 검출 프레임워크를 만들기 위해 새로운 알고리즘과 인사이트를 활용했습니다. 이 프레임워크로 얼굴을 검출하는 작업을 수행했죠. 이전에도 여러 가지 얼굴 감지 시스템이 있었습니다. 그러나 우리가 만든 얼굴 감지 시스템은 얼굴을 매우 빠르게 검출할 수 있습니다. 이전의 시스템과 명확하게 다른 점이죠. 기존 700 MHz Intel Pentium III에서 384 x 288 픽셀 이미지로 테스트했을 때 초당 15 프레임의 속도로 얼굴을 검출했습니다. 흑백 이미지만을 활용해 높은 프레임률을 보입니다.
본 논문에서 제안한 객체 검출 프레임워크에는 세 가지 주요 특징이 있습니다. 먼저 간단하게 소개한 후, 뒤에서 자세히 설명하겠습니다.
Introduction은 전체 논문을 요약하는 부분이라 아래 세 가지 내용이 이해 안 갈 수 있습니다. 바로 섹션2부터 보셔도 좋습니다.
첫 번째 특징은 통합 이미지(integral image)라고 부르는 새로운 이미지 표현 방식을 사용한다는 점입니다. 통합 이미지 덕분에 피처(feature) 계산을 빠르게 할 수 있습니다. 객체 검출 시 우리는 Haar 피처를 사용합니다(Haar 필터보다 더 복잡한 관련 필터도 사용할 것입니다). Haar 피처를 다양한 스케일에 대해 빠르게 계산하기 위해 통합 이미지 표현(integral image representation)을 사용했습니다. 통합 이미지는 픽셀마다 몇 가지 연산만으로도 간단히 계산할 수 있습니다. 이미지 크기에 관계없이 고정된 시간(시간 복잡도 = O(1)) 내에 계산이 된다는 말입니다.
두 번째 특징은 AdaBoost를 사용하여 소수의 중요한 피처를 선택한다는 점입니다. 통합 이미지로 계산한 Haar 피처는 굉장히 많습니다. 모든 스케일마다, 모든 픽셀마다, 모든 필터마다 계산을 해기 때문이죠. 하지만 모든 Haar 피처가 객체를 검출하는 데 중요한 역할을 하진 않습니다. 그래서 수많은 피처 가운데 중요한 피처만을 선택해야 하는 게 효율적입니다. 이러한 피처 선택 작업은 AdaBoost 프로세스를 약간만 수정해서 할 수 있습니다. 여기서 사용한 AdaBoost 프로세스를 간단히 설명하면 이렇습니다. 약한 분류기가 단일 피처에만 의존할 수 있도록 제한합니다. 결과적으로 새로운 약한 분류기를 선택하는 부스팅 프로세스의 각 단계를 피처 선택 프로세스로 볼 수 있죠.
본 논문에서 제안한 객체 검출 프레임워크의 세 번째 특징은 캐스케이드 구조를 사용한다는 점입니다. 검출 속도를 빠르게 하기 위해서 사용하지요. 이미지 내 중요한 영역에 집중하면서 캐스케이드 구조에서 연속해서 더 복잡한 분류기를 결합하는 방법입니다. 이러한 구조를 활용해 이미지 안에서 찾으려는 물체가 어디 있는지 빠르게 찾을 수 있습니다. 캐스케이드 구조에서 뒤로 갈수록 더 복잡한 분류기로 이미지를 처리하는데, 중요한 영역에만 더 집중해서 처리를 하기 때문에 속도가 빠른 겁니다.
2. Features
본 논문이 제시한 객체 검출기는 간단한 피처 값을 바탕으로 이미지를 분류합니다.
여기서 피처란 Haar 피처를 말하며, Haar 피처란 Haar 필터를 통해 추출된 피처를 뜻합니다. Haar 필터가 무엇인지는 바로 다음에 설명합니다.
픽셀을 직접 사용하지 않고 피처를 사용하는 까닭은 많습니다. 가장 일반적인 이유는 피처가 이미지 픽셀을 인코딩하는 역할을 하기 때문입니다. 두 번째 이유는 피처 기반 검출 시스템은 픽셀 기반 시스템보다 훨씬 빠르기 때문입니다.
기본적으로 Haar 필터를 사용해서 피처를 추출합니다. Haar 필터는 다음과 같습니다.

위 그림은 네 가지 Haar 필터의 예시입니다. Haar 필터로 이미지 전체를 훑으며 피처 값을 추출합니다. Haar 필터의 흰색 영역에 있는 모든 픽셀 값의 합에서 검정 색 영역에 있는 모든 픽셀 값의 합을 빼면 Haar 피처 값을 구할 수 있습니다. (A)는 왼쪽이 흰색, 오른쪽이 검은색인 사각형으로 구성된 Haar 필터입니다. (B)는 위아래로 구성된 필터이며, (C)는 가운데만 검은색인 필터, (D)는 대각선으로 이루어진 필터입니다. 이러한 필터를 활용해서 이미지 내에서 특징을 추출하는 것입니다.
(A) haar 필터를 사용해 피처 값을 구한 예시를 볼까요?
맨 처음 얼굴에서 필터의 흰색 영역에 있는 모든 픽셀 값의 합에서 검은색 영역에 있는 모든 픽셀 값의 합을 빼면 64가 나옵니다. 곧, 흰색 영역의 픽셀 값이 좀 더 밝다는 뜻입니다. 밝을수록 픽셀 값이 큽니다. 255는 흰색, 0은 검은색이니까요. 오른쪽 위 그림을 봅시다. 흰색 영역과 검은색 영역의 차이는 없습니다. 그래서 필터를 통해 구한 피처 값이 0이 됩니다. 해당 필터로 이미지에서 어떠한 특징도 찾지 못했다는 뜻이죠. 마지막 강아지 이미지를 보죠. 필터로 구한 피처 값이 -127로 음수입니다. 다시 말해 검은색 영역의 픽셀 값 합이 더 크다는 말입니다. 검은색 영역이 하얀 강아지를 많이 포함하므로 픽셀 값이 더 크겠죠.
네 가지 Haar 필터를 여러 방향, 여러 스케일로 조정해서 사용할 수 있습니다. 다음과 같이 말입니다.
위 그림에서 (a) 필터는 좌우 방향으로 특징을 추출합니다. (b) 필터는 위아래 방향의 특징을 추출하고, (c)는 대각선 방향의 특징을 추출합니다. (d)는 가운데 영역의 특징을 추출하죠. 이렇듯 다양한 필터를 사용해서 객체의 경계를 찾아준다고 보면 됩니다.
본 논문에서는 24x24 해상도인 이미지를 사용하는데, 이때 필터를 활용해 구한 피처 세트가 180,000개 이상이 나왔다고 합니다. 상당히 개수가 많습니다.
2.1. Integral Image
앞서 설명한 필터를 통해 피처 값을 계산하려면 상당히 많은 계산을 해야 합니다. 필터의 사각형 영역에 포함된 모든 픽셀 값을 다 합해야 하기 때문이죠.
필터 크기가 NxM이라고 합시다. 필터 하나로 하나의 피처 값을 구하려면 (NxM -1) 번 덧셈을 해야 합니다. 2 + 1 = 3에서 알 수 있듯, 값이 두 개면 덧셈을 한 번 해야 합니다. 픽셀 값이 NxM 개이므로 총 (NxM - 1) 번 덧셈을 해야 합니다(더 정확하게는 (NxM -2)번 덧셈하고 1번 뺄셈하는 겁니다). (NxM - 1) 자체의 연산 횟수는 그리 많지 않습니다. 하지만 각 픽셀당, 필터당, 스케일당 모든 계산을 하려면 연산 비용이 상당히 높아지죠. 이를 개선하는 방법이 통합 이미지(integral image)입니다. 다음은 통합 이미지의 예시입니다.
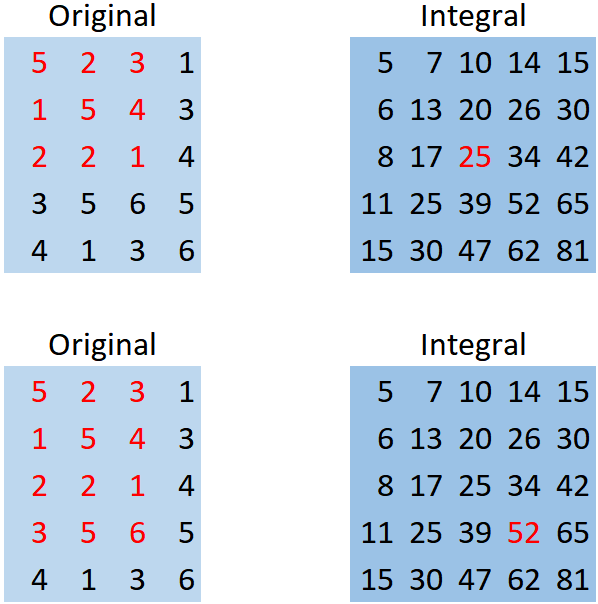
왼쪽이 원본 이미지의 모든 픽셀 값을 뜻합니다. 오른쪽은 간단한 계산으로 구한 통합 이미지의 픽셀 값입니다. 통합 이미지를 구하는 방법은 간단합니다. 왼쪽 상단을 1행 1열이라고 하겠습니다. 첫 번째 원본 이미지에서 1행 1열부터 3행 3열까지 모든 픽셀 값을 합하면 25가 됩니다(5 + 2 + 3 + 1 + 5 + 4 + 2 + 2 + 1 = 25). 그러면 통합 이미지의 3행 3열에 25를 계산해 넣습니다. 마찬가지로 두 번째 그림을 보죠. 1행 1열부터 4행 3열까지 모든 픽셀 값의 합은 52입니다. 그러면 통합 이미지의 4행 3열에도 52를 기재합니다.
이런 식으로 통합 이미지를 만들어서 사용하면, 앞서 Haar 필터로 피처 값을 구할 때 여러 번 덧셈을 할 필요가 없습니다. 이미 덧셈이 완료된 값이 통합 이미지에 저장되어 있기 때문이죠. 다음 그림을 보죠.
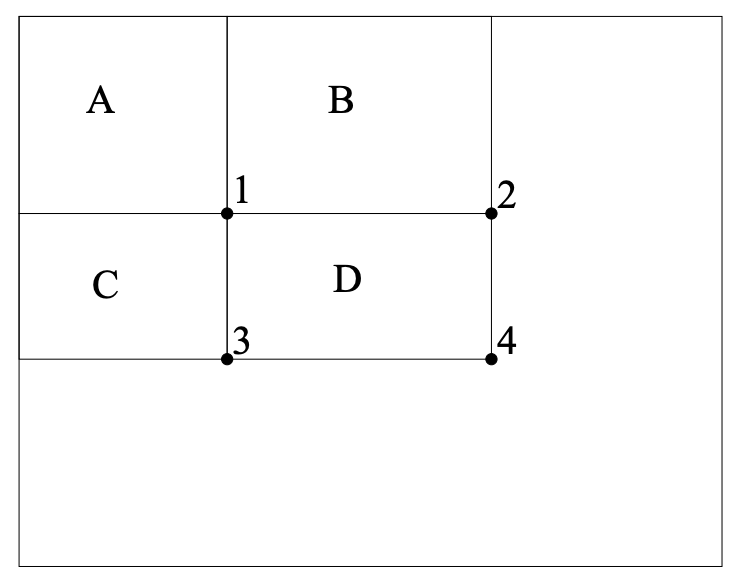
D 영역에 해당하는 필터를 통해 피처 값을 구한다고 해봅시다. D 필터 크기가 (NxM)이면 (NxM - 1) 번 연산을 해야 한다고 했죠? 그런데 아래 이미지가 원본 이미지가 아니라 통합 이미지면 연산 횟수가 확 줄어듭니다.
location 4 - location 2 - location 3 + location 1을 하면 됩니다. 딱 3번만 연산을 하면 되죠. 다음은 이렇게 연산을 하는 예시입니다.
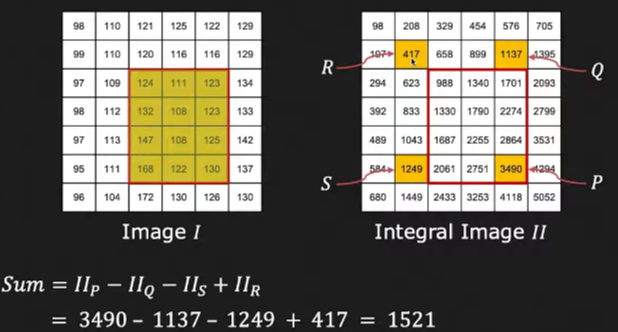
그런데 우리는 흰색 영역, 검정 색 영역을 포함하는 필터를 사용하죠? 그러면 연산을 딱 7번만 하면 됩니다.

통합 이미지를 사용하지 않으면 필터 크기가 클수록 연산 횟수가 많아졌습니다. 그런데 통합 이미지를 사용하니 필터 크기와 관계없이 단 7번의 연산으로 피처 값을 구할 수 있죠. 당연한 얘기지만 아래와 같은 Haar 필터를 사용하면 연산 횟수가 7번보다는 더 늘어나겠죠?
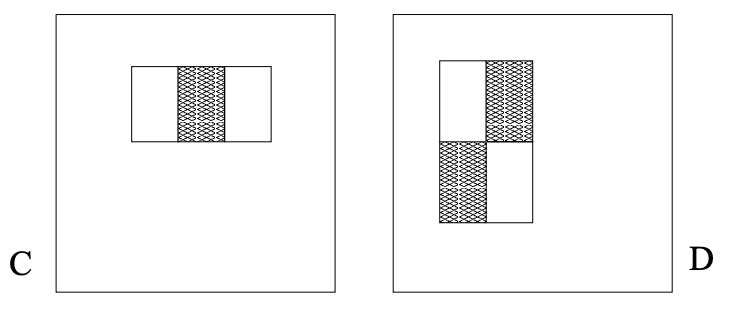
2.2 Feature Discussion
지금까지 직사각형으로 구성된 필터를 살펴봤습니다. 직사각형 형태의 필터는 수직, 수평, 대각선 방향의 경계면들만 감지할 수 있습니다. 유연하게 조작이 가능한 필터를 사용하면 상세 분석이나 텍스처 분석도 가능하겠죠. 그러나 직사각형 형태의 필터는 통합 이미지와 함께 사용되어 계산 효율성이 높습니다. 유연성은 떨어지지만 효율성이 높기 때문에 직사각형 필터로도 충분합니다.
3. Learning Classification Functions
본 논문에서는 피처를 선택하고 분류기(classifier)를 훈련하기 위해 변형된 AdaBoost를 사용합니다.
AdaBoost의 상세한 알고리즘이 궁금한 분은 머신러닝 - 14. 에이다 부스트(AdaBoost)를 참고해주세요.
원래 AdaBoost 알고리즘은 약한 분류기의 성능을 향상하는 데 사용됩니다. Freund와 Schapire는 라운드 수가 거듭될수록 분류기의 오류 급격하게 0에 수렴한다는 점을 증명했습니다. 나중에는 여러 결과를 통해 일반화 성능도 좋다는 사실이 입증됐습니다.
앞서 다양한 Haar 필터를 활용해 피처를 추출했다고 했죠? 한 이미지당 피처는 180,000개 이상이라고 했습니다. 픽셀 수보다 훨씬 많죠. 통합 이미지를 사용해 각 피처 하나는 빠르게 계산할 수 있지만, 전체 피처를 모두 계산하려면 시간이 상당히 오래 걸립니다. 수많은 피처 중 소수의 피처만이 객체를 검출하는 데 중요한 역할을 합니다. 실험으로 입증된 사실이죠. 중요한 피처를 어떻게 찾는지가 문제입니다.
이 문제를 해결하기 위해 약한 분류기는 positive 객체와 negative 객체를 가장 잘 구분하는 단일 피처를 선택하도록 설계됐습니다.
positive는 우리가 검출하려는 객체, negative 객체는 관심 없는 객체나 배경을 뜻합니다.
각 피처에 대해 약한 분류기는 잘못 분류되는 샘플이 적도록 최적 임계값을 구합니다.
3.1. Learning Discussion
이외에도 여러 피처 선택 방법이 있습니다. 본 논문에서는 피처 대부분을 버리는 공격적인 방식을 채택했죠. Papageorgiou는 피처 분산에 기초한 피처 선택 방법을 제안했습니다. 피처 1,734개 가운데 37개를 선택해 우수한 객체 검출 성능을 보여주었습니다. Roth는 Winnow 지수 퍼셉트론 학습 규칙에 기초한 피처 선택 방법을 제안했습니다.
3.2. Learning Results
최종 시스템의 훈련이나 성능을 설명하는 자세한 내용은 섹션 5에서 다루겠지만, 결과를 먼저 공유하겠습니다. 얼굴 감지 작업의 경우 AdaBoost가 선택한 직사각형 필터가 유의미하고, 필터의 역할을 해석하기도 쉽습니다. 다음 그림을 보죠.

두 가지 필터는 AdaBoost에 의해 선택된 것입니다. 눈과 볼의 경계를 검출하는 데 첫 번째 필터를 사용할 수 있습니다. 눈 부분은 눈동자 때문에 대체로 어둡고, 눈 아래로는 볼이 있어서 밝습니다. 따라서 첫 번째 필터는 눈과 볼 경계를 검출하는 데 중요한 역할을 하죠. 두 번째 필터는 눈 사이를 검출하는 데 사용됩니다. 두 눈은 어두운데, 미간은 밝기 때문이죠.
4. The Attentional Cascade
이 섹션에서는 계산 시간을 더 줄이면서 검출 성능을 높이게끔 분류기를 구성하는 방식을 설명합니다. 이 방식은 여러 분류기를 직렬로 연결하는 것입니다. 그래서 이름이 캐스케이드(cascade)입니다. 앞단에 있는 단순한 분류기는 negative example 상당수를 버립니다. 단순한 분류기라서 계산 비용도 크지 않죠. 이렇게 초반에 negative example들을 버려주니 굳이 뒤이어서 복잡한 분류기가 그 example을 다시 처리할 필요가 없습니다.
얼굴을 검출하는 문제를 생각해 보죠. 초반에 단순한 분류기로 활용해 전혀 얼굴이 아닌 이미지를 바로 버립니다. 약간 얼굴과 비슷한 건 첫 번째 분류기를 통과합니다. 그럼 두 번째 분류기가 조금 더 복잡한 연산을 해서 얼굴인지 아닌지 구분합니다. 이렇듯 앞쪽에 있는 분류기는 계산 비용이 작지만 분류 성능이 좋지는 않고, 뒤쪽에 있는 분류기는 계산 비용은 큰데 분류 성능이 좋다고 보면 됩니다. 그래서 아예 싹이 아닌 걸 초반에 미리 제외해서 계산 시간을 빠르게 하는 원리입니다.
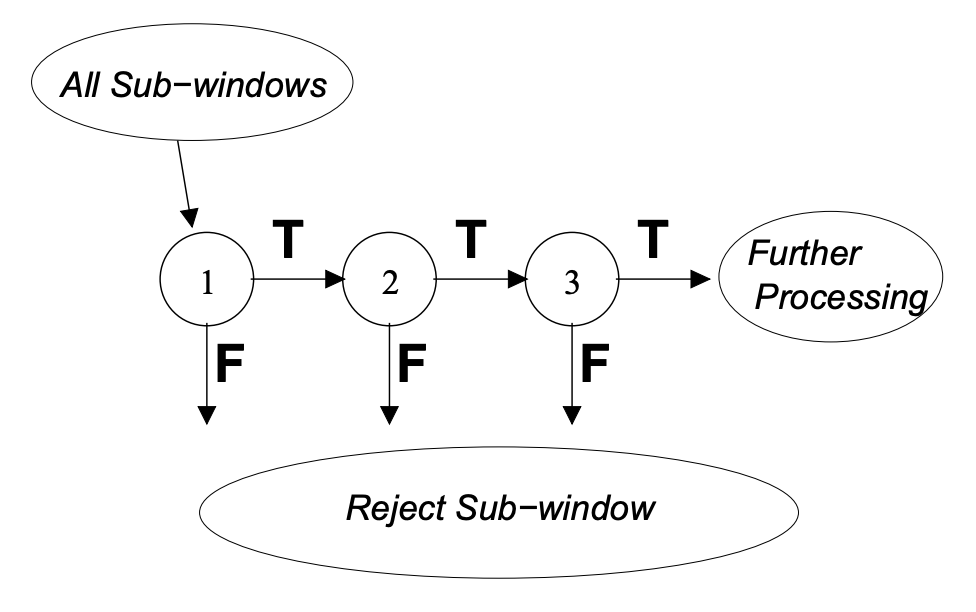
첫 번째 분류기에서 positive로 평가한 결과는 두 번째 분류기로 전달됩니다. 두 번째 분류기가 positive로 평가한 것은 세 번째 분류기로 전달됩니다. 어느 시점에서든 negative 결과가 있다면 즉시 제외시킵니다. 다음 분류기로 보내지 않는다는 말입니다. 의사 결정 트리와 마찬가지로, 후속 분류기는 이전 모든 단계를 통과하는 example을 사용해 훈련합니다. 결과적으로 두 번째 분류기가 첫 번째 분류기보다 더 어려운 작업을 합니다. 이러한 캐스케이드 구조 덕분에 가능한 한 많은 negative 결과를 가능한 한 빨리 제외할 수 있습니다. 그 결과 검출 속도가 빨라집니다.
4.1. Training a Cascade of Classifiers
캐스케이드 훈련 과정에는 트레이드오프(trade-off) 관계가 있습니다. 각 분류기마다 피처가 많으면 많을수록 성능이 좋습니다. 그렇지만 피처가 많으면 그만큼 시간이 오래 걸립니다. 캐스케이드 구조를 사용하면 각 분류기에는 피처가 적어지지만 그래서 시간이 빨라지는 것이고요. 그러면 얼마나 많은 피처를 제외할지가 문제입니다. (피처를 제외시키는) 임계값에 따라서 전체 분류기의 성능이 좋아질지 나빠질지, 시간이 오래 걸릴지 빨라질지가 결정되는 것이죠. 불행히도 최적점을 찾는 일은 굉장히 어려운 문제입니다. 목표로 하는 검출율과 false positive rate에 도달하도록 임계값을 정합니다.
5. Results
본 논문에서 사용한 얼굴 검출기는 38개의 단계로 캐스케이드를 구성합니다. 얼굴을 탐지하도록 이 검출기를 훈련했습니다. 검출기를 훈련하기 위해 얼굴 이미지와 얼굴이 아닌 이미지를 훈련 데이터로 사용했습니다. 얼굴 훈련 이미지는 4,916개이며, 해상도는 24x24 픽셀입니다. 인터넷에서 무작위로 다운로드한 이미지에서 추출한 얼굴들이죠. 다음은 훈련에 사용한 몇 가지 얼굴 이미지 예시입니다.

훈련에 사용한 얼굴이 없는 이미지(negative 이미지)는 9,544개입니다.
본 검출기의 처음 5개 레이어에 있는 필터 개수는 각각 1, 10, 25, 25, 50개입니다. 나머지 레이어에서는 점점 더 많은 필터를 가지고 있습니다. 모든 레이어의 총 필터 개수는 6,061개입니다.
Speed of the Final Detector
캐스케이드 검출기의 속도는 스캔한 sub-window당 평가되는 필터 개수와 직접적으로 관련이 있습니다. 실험 결과, sub-window마다 평균적으로 10개의 필터로 평가를 합니다. 전체 필터 개수가 6,061개인데 말이죠. 이 말은 sub-window 대부분이 첫 번째 혹은 두 번째 캐스케이드 레이어에서 제외된다는 뜻입니다. 700Mhz Pentium III 프로세서에서 얼굴 검출기는 384 x 288픽셀 이미지를 약 0.067초 만에 처리할 수 있습니다. Rowley Baluja-Kanade 검출기보다 약 15배 빠르고 Schneerman-Kanade 검출기보다 약 600배 빠릅니다.
Image Processing
훈련에 사용된 모든 sub-window에는 다양한 조명의 영향을 줄이려고 분산 정규화를 했습니다. 훈련을 할 때도 정규화를 했으니 검출 시에도 정규화를 해야 합니다. 정규화를 하려면 분산과 평균이 필요한데, 분산과 평균 역시 통합 이미지를 활용해 빠르게 구할 수 있답니다.
Scanning the Detector
최종 검출기는 여러 스케일과 위치에서 이미지 전체를 스캔합니다. 스케일링할 땐, 이미지 크기를 조정하는 대신 검출기 자체의 크기를 조정합니다. 1.25배의 비율로 스케일링해 좋은 결과를 얻었습니다. 또한 검출기의 window는 여러 위치에서 이미지를 스캔합니다. 한 지점에서 window를 스캔한 뒤, 다른 지점으로 이동할 때 몇 픽셀만큼 갈지를 결정해야겠죠. 스케일이 얼마나 큰지, 이동 단위를 얼마로 설정했는지에 따라 다릅니다. 얼마만큼 이동할지에 따라 정확도뿐만 아니라 검출기의 속도에도 영향을 미칩니다.
Integration of Multiple Detections
일반적으로 얼굴 주변에는 검출 결과가 여러 개 생깁니다. 실제로는 얼굴 하나당 최종 탐지 결과 하나만 반환하는 게 맞습니다. 중복 탐지 결과를 하나로 결합해야 한다는 말이죠. 중복 탐지 결과를 단일 탐지로 결합하기 위해 후처리를 해야 합니다.

6. Conclusions
본 논문에서는 빠르고 정확한 객체 검출 방식을 제안했습니다. 이 접근 방식은 기존 방식보다 약 15배 빠르게 얼굴을 검출합니다. 여기서 제시한 방식과 알고리즘은 컴퓨터 비전이나 이미지 처리 분야에서 광범위하게 적용될 수 있습니다. 게다가 본 논문에서 사용한 얼굴 이미지는 다양한 조건을 갖습니다. 조명, 크기, 포즈 및 카메라 변형을 포함하죠. 이렇게 복잡한 데이터로도 빠르고 좋은 성능을 냈습니다.
'논문 리뷰' 카테고리의 다른 글
| 논문 리뷰 - SSD(Single Shot MultiBox Detector) 톺아보기 (0) | 2022.03.30 |
|---|---|
| 논문 리뷰 - Faster R-CNN 톺아보기 (0) | 2022.03.17 |
| 논문 리뷰 - Fast R-CNN 톺아보기 (2) | 2022.03.09 |
| 논문 리뷰 - SPP-net 톺아보기 (0) | 2022.02.26 |
| 논문 리뷰 - R-CNN 톺아보기 (9) | 2022.02.02 |



