
귀퉁이 서재
논문 리뷰 - Faster R-CNN 톺아보기 본문

Faster R-CNN은 기존 Fast R-CNN에 영역 추정 네트워크(RPN)를 더해 속도와 성능을 끌어올린 모델입니다. Faster R-CNN에 와서야 비로소 모든 객체 탐지 구조를 딥러닝으로 훈련할 수 있었습니다. 본 글에서 주요 내용 위주로 Faster R-CNN 논문을 번역/정리했습니다. 글 중간에 <NOTE>로 부연 설명을 달아놓기도 했습니다. 틀린 내용이 있으면 피드백 부탁드립니다.
- 논문 제목: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- 저자: Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun
- 개정 발표: 2016년 1월 (첫 발표: 2015년 6월)
Abstract
최신 객체 탐지 모델은 객체 위치를 추정하기 위해 영역 추정(region proposal) 알고리즘을 사용해왔습니다. SPP-net과 Fast R-CNN은 객체 탐지 시간을 크게 줄인 모델이죠. 그렇지만 여전히 영역 추정 단계에서 병목(bottleneck) 현상이 생긴다는 단점이 있습니다. 본 논문에서는 영역 추정 네트워크(Region Proposal Network) 기법을 제안합니다. 줄여서 RPN이라고 합니다. RPN은 객체 탐지 네트워크와 함께 합성곱 피처들을 공유하기 때문에 영역 추정에 거의 비용이 들지 않습니다(cost-free). RPN은 객체의 경계 박스와 클래스 점수(객체가 있는지 없는지 여부를 점수화)를 동시에 예측하는 합성곱 네트워크입니다. 게다가, 품질 좋은 영역 추정 경계 박스를 생성하도록 end-to-end 훈련을 할 수 있습니다. 더욱이 RPN과 Fast R-CNN을 결합해 단일 네트워크(single network)를 만들었습니다. 합성곱 피처를 서로 공유하죠. 이는 어텐션(attention) 메커니즘과 비슷합니다.
<NOTE> 어텐션 메커니즘이 궁금한 분은 NLP - 14. 어텐션(Attention)을 참고해주세요.
Faster R-CNN은 GPU에서 깊은 VGG-16 모델을 사용해 5 fps(1초에 이미지 5 프레임 처리)를 달성했습니다. 그러면서 우수한 객체 탐지 성능을 보였습니다. 2015년에 열린 ILSVRC와 COCO 대회에서 Faster R-CNN과 RPN은 여러 분야에서 1등을 차지했습니다. 코드도 모두가 사용할 수 있도록 공유했습니다.
1. Introduction
영역 추정(region proposal) 기법과 R-CNN 덕분에 최근(논문이 쓰인 2015년) 객체 탐지 성능이 크게 좋아졌습니다. R-CNN은 속도가 느리지만, Fast R-CNN에서는 피처 맵을 공유한 덕분에 R-CNN의 단점을 많이 개선했죠. 하지만 Fast R-CNN도 여전히 영역 추정 단계에서는 병목 현상이 있습니다. 영역 추정 단계만 빼면 실시간 객체 탐지가 가능할 정도로 빠른데 말이죠.
선택적 탐색(selective search)은 CPU에서 이미지당 2초가 걸릴 정도로 꽤 느립니다. 이미 선택적 탐색만으로도 FPS가 1도 안되죠. 이후에 나온 EdgeBox를 활용하면 영역 추정 단계가 이미지당 0.2초가 걸리지만, 이마저도 여전히 느린 속도입니다.
Fast R-CNN은 기본적으로 GPU를 이용하지만, 영역 추정은 CPU에서 수행합니다. 그렇기 때문에 영역 추정 단계에서 병목 현상이 발생하죠. 영역 추정을 빠르게 하는 확실한 방법은 영역 추정을 GPU에서 수행하는 것입니다. 병목 현상을 해결할 효과적인 방안이 될 순 있습니다. 하지만 GPU로 영역 추정을 하도록 영역 추정 네트워크를 재설계하는 경우, 어떻게 피처 맵 계산 결과를 공유할지는 다시 고민해봐야 합니다.
본 논문에서는, 깊은 합성곱 신경망으로 영역 추정을 하도록 하는 알고리즘을 통해 영역 추정 계산 비용이 거의 들지 않게 했습니다. 객체 탐지 네트워크와 함께 합성곱 계층(피처 맵)을 공유하는 영역 추정 네트워크(Region Proposal Networks, RPN) 덕분에 말이죠. 테스트 단계에서 합성곱 계산 결과를 공유해 영역 추정 속도를 크게 개선하는 네트워크입니다(이미지당 10ms). 정말 많이 빨라졌죠.
Fast R-CNN과 같은 영역 기반 탐지기(region-based detectors)가 사용하는 합성곱 피처 맵은 영역 추정하는 데에도 사용될 수 있습니다. 이 피처 맵에 몇 가지 합성곱 계층만 더하면 RPN을 구축할 수 있죠. RPN은 객체의 대략적인 경계 박스를 찾아주고, 동시에 객체 존재 여부를 점수로 표현합니다. RPN은 완벽한 합성곱 네트워크이며, end-to-end 훈련이 가능합니다.
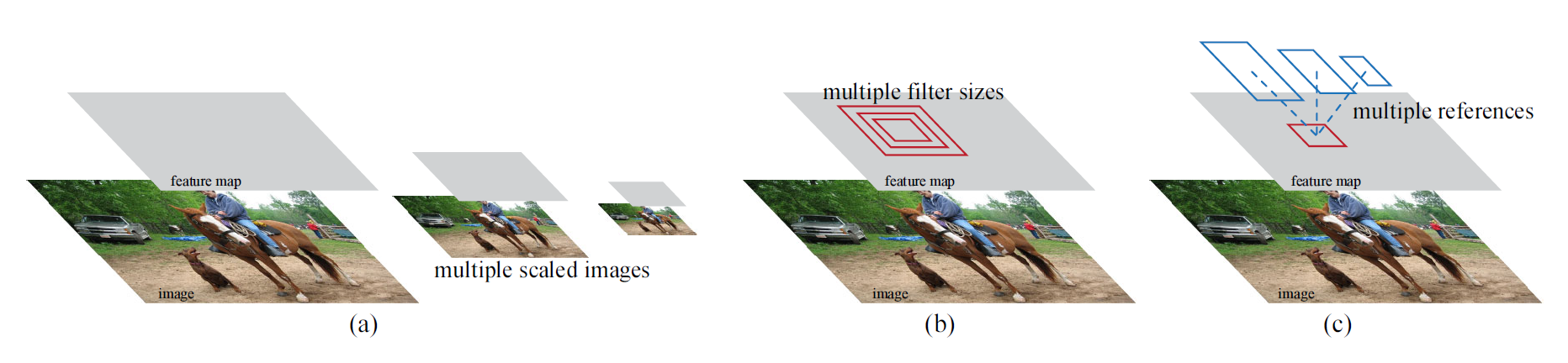
RPN은 다양한 스케일과 가로세로 비율을 갖는 영역 추정 경계 박스를 효과적으로 예측하도록 설계됐습니다. 이미지 피라미드(아래 그림에서 (a))나 필터 피라미드(아래 그림에서 (b)) 방식을 사용한 기존 모델과 다르게, Faster R-CNN은 앵커 박스(anchor boxes)를 사용합니다. 앵커 박스는 여러 스케일과 가로세로 비율을 갖습니다. 앵커 박스를 사용하면 다양한 스케일과 가로세로 비율을 갖는 이미지나 필터를 사용하지 않아도 되기 때문에, 다시 말해 단일 스케일 이미지만 사용해도 되기 때문에 속도가 빠릅니다.
RPN과 Fast R-CNN 객체 탐지 네트워크를 결합하기 위해, 영역 추정 파인 튜닝과 객체 탐지 파인 튜닝을 번갈아가며 수행합니다. 이런 훈련 방식 덕분에 영역 추정과 객체 탐지 작업끼리 합성곱 피처를 공유할 수 있고, 속도도 빨라집니다.
PASCAL VOC 데이터셋에서 실험해봤을 때, RPN을 적용한 Fast R-CNN이 선택적 탐색(selective search)을 적용한 Fast R-CNN보다 정확도가 높았습니다. RPN을 적용한 Fast R-CNN이 Faster R-CNN입니다. 한편, Faster R-CNN에서는 선택적 탐색에 걸리는 시간이 거의 없기 때문에 상당히 빠르게 작업을 수행할 수 있습니다. 굉장히 깊은 신경망을 사용해도 Faster R-CNN은 GPU에서 5 fps의 속도를 보입니다. 속도나 정확도 측면에서 실용적이죠.
Faster R-CNN과 RPN은 ILSVRC와 COCO 2015 대회의 이미지넷 객체 탐지, 이미지넷 localization, COCO 객체 탐지, COCO 세그멘테이션에서 1등을 차지했습니다. 이러한 결과로 미루어보아, Faster R-CNN과 RPN은 실용적으로 사용할 정도로 속도가 빠르고, 객체 탐지 정확도도 높은 모델입니다.
2. Related Work
Object Proposals.
객체 영역 추정 기법에 관한 여러 논문이 있습니다. 픽셀을 그루핑하는 선택적 탐색 기법이나 슬라이딩 윈도우를 사용하는 EdgeBoxes 등이 있죠. 하지만 그간 영역 추정 기법은 객체 탐지 모델과 독립적으로 곧, 외부 모듈로 사용되었습니다.
<NOTE> 예를 들어, 선택적 탐색은 CPU에서 수행합니다. 선택적 탐색으로 찾은 여러 경계 박스를 활용해 이어서 GPU에서 신경망으로 객체 탐지를 했죠. 곧, 선택적 탐색은 신경망(딥러닝)과 독립적인 모듈이었습니다. Faster R-CNN 이전까지는 말이죠.
Deep Networks for Object Detection.
R-CNN은 영역 추정 경계 박스를 객체 클래스와 배경으로 분류하기 위해 CNN을 end-to-end로 훈련합니다. R-CNN은 주로 객체 클래스를 분류하는 역할을 합니다. 객체의 위치를 예측하지는 않습니다. 물론 경계 박스 회귀를 해서 미세하게 위치를 조정합니다. 하지만 맨 처음 영역 추정을 하는 선택적 탐색은 GPU로 수행하는 게 아니라 별도로 CPU에서 수행한다고 했죠. 그래서 선택적 탐색 모듈이 전체적인 성능을 결정합니다. 여러 논문에서 딥러닝을 사용해 경계 박스를 예측하는 방법을 제안해왔습니다. 가령, OverFeat 기법이나 MultiBox 기법이 있죠.
합성곱 피처 계산 결과를 공유하는 것은 효율성과 정확도 때문에 주목을 받았습니다. 그런데 MultiBox 기법은 '영역 추정 모듈과 객체 탐지 네트워크'가 합성곱 피처를 공유하지 않는다는 단점이 있습니다. 반면, Fast R-CNN은 합성곱 피처를 공유하기 때문에 end-to-end 훈련이 가능하며, 속도와 정확도가 모두 좋았죠.
3. Faster R-CNN
Faster R-CNN은 두 가지 모듈로 이루어져 있습니다. 첫 번째 모듈은 영역 추정을 위한 깊은 합성곱 네트워크입니다. 두 번째 모듈은 객체 탐지 모듈입니다. 전체 네트워크는 객체 탐지를 위한 단일(single), 통합(unified) 구조입니다. 어텐션 메커니즘과 유사하게 영역 추정 네트워크(RPN)는 탐지기(detector)가 어디에 주목해야 하는지 말해주죠.
다음은 Faster R-CNN의 전체 구조입니다.

<NOTE> ① 먼저 합성곱 계층을 활용해 전체 이미지에 합성곱 연산을 합니다. ② 그 결과 피처 맵을 구하죠. 피처 맵은 ③ RPN과 ④ 분류기(classifier)에 전달됩니다. 여기서 분류기는 Fast R-CNN에서 사용한 분류기와 같습니다. 피처 맵이 RPN과 분류기에 동시에 전달된다는 말은 RPN과 분류기가 피처 맵을 공유해서 사용한다는 뜻입니다. ③ RPN은 피처 맵을 기반으로 객체가 있을 만한 곳을 찾아줍니다. 곧, 영역 추정을 합니다. 이어서 ⑤ 영역 추정 결과를 RoI 풀링합니다. ⑥ 최종적으로, 피처 맵과 영역 추정 경계 박스를 활용해 객체 탐지를 수행합니다. 여기서 RPN은 객체가 어디에 있을지, 즉, 탐지기가 어디에 주목을 해야 하는지 말해줍니다. 어텐션 메커니즘과 비슷하죠. 이렇듯 Faster R-CNN은 영역 추정과 이미지 분류 모두를 하나의 통합 네트워크에서 수행합니다. 영역 추정을 독립된 모듈(CPU에서)로 수행하는 Fast R-CNN과 다르죠.
그럼 3.1 RPN과 3.2 피처 공유에 관해 설명해보겠습니다.
3.1 Region Proposal Networks
RPN(Region Proposal Networks)은 크기에 상관없이 이미지 전체를 입력받습니다. 그다음 영역 추정 경계 박스를 반환합니다. 각 경계 박스는 객체가 있는지 여부를 점수로 나타내죠. 이런 RPN을 합성곱 네트워크로 처리하도록 만들었습니다. 앞서 말했듯 RPN과 Fast R-CNN 객체 탐지기는 피처 맵을 공유하죠.
영역 추정 경계 박스를 만들기 위해, 슬라이딩 윈도우 방식을 적용합니다. 아래 그림에서 왼쪽이 RPN 구조를 나타냅니다.

① 각 슬라이딩 윈도우는 ② 작은 차원의 피처로 매핑됩니다(ZF에서는 256차원, VGG에서는 512차원). 슬라이딩 윈도우로 구한 피처는 두 가지 전결합 계층에 입력됩니다. 첫 번째는 ③ 분류 계층(cls layer)이고, 두 번째는 ④ 경계 박스 회귀 계층(reg layer)입니다.
3.1.1 Anchors
각 슬라이딩 윈도우의 중심 위치마다 여러 경계 박스 영역을 예측합니다. 각 슬라이딩 윈도우 위치마다 최대로 예측할 수 있는 경계 박스 영역 개수는 ⑤ k개입니다. 그렇기 때문에 ④ 회귀 계층(reg layer)은 좌표값을 4k개 갖습니다. 경계 박스 하나에는 총 4가지 좌표값이 있으므로 k개 경계 박스에는 좌표값이 4k개가 있는 거죠. 그리고 ③ 분류 계층(cls layer)은 2k개 점수값을 갖습니다. 경계 박스 하나에는 객체일 확률과 객체가 아닐 확률로 두 가지 확률값이 있기 때문입니다.
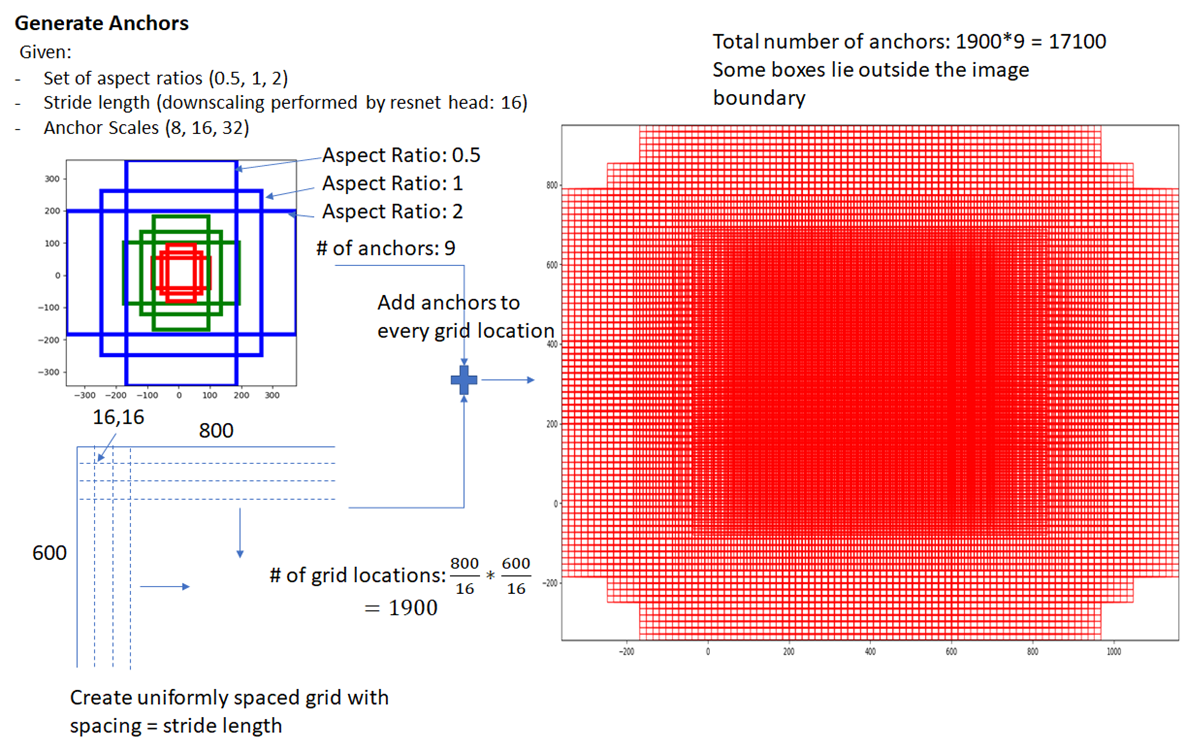
RPN에서 사용하는 이런 형태의 경계 박스를 앵커 박스(anchor box)라고 합니다. 여기서는 k=9입니다. 즉, 앵커 박스가 9개라는 말입니다. 3가지 스케일과 3가지 가로세로 비율(1:1, 2:1, 1:2)을 결합해 앵커 박스를 만들죠. 다음과 같이 말이죠.

피처 맵 크기가 W x H라면 앵커 박스 개수는 (W x H x k)개가 됩니다. 보통 W x H는 2,400이고, k=9로 설정했으니 전체 앵커 박스 개수는 2,400*9=21,600개가 되겠네요.
<NOTE> 피처 맵에 촘촘하게 점(그리드)을 찍어둔 뒤(실제로 점을 찍는다는 말이 아니라 위치만 표시한다는 말), 모든 점(그리드)마다 앵커 박스 9개를 구합니다. 그러면 앵커 박스가 서로 굉장히 많이 겹치겠죠. 크기도 9개니 다양하고요. 이렇게 구한 많은 앵커 박스를 바탕으로 후보 영역 추정을 위해 훈련한다는 뜻입니다. 다음 그림은 앵커 박스 예시입니다. (800, 600) 크기를 갖는 이미지에 합성곱 연산을 해서 (800/16, 600/16) 크기의 피처 맵을 만듭니다. 이 피처 맵 위에 1,900개(= 800/16 * 600/16)의 그리드를 표시합니다. 1,900개의 각 그리드마다 앵커 박스를 9개씩 그립니다. 그러면 앵커 박스는 총 17,100개가 되겠죠. 앵커 박스가 이렇게나 많고 다양하니 어떤 객체든 포함할 겁니다. RPN은 이런 앵커 박스를 바탕으로 훈련해서 후보 영역을 추정해줍니다.
Translation-Invariant Anchors
Faster R-CNN의 중요한 특성은 위치 불변성(Translation-Invariance)입니다. 위치 불변성이란 이미지 안에서 객체 위치가 변하더라도 같은 객체로 인식하는 특성입니다. 이미지 안에서 객체 위치가 변한다고 서로 다른 객체라고 인식하면 안 되겠죠. Faster R-CNN의 RPN은 슬라이딩 윈도우 방식으로 이미지의 전체 영역을 훑기 때문에 위치가 변해도 같은 객체로 잘 인식하는 겁니다. 반면, MultiBox 기법은 위치 불변성이 없습니다. 객체 위치가 변하면 같은 객체라고 판별하지 못하죠.
위치 불변성은 모델의 크기도 줄여줍니다. MultiBox는 (4 + 1) x 800차원의 전결합 계층을 갖지만 Faster R-CNN은 (4 + 2) x 9차원의 전결합 계층을 갖습니다(k=9일 때). 따라서 백본(Backbone) 모델이 VGG16일 때 총 출력 계층의 파라미터 개수는 2.8 x 10⁴개(= 512 x (4+2) x 9)입니다. MultiBox 출력 계층이 갖는 파라미터보다 훨씬 적죠. 파라미터가 적기 때문에 PASCAL VOC와 같이 작은 데이터셋에서도 과대적합 위험이 적습니다.
Multi-Scale Anchors as Regression References
멀티 스케일 예측에는 세 가지 방법이 있습니다. 앞서 봤던 다음 그림을 다시 보시죠.
(a) 첫 번째로 이미지 피라미드 방식이 있습니다. OverFeat, SPP-net에서 이미지 피라미드 방식을 사용했죠. 입력 이미지를 다양한 크기(멀티 스케일)로 조정해서 각 스케일마다 피처 맵을 구합니다. 효율적인 방법이지만 시간이 오래 걸립니다.
(b) 두 번째로 필터(슬라이딩 윈도우)를 다양한 크기(멀티 스케일)로 사용하는 방법이 있습니다. 피처 맵은 하나지만 다양한 필터를 사용해 풀링하는 방식이죠. 이러한 방식을 필터 피라미드 방식이라고 부릅니다.
본 논문에서는 기존에 사용하던 이미지 피라미드, 필터 피라미드보다 더 빠르고 효율적인 앵커 피라미드(pyramids of anchors) 방식을 소개합니다. 다양한 크기의 앵커 박스를 활용해 객체 분류, 경계 박스 회귀를 수행하죠. 앵커 피라미드 방식을 적용하면 추가 연산 없이 피처를 공유할 수 있어 효율적입니다.
3.1.2 Loss Function
RPN을 훈련하기 위해, 각 앵커 박스마다 이진 분류를 수행합니다. 앵커 박스에 객체가 있는지 없는지 여부를 이진 분류하는 것이죠. 분류를 하려면 앵커 박스에 positive label이 있어야 합니다. 두 가지를 positive label로 감안했는데요, (i) 실제 경계 박스(ground-truth box)와 IoU가 가장 큰 앵커, 또는 (ii) 실제 경계 박스(ground-truth box)와 IoU가 0.7이 넘는 앵커입니다. 여기서 주목할 점이 있습니다. 실제 경계 박스 하나마다 여러 앵커 박스를 positive label로 할당할 수 있다는 점입니다. 다시 말해, 객체 위치를 정확히 나타내는 앵커 박스 단 하나만 positive label로 사용하는 게 아닙니다. 실제 경계 박스와 IoU가 높다면 여러 앵커 박스를 positive label로 간주하는 겁니다. 보통은 (ii) 조건으로 앵커 박스를 찾지만, (ii) 조건을 만족하는 앵커 박스가 없으면 (i) 조건으로 positive label 앵커 박스를 찾습니다. 또한, IoU가 0.3보다 작은 앵커 박스는 negative label로 간주합니다. positive도 negative도 아닌 앵커 박스는 훈련에서 제외하기 때문에 객체 탐지에 영향을 미치지 않습니다.
이어서 손실 함수를 알아보죠. 손실 함수 수식은 다음과 같습니다.

앞 수식에서 i는 앵커 박스 인덱스를 뜻합니다. ① p_i는 i번째 앵커 박스가 객체일 확률을 말합니다. ground-truth label인 ② p*_i는 앵커가 positive이면 1, negative이면 0입니다. negative라는 건 배경이라는 말이죠. ③ t_i는 예측 경계 박스의 4가지 좌표값이고, ④ t*_i는 실제 경계 박스의 4가지 좌표값입니다. 분류 손실을 나타내는 ⑤ L_cls는 두 가지 클래스(객체 vs. 객체가 아님)에 대한 로그 손실입니다. ⑥ L_reg는 경계 박스 회귀 손실을 뜻합니다. 참고로 회귀 손실값은 positive 앵커 박스일 때만(객체 일 때만) 활성화됩니다. negative일 때, 곧 배경일 때는 경계 박스를 구할 필요 없으니까요. 회귀 손실에 p*_i x L_reg가 포함되므로, 앵커 박스가 negative일 때는 이 값이 0이 됩니다(p*_i = 앵커가 positive이면 1, negative이면 0).
다음으로 분류 손실과 회귀 손실 모두 ⑦ N_cls와 ⑧ N_reg로 나눠서 정규화했습니다. 분류 손실, 회귀 손실 간 균형을 맞추기 위해 ⑨ λ 파라미터도 두었습니다. 본 논문에서는 N_cls = 256, N_reg = 2,400를 사용합니다. 그리고 λ = 10으로 설정해 분류 손실과 회귀 손실을 거의 같은 비중으로 취급합니다. 1/N_cls = 1/256이고, λ/N_reg = 10/2,400 = 1/240이기 때문이죠.
경계 박스 회귀에 사용하는 파라미터는 다음과 같습니다.

x, y, w, h는 각각 경계 박스의 (x, y)좌표와 너비(w), 높이(h)를 뜻합니다. x, x_a, x*는 예측 경계 박스, 앵커 박스, 실제 경계 박스를 뜻하고요.
3.1.3 Training RPNs
RPN은 확률적 경사 하강법(SGD)과 역전파로 end-to-end 훈련을 할 수 있습니다. 앞서 여러 앵커 박스를 만들어 영역 추정을 한다고 했죠. 그런데 모든 앵커 박스마다 손실 함수를 적용해 최적화하면 negative label에 치우친 결과를 냅니다. 왜냐하면 positive label보다 negative label이 압도적으로 많기 때문이죠.
<NOTE> 이미지 안에서 객체가 차지하는 공간 비율보다 배경이 차지하는 비율이 더 크니까요.
그래서 손실 함수를 계산하기 위해 하나의 이미지에서 앵커 박스 256개를 무작위로 샘플링합니다. positive 앵커와 negative 앵커를 1:1 비율로 뽑죠. 따라서 이상적으로는 positive 앵커 128개, negative 앵커 128개가 됩니다.
훈련할 때 새로운 계층은 '평균 0, 분산 0.01인 가우시안 분포에서 뽑은 가중치'로 초기화합니다. 나머지 모든 계층(= 공유하는 합성곱 계층)은 이미지넷 분류 영역에서 사전 훈련된 모델의 가중치로 초기화합니다.
3.2 Sharing Features for RPN and Fast R-CNN
RPN과 Fast R-CNN이 피처를 어떻게 공유하는지 알아보죠. 앞서 말했듯 Faster R-CNN에서는 탐지기(detector)로 Fast R-CNN을 사용합니다. 여기에 RPN도 함께 적용했죠. RPN과 Fast R-CNN이 합성곱 피처를 공유해 사용하기 때문에 효율적입니다. 그런데 RPN과 Fast R-CNN은 합성곱 피처를 서로 다른 방법으로 독립적으로 훈련합니다. 그렇기 때문에 RPN과 Fast R-CNN이 합성곱 피처를 공유하면서도 서로 다른 방법으로 분리해서 사용할 수 있도록 해야 합니다. 세 가지 방법이 있습니다. (i) Alternating training, (ii) Approximate joint training, (iii) Non-approximate joint training이죠. (ii)와 (iii)은 사용하기에 어려워서 본 논문에서는 (i) 방식을 채택했습니다.
Alternating training이란 말 그대로 번갈아가며 훈련한다는 뜻입니다. 먼저 RPN을 훈련하고, 이어서 영역 추정 경계 박스를 사용해 Fast R-CNN을 훈련합니다. Fast R-CNN으로 튜닝된 네트워크는 다시 RPN을 초기화하는 데 사용합니다. 이런 절차를 반복합니다. 그러면 RPN과 Faster R-CNN이 피처를 공유하면서도 독립적인 방법으로 훈련할 수 있습니다.
4-Step Alternating Training.
이 논문에서는 피처를 공유하면서 훈련하도록 실용적인 4단계 훈련 알고리즘을 채택합니다. (1) 첫 번째 단계에서는, 3.1.3에서 설명한 바와 같이 RPN을 훈련합니다. 이 네트워크는 이미지넷으로 사전 훈련된 모델로 초기화하고 영역 추정 작업을 위해 end-to-end 파인 튜닝합니다. (2) 두 번째 단계에서는, 첫 번째 단계에서 생성한 영역 추정 경계 박스를 활용해 독립적인 Fast R-CNN을 훈련합니다. 이 네트워크도 이미지넷으로 사전 훈련된 모델로 초기화합니다. 지금까지는 RPN과 Fast R-CNN이 합성곱 피처를 공유하지 않았습니다. 세 번째 단계에서는, RPN 훈련 초기화를 위해 Fast R-CNN을 사용합니다. 다만, 공유된 합성곱 계층은 고정하고, 오직 RPN 계층만 파인 튜닝합니다. 이제 RPN과 Fast R-CNN은 합성곱 계층을 공유합니다. 마지막 단계에서는, 공유된 합성곱 계층을 역시 고정한 채로 오직 Fast R-CNN 계층만 파인 튜닝합니다. 이런 방식으로 RPN과 Fast R-CNN은 같은 합성곱 계층을 공유하면서 단일 네트워크를 구성할 수 있습니다.
3.3 Implementations Details
Faster R-CNN에서는, 단일 스케일(single scale) 이미지에 대해 영역 추정과 객체 탐지 훈련 및 테스트를 수행합니다. 이미지 피라미드를 사용해 멀티 스케일로 피처를 추출하는 방식은 성능은 좋지만 속도가 느립니다. 반면, 앵커 박스를 사용하면 성능과 속도 모두가 좋죠.
세 가지 스케일과 세 가지 가로세로 비율을 갖는 앵커 박스를 사용합니다. 세 가지 스케일은 128², 256², 512² 픽셀이고, 세 가지 가로세로 비율은 1:1, 1:2, 2:1입니다. 기존에는 다양한 스케일(과 가로세로 비율)을 갖는 영역을 예측하려면 이미지 피라미드나 이미지 필터를 사용해야 했습니다. 하지만 다양한 앵커 박스를 사용하면 이미지 피라미드나 이미지 필터를 사용할 필요가 없습니다. 동시에 속도도 빠릅니다. 아래 그림은 RPN을 활용한 객체 탐지 예시입니다. 보다시피 스케일과 가로세로 비율이 다양해도 제대로 탐지하네요.

다음 표는 앵커 박스 종류별 영역 추정 경계 박스의 평균 크기를 나타냅니다.
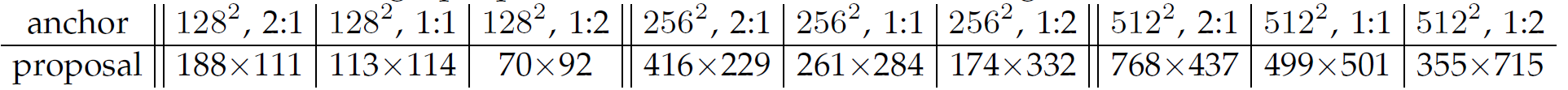
보다시피 앵커 박스 크기보다 큰 객체도 찾아주네요. 영역 추정 경계 박스의 한 면 길이가 앵커 박스의 한 면 길이보다 큰 경우가 있기 때문이죠. 객체를 찾기 위해 앵커 박스가 꼭 객체 전체를 감싸야만 할 필요는 없다는 점을 말해줍니다. 앵커 박스에 객체의 중심부만 어느 정도 포함되면 영역 추정을 잘 해줍니다.
이미지 경계를 가로지르는 앵커 박스(cross-boundary anchors)는 신중하게 처리해줘야 합니다. 그래서 훈련하는 동안, cross-boundary 앵커 박스는 손실에 영향을 미치지 못하도록 무시했습니다. 1000 x 600 픽셀의 이미지에는 앵커 박스가 약 20,000개(= 60 x 40 x 9) 있습니다. 여기서 cross-boundary 앵커 박스를 제거하면 6,000개만 남습니다. cross-boundary 앵커 박스를 제거하지 않으면 훈련 속도도 느리고 성능도 좋지 않습니다.
RPN에서 만든 영역 추정 경계 박스끼리는 서로 겹치는 영역이 많습니다. 겹치는 영역을 없애기 위해 비최댓값 억제(Non-Maximum Suppression, NMS)를 적용합니다.
<NOTE> 비최댓값 억제(Non-Maximum Suppression, NMS)란 경계 박스 가운데 가장 확실한 경계 박스만 남기고 나머지 경계 박스는 제거하는 기법입니다.
NMS IoU 임계값을 0.7로 설정했습니다. 그러면 경계 박스가 6,000개에서 2,000개로 줄어듭니다. 경계 박스 개수를 줄였기 때문에 속도는 당연히 빨라집니다. 그러면서도 성능은 그대로 유지됩니다. 비최댓값 억제의 장점이죠. 훈련할 때는 경계 박스 2,000개를 사용하지만, 테스트 단계에서는 개수를 달리합니다. 테스트 단계에서는 경계 박스를 300개 혹은 100개로 사용할 수 있다는 말입니다.
4. Experiments
4.1 Experiments on PASCAL VOC
객체 탐지 벤치마크 데이터셋인 PASCAL VOC 2007에서 Faster R-CNN의 성능을 평가해봤습니다. PASCAL VOC 2007은 훈련/검증 이미지 5,000개와 테스트 이미지 5,000개로 이루어져 있습니다. 클래스는 총 20개고요. 다음 표는 여러 영역 추정 기법별 성능 평가 결과를 나타냅니다. 베이스라인 모델로 ZF-net을 이용했습니다.

① 선택적 탐색(selective search) 기법과 ② EdgeBoxes 기법은 훈련/테스트 단계에서 모두 영역 추정 경계 박스를 2,000개 만듭니다. 각각 mAP 58.7%, 58.6%입니다. 반면 (RPN, 피처 공유, 베이스라인 ZF-net을 적용한) Faster R-CNN은 mAP 59.9%를 달성했습니다. Faster R-CNN은 테스트 단계에서는 영역 추정 경계 박스 개수가 최대 300개입니다. NMS를 적용해서 더 적은 경계 박스를 남길 수도 있습니다. Faster R-CNN은 피처를 공유하고, 테스트 단계에서 경계 박스 개수도 적기 때문에 선택적 탐색(SS)이나 EdgeBoxes(EB)에 비해 더 빠릅니다.
Ablation Experiments on RPN.
<NOTE> Ablation Experiments란 요소를 하나씩 없애면서 해당 요소가 전체 시스템에 어떤 영향을 주는지 확인하는 분석 기법을 말합니다. 가령 피처 A, B, C가 있을 때 전체 성능이 50이라고 합시다. 피처 A를 제거하고 피처 B, C만 갖는 상태에선 성능이 40이라고 합시다. 그럼 피처 A는 전체 성능 향상에 대략 10만큼 도움을 주는 요소라고 볼 수 있죠.
Ablation 실험을 통해 각 요소별 효과를 알아봤습니다.
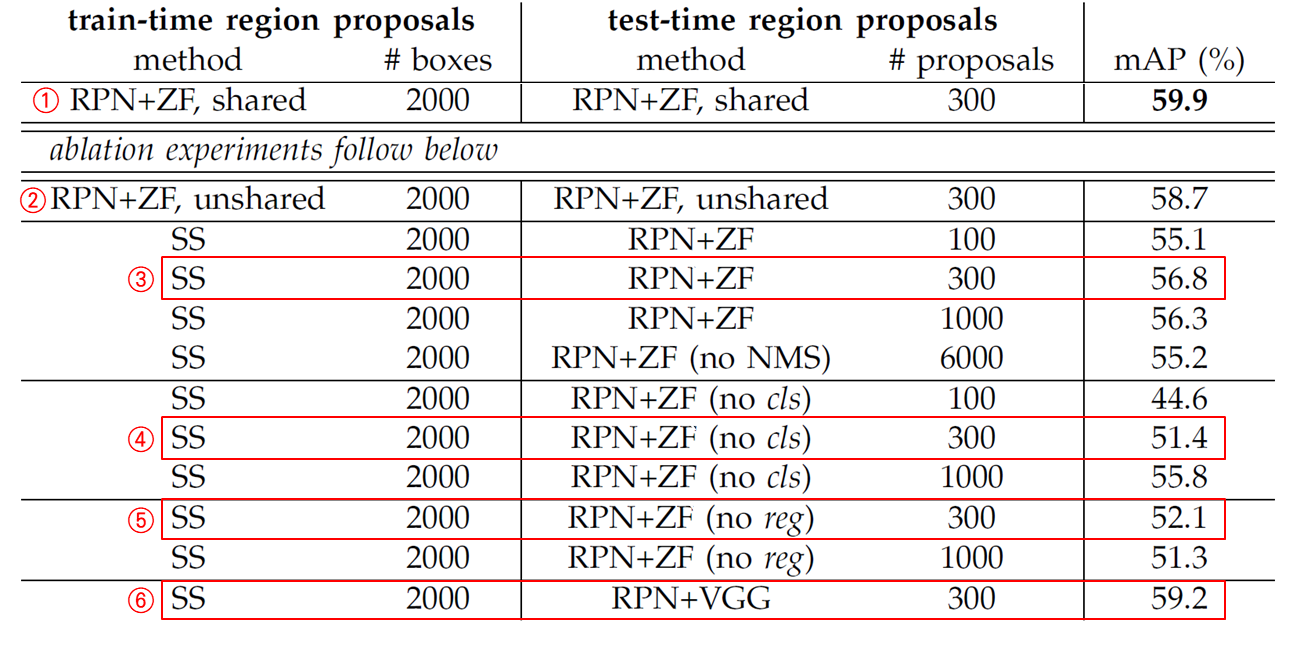
먼저 RPN과 Fast R-CNN이 합성곱 계층을 공유하는 것의 효과를 알아봤습니다. 이를 위해 앞서 살펴본 4단계 훈련 절차(4-Step Alternating Training)에서 2단계까지만 진행했습니다. 2단계까지는 합성곱 계층을 공유하지 않기 때문이죠. 합성곱 계층을 공유하지 않은 결과(②)가 공유한 결과(①)보다 성능이 떨어졌네요. 세 번째 단계에서 RPN을 파인 튜닝하기 때문에 더 품질 좋은 영역 추정 경계 박스를 출력한다는 점을 알 수 있습니다.
이번에는 RPN의 효과를 알아보겠습니다. 훈련 단계에서 RPN을 선택적 탐색(selective search)으로 바꿔봤습니다. 테스트 단계에서는 여전히 RPN을 사용하고요. 그 결과(③) mAP가 56.8%로 떨어졌습니다. (선택적 탐색을 사용한) 훈련 단계와 (RPN을 사용한) 테스트 단계에서 서로 영역 추정 경계 박스가 일치하지 않기 때문입니다. 게다가 테스트 단계에서 영역 추정 경계 박스를 100개, 300개, 1,000개, 6,000개로 생성해본 결과, 300개일 때 성능이 가장 좋았습니다. 테스트 단계에서는 경계 박스 300개가 최적이라는 말이죠.
이어서 분류 계층과 회귀 계층의 영향도 실험해봤습니다. 분류 계층이 없을 때(④)와 회귀 계층이 없을 때(⑤) 성능이 모두 떨어졌습니다. 또한, 더 성능 좋은 베이스라인 네트워크를 사용하면 객체 탐지 성능도 좋아지는지 실험해봤습니다. RPN을 훈련하기 위해 ZF-net을 사용하는 대신 VGG-16을 사용해봤습니다(분류기는 여전히 ZF-net을 사용합니다). 그 결과 mAP가 ③ 56.8%에서 ⑥ 59.2%로 늘었네요. RPN를 ZF-net으로 훈련하는 것보다 VGG-16으로 훈련하니 성능이 더 좋아졌습니다.
Performance of VGG-16.
RPN을 ZF-net으로 훈련하는 대신 VGG-16으로 훈련해 성능을 측정해봤습니다. 결과는 다음 표와 같습니다.

data 열에 07과 07+12, COCO+07+12가 있죠? 07은 훈련할 때 사용한 데이터셋이 PASCAL VOC 2007이라는 말이고, 07+12은 PASCAL VOC 2007, VOC 2012이라는 말입니다. COCO+07+12는 여기에 MS COCO 데이터셋까지 더해 훈련했다는 말이고요. 단, 테스트할 때는 VOC 2007 테스트 데이터셋만 사용했습니다.
보다시피 VGG-16을 활용하니 mAP가 올랐고, 데이터를 더 많이 사용하니 mAP가 더 올랐습니다.
다음 표는 VGG-16을 사용한 네트워크와 ZF-net을 사용한 네트워크의 속도 차이를 보여줍니다(K40 GPU에서 실험).

VGG-16을 활용한 네트워크가 ZF-net을 활용한 네트워크보다 복잡하다보니 성능은 좋은 반면 속도는 5 fps로 느립니다.
Sensitive to Hyper-parameters.
몇 가지 하이퍼파라미터에 따른 차이를 알아보죠. 다음 표는 앵커 박스 설정에 따른 Faster R-CNN의 mAP 차이를 보여주는 표입니다. 참고로 PASCAL VOC 2007 테스트 데이터셋에서 실험한 결과입니다.
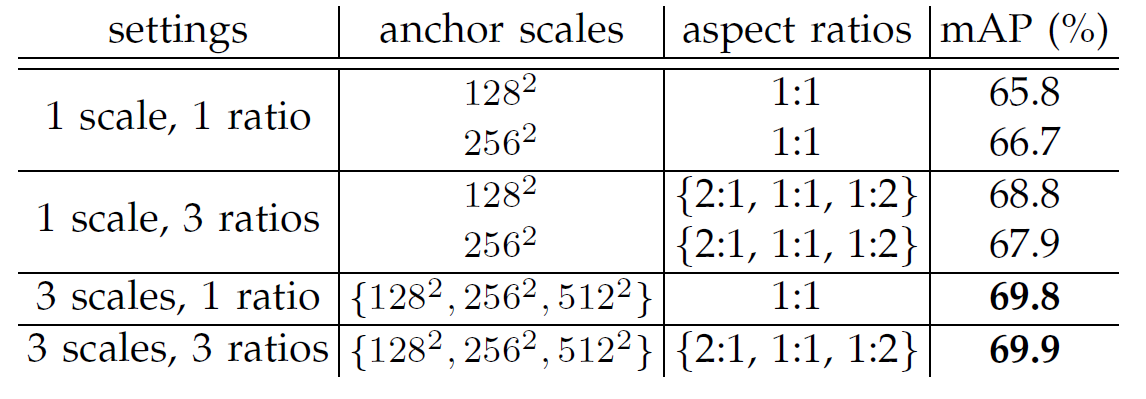
표가 보여주듯 앵커 박스의 스케일과 가로세로 비율이 각 3개씩일 때 성능이 제일 좋습니다(mAP 69.9%).
다음 표는 λ에 따른 mAP 차이를 나타냅니다. 역시 PASCAL VOC 2007 테스트 데이터셋으로 실험한 결과입니다.
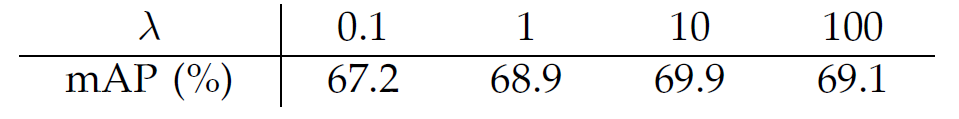
앞서 말했듯 λ=10이 기본값(default)입니다. λ=10일 때, (정규화 후) 분류 손실과 회귀 손실 비중이 거의 비슷해지기 때문이죠. λ 값이 기본값의 1/10배(λ=1)되든 10배(λ=100)되든 mAP 차이는 1% 미만입니다. 따라서 λ 값은 상대적으로 덜 민감한 하이퍼파라미터입니다.
Analysis of Recall-to-IoU.
다음으로 IoU 값에 따른 영역 추정 경계 박스의 재현율(recall)을 계산해봤습니다. 다음은 300개, 1,000개, 2,000개의 영역 추정 경계 박스에 따른 재현율과 IoU 관계를 나타낸 그래프입니다.

One-Stage Detection vs. Two-Stage Proposal + Detection.
이번에는 One-Stage Detection과 Two-Stage Proposal + Detection의 성능 차이를 비교해보겠습니다. OverFeat은 one-stage detection 파이프라인을 갖습니다. 객체의 위치 추정과 객체 분류를 파이프라인 하나로 동시에 진행합니다. 반면 Faster R-CNN은 two-stage 파이프라인을 갖습니다. 영역 추정 단계와 객체 분류 단계로 나뉘죠. RPN에서 (3 x 3) 슬라이딩 윈도우로 피처를 추출한 뒤, 9가지 앵커 박스로 경계 박스를 추정합니다. 이어서 객체 분류를 수행하죠.
one-stage와 two-stage 시스템을 비교하기 위해 OverFeat을 모방해 one-stage Fast R-CNN을 만들었습니다. 다음 표는 one-stage와 two-stage 시스템의 성능 차이를 보여줍니다.

one-sateg보다 two-stage의 mAP가 더 좋네요.
4.2 Experiments on MS COCO
MS COCO 데이터셋을 사용해도 Faster R-CNN이 Fast R-CNN보다 더 높은 성능을 보입니다. 다음 표는 MS COCO 데이터셋을 활용한 객체 탐지 성능 결과입니다. 이때 모델은 VGG-16을 사용했습니다.

5. Conclusion
본 논문에서는 빠르고 정확한 영역 추정을 하기 위해 RPN을 제안했습니다. RPN과 객체 탐지기가 합성곱 피처를 공유함으로써 영역 추정 비용을 크게 줄였습니다. Faster R-CNN은 통합된 딥러닝 기반 객체 탐지 시스템으로, 실시간 객체 탐지가 가능할 정도로 빠릅니다. 전체적인 정확도도 기존 모델들보다 뛰어납니다.
'논문 리뷰' 카테고리의 다른 글
| 논문 리뷰 - 캐스케이드 검출기 (Cascade Detector) 톺아보기 (0) | 2023.02.11 |
|---|---|
| 논문 리뷰 - SSD(Single Shot MultiBox Detector) 톺아보기 (0) | 2022.03.30 |
| 논문 리뷰 - Fast R-CNN 톺아보기 (2) | 2022.03.09 |
| 논문 리뷰 - SPP-net 톺아보기 (0) | 2022.02.26 |
| 논문 리뷰 - R-CNN 톺아보기 (9) | 2022.02.02 |



