
귀퉁이 서재
DATA - 23. Data Wrangling (Gathering Data) II 본문

미디어위키(Media Wiki) API
미디어위키(Media Wiki) API는 미디어위키에 접근할 수 있는 API입니다. 너무 당연한 설명이네요.. (Reference1) 미디어위키에 접근할 수 있는 API 라이브러리는 다양합니다. Python 기반 라이브러리 중 가장 많이 쓰이는 것은 wptools입니다. (Reference2)
인터넷을 통해 미디어위키에 직접 접속해 검색하는 것을 wptools를 활용하여 코드화할 수 있습니다. 미디어위키에 '마하트마 간디'를 쳐서 검색 결과를 가져오는 작업을 코드화해 보겠습니다. (Mahatma gandi 위키피디아 검색 결과)
우선 wptools 라이브러리를 설치합니다.
pip install wptoolsMahatma gandi를 검색한 미디어위키 페이지의 url은 https://en.wikipedia.org/wiki/Mahatma_Gandhi 입니다. wiki/의 오른쪽 부분 'Mahatma_Gandhi'를 page()의 파라미터로 넣어주시면 됩니다. page() 파라미터에 'Mahatma_Gandhi'를 넣어주고 실행하면 검색하는 행위까지 한 것입니다. 검색 결과를 가져오는 것은 get()이 합니다.
import wptools
page = wptools.page('Mahatma_Gandhi').get()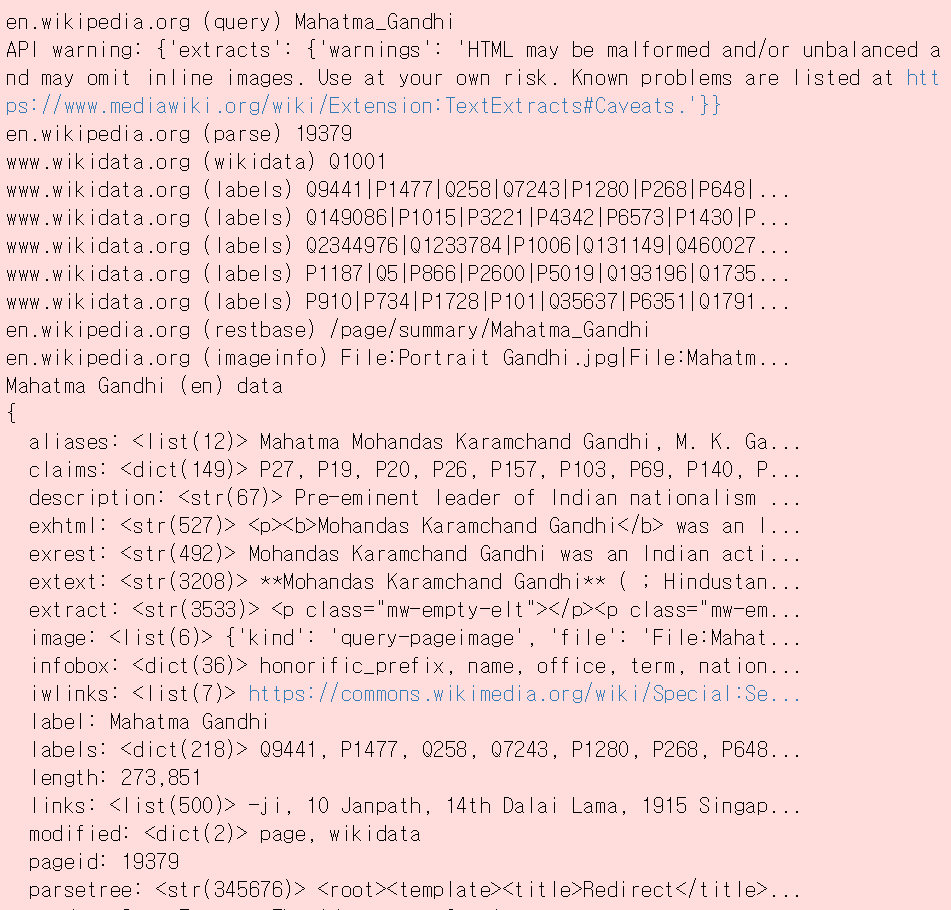
위는 get()의 결과입니다. 우리가 원하는 건 Mahatma Gandhi (en) data 부분입니다. 이 부분이 검색 결과에 대한 데이터입니다. data는 JSON 형태로 되어있습니다. 따라서 page.data['key 값']을 해주면 해당 key 값에 매칭 되는 데이터를 불러옵니다. 많은 데이터 중 image 데이터를 가져와 보겠습니다.
page.data['image']
API 데이터 타입: JSON과 XML
API를 통해 받아온 데이터는 대부분 JSON 혹은 XML 형식입니다. JSON은 JavaScript Object Notation의 약자이고 XML은 Extensible Markup Language의 약자입니다. JSON은 python의 dict형태의 data type이고, XML은 HTML처럼 tag와 attribute로 이루어져 있는 data type입니다. (Reference3) wptools로 받아온 data는 JSON 형태입니다. 아래는 python dict를 JSON으로 저장하고, 저장한 JSON을 읽는 코드입니다.
JSON으로 저장 (json.dump)
import json
data = {}
data['people'] = []
data['people'].append({
'name': 'Scott',
'website': 'stackabuse.com',
'from': 'Nebraska'
})
data['people'].append({
'name': 'Larry',
'website': 'google.com',
'from': 'Michigan'
})
data['people'].append({
'name': 'Tim',
'website': 'apple.com',
'from': 'Alabama'
})
with open('data.txt', 'w') as outfile:
json.dump(data, outfile)JSON 읽기 (json.load)
import json
with open('data.txt') as json_file:
data = json.load(json_file)
for p in data['people']:
print('Name: ' + p['name'])
print('Website: ' + p['website'])
print('From: ' + p['from'])
print('')더 자세한 사항은 레퍼런스4를 참고해주시기 바랍니다. (Reference4)
라이브러리를 활용하여 이미지 파일 저장하기
웹 스크레이핑한 데이터를 파일로 저장하는 일반적인 방식은 아래와 같습니다.
import requests
r = requests.get(url)
with open(folder_name + '/' + filename, 'wb') as f:
f.write(r.content)이미지에 대해 읽고 쓸 때는 주의해야 합니다. 이미지에 대한 url이라면 위 코드는 에러가 날 수도 있습니다. 따라서 추천하는 방법은 image 전용 라이브러리를 사용하는 것입니다. PIL와 io 라이브러리입니다. (Reference5)
import requests
from PIL import Image
from io import BytesIO
r = requests.get(url)
i = Image.open(BytesIO(r.content))
i.save(folder_name + '/' + file_name + '.' + file_format)이미지에 대한 response body에 접근할 때는 Bytes로 접근하는 것이 좋다고 합니다. 따라서 일반적인 파일을 읽고 쓰는 것과는 다르게 BytesIO를 사용하시면 됩니다. 혹시 이것마저 에러가 난다면 직접 이미지를 다운받아서 저장하는 수밖에 없습니다.
[실습] MediaWiki의 영화 포스터 이미지 저장하기
MediaWiki의 영화 포스터 이미지를 API 라이브러리를 활용해서 저장하는 실습을 해보겠습니다. 총 100개의 영화에 대한 MediaWiki 검색결과를 받아와 그중 포스터 이미지를 저장하는 코드입니다. 원래는 title_list가 100개입니다. 코드의 길이가 너무 길어지는 것 같아 생략을 했습니다. 영화 제목이 100개라고 생각하시면 됩니다.
import pandas as pd
import wptools
import os
import requests
from PIL import Image
from io import BytesIO
title_list = [
'The_Wizard_of_Oz_(1939_film)',
'Citizen_Kane',
'The_Third_Man',
'Get_Out_(film)',
'Roman_Holiday',
'Man_on_Wire',
'Jaws_(film)',
'Toy_Story',
'The_Godfather_Part_II',
'Battleship_Potemkin'
]
folder_name = 'bestofrt_posters'
# Make directory if it doesn't already exist
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# List of dictionaries to build and convert to a DataFrame later
df_list = []
image_errors = {}
for title in title_list:
try:
ranking = title_list.index(title) + 1
page = wptools.page(title, silent=True)
images = page.get().data['image']
# First image is usually the poster
first_image_url = images[0]['url']
r = requests.get(first_image_url)
# Download movie poster image
i = Image.open(BytesIO(r.content))
image_file_format = first_image_url.split('.')[-1]
i.save(folder_name + "/" + str(ranking) + "_" + title + '.' + image_file_format)
# Append to list of dictionaries
df_list.append({'ranking': int(ranking),
'title': title,
'poster_url': first_image_url})
# Not best practice to catch all exceptions but fine for this short script
except Exception as e:
print(str(ranking) + "_" + title + ": " + str(e))
image_errors[str(ranking) + "_" + title] = imagesexcept처리를 한 이유는 간혹 error가 뜨는 경우가 있기 때문입니다. 코드를 실행하고 나면, df_list에는 에러가 뜨지 않은 영화에 대한 정보가 들어있고, image_errors에는 에러가 뜬 영화에 대한 정보가 들어있을 겁니다. 또한, i는 포스터 이미지입니다. jupyter notebook에 i만 치고 쉬프트 엔터를 누르면 포스터 이미지가 결과창에 나올 겁니다.
아래는 에러가 뜬 영화에 대한 url을 하드코딩으로 박아준 겁니다.
for key in image_errors.keys():
print(key)
# Inspect unidentifiable images and download them individually
for rank_title, images in image_errors.items():
if rank_title == '22_A_Hard_Day%27s_Night_(film)':
url = 'https://upload.wikimedia.org/wikipedia/en/4/47/A_Hard_Days_night_movieposter.jpg'
if rank_title == '53_12_Angry_Men_(1957_film)':
url = 'https://upload.wikimedia.org/wikipedia/en/9/91/12_angry_men.jpg'
if rank_title == '72_Rosemary%27s_Baby_(film)':
url = 'https://upload.wikimedia.org/wikipedia/en/e/ef/Rosemarys_baby_poster.jpg'
if rank_title == '93_Harry_Potter_and_the_Deathly_Hallows_–_Part_2':
url = 'https://upload.wikimedia.org/wikipedia/en/d/df/Harry_Potter_and_the_Deathly_Hallows_%E2%80%93_Part_2.jpg'
title = rank_title[3:]
df_list.append({'ranking': int(title_list.index(title) + 1),
'title': title,
'poster_url': url})
r = requests.get(url)
# Download movie poster image
i = Image.open(BytesIO(r.content))
image_file_format = url.split('.')[-1]
i.save(folder_name + "/" + rank_title + '.' + image_file_format)
# Create DataFrame from list of dictionaries
df = pd.DataFrame(df_list, columns = ['ranking', 'title', 'poster_url'])
df = df.sort_values('ranking').reset_index(drop=True)
dfPython을 통한 SQL
python을 활용해 SQL을 다룰 수 있는 라이브러리 중 sqlalchemy라는 것이 있습니다. 이전 챕터에서 데이터의 사이즈가 커지면 플랫파일보다는 DB를 활용하는 것이 좋다고 했습니다. (Reference6) 그럴 때 활용할 수 있는 라이브러리가 sqlalchemy입니다.
import pandas as pd
df = pd.read_csv('bestofrt_master.csv')
from sqlalchemy import create_engine
# Create SQLAlchemy Engine and empty bestofrt database
# bestofrt.db will not show up in the Jupyter Notebook dashboard yet
engine = create_engine('sqlite:///bestofrt.db')
# Store cleaned master DataFrame ('df') in a table called master in bestofrt.db
# bestofrt.db will be visible now in the Jupyter Notebook dashboard
df.to_sql('master', engine, index=False)
df_gather = pd.read_sql('SELECT * FROM master', engine)위 코드는 플랫 파일인 CSV를 dataFrame으로 불러온 뒤, sqlalchemy 라이브러리를 활용하여 해당 df를 DB로 저장하는 것입니다. 그 다음 SQL문을 날려 df로 받아오는 것입니다.
지금까지 데이터 랭글링 중 Data Gathering에 대해 배웠습니다. 이제 Data Assess와 Data Cleaning이 남았습니다.
References
Reference3 : API Data Exchange: XML vs. JSON
Reference4 : Reading and Writing JSON to a File in Python
Reference5 : Binary Response Content
Reference6 : Why do you use Pandas instead of SQL?
'데이터 분석' 카테고리의 다른 글
| DATA - 25. Data Wrangling (Cleaning Data) (0) | 2019.05.20 |
|---|---|
| DATA - 24. Data Wrangling (Assess Data) (0) | 2019.05.19 |
| DATA - 23. Data Wrangling (Gathering Data) (0) | 2019.05.10 |
| DATA - 22. 로지스틱 회귀(Logistic Regression) (8) | 2019.05.06 |
| DATA - 21. Higher order term (3) | 2019.05.02 |


