
귀퉁이 서재
NLP - 11. 워드투벡터(Word2Vec) 본문

Word2Vec은 워드 임베딩(Word Embedding) 방법론 중 하나입니다. Word2Vec을 설명하기 앞서 아래 예시를 한번 보겠습니다.
한국 - 서울 + 파리 = 프랑스
어머니 - 아버지 + 여자 = 남자
아버지 + 여자 = 어머니
직관적으로 이해하시는 분들도 있을 겁니다. 첫번째 예시를 보면 우선 한국이라는 단어에서 수도에 해당하는 서울을 빼줍니다. 한국에서 서울이라는 특성을 뺐으니 나라에 해당하는 껍데기 의미만 남아있을 겁니다. 거기에 파리를 더해주면 프랑스가 됩니다. 나라에 해당하는 껍데기에 파리라는 프랑스 수도를 더해주니 그 단어는 프랑스가 되는 것입니다. 마지막 예에서는 아버지에 여자라는 요소를 더해주면 어머니가 된다는 뜻입니다. Word2Vec을 활용하면 위와 같이 단어 간 관계를 파악할 수 있습니다. 이것이 어떻게 가능할까요? 아래 예시를 통해 설명하겠습니다.
사람의 성격을 벡터로 표현하는 것에 대해 생각해봅시다. 성격을 표현하기 위해서는 여러 고려 요소가 있을텐데, 우선 외향성&내향성 정도를 -1에서 1사이의 값으로 표현한다고 가정해보겠습니다. 1에 가까울수록 외향적인 성격이고 -1에 가까울수록 내향적인 성격입니다.

그 다음은 이성적&감성적 요소를 나타내는 값도 매깁니다.

실제 성격을 측정하기 위해서는 여러 요소를 고려해야겠지만 여기서는 두 가지 요소만 고려한다고 하겠습니다. 이런식으로 세 사람의 외향성&내향성, 이성&감정 정도를 측정합니다. 그럼 아래와 같이 벡터 형식으로 세 사람의 성격이 표현됩니다.
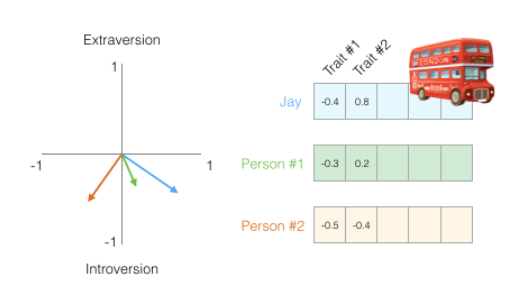
이제 세 사람 중 누구의 성격이 서로 비슷한지 보겠습니다. 벡터 간 유사도는 코사인 유사도를 통해 측정할 수 있습니다.

Jay는 코사인 유사도가 -0.20인 Person #2보다 코사인 유사도가 0.87인 Person #1과 성격이 더 유사합니다. 위의 벡터 화살표를 보면 파란색 벡터(Jay)는 초록색 벡터(Person #1)과 방향이 비슷한데, 주황색 벡터(Person #2)와는 방향이 서로 직각으로 아주 다릅니다. 벡터의 길이와 방향이 비슷할수록 서로 유사한 단어라는 것을 알 수 있습니다.
이제 본격적으로 Word2Vec에 대해 알아보겠습니다. 본 게시글은 딥러닝을 이용한 자연어처리 위키닥스를 참고하여 작성했음을 밝힙니다.
CBOW와 Skip-gram
Word2Vec은 크게 CBOW(Continuous Bag of Words)와 Skip-gram 방식으로 나뉩니다. CBOW 모델은 맥락으로부터 타깃을 예측하는 용도의 신경망입니다. ('타깃'은 중앙 단어이고, '맥락'은 그 주변 단어들입니다.) Skip-gram은 반대로 타깃으로부터 맥락을 예측하는 용도의 신경망입니다. 예를 들어보겠습니다.
You ___ goodbye and I say hello.
여기서 ___에 들어갈 단어를 예측하는 모델이 CBOW입니다. ____에 들어갈 단어가 '타깃(Target)'이고, 타깃의 주변 단어인 'You'와 'goodbye'는 '맥락(Context)'입니다. 여기서는 ____에 들어갈 단어로 'say'가 가장 적합한 답변일 것입니다. 그러나 'dog'나 'chair'와 같은 단어는 부적합합니다.
___ say ____ and I say hello.
반대로, 위와 같이 중앙의 단어(타깃)로부터 주변의 여러 단어(맥락)를 예측하는 모델을 Skip-gram이라 합니다.
skip-gram 모델은 하나의 단어로부터 그 주변 단어들을 예측합니다. 이는 꽤 어려운 문제입니다. You ___ goodbye and I say hello. 를 보면 타깃 값이 'say'임을 쉽게 추측할 수 있지만 ___ say ____ and I say hello. 를 보면 여러 후보가 떠오를 수 있습니다. 이런 점에서 CBOW보다 skip-gram 모델이 더 어려운 문제에 도전한다고 볼 수 있습니다. 더 어려운 상황에서 훈련이 된 만큼 skip-gram 모델이 내어 주는 단어의 분산 표현이 더 뛰어날 가능성이 있습니다.
Window size
You say _______ and I say hello.라는 문장이 있을 때, 타깃 단어를 예측하기 위해 사용할 앞뒤 맥락 단어의 갯수를 Window라고 합니다. windsow가 1이면 say와 and를 통해 타깃 단어를 예측하고, window가 2이면 You, say, and, I를 통해 타깃을 예측합니다.
Word2Vec 프로세스 (CBOW 기반)
윈도우를 정했다면 윈도우를 이동시키면서 타깃 단어(중심 단어)와 맥락 단어(주변 단어)를 뽑아 데이터셋으로 만들어 줍니다. 이 방법을 슬라이딩 윈도우(Sliding window)라고 합니다. 참고로 Word2Vec 학습을 위한 입력, 출력은 모두 원-핫 인코딩된 데이터여야 합니다. 아래는 window size가 2일 때 슬라이딩 윈도우를 통해 만들어준 데이터셋입니다. 이를 통해 CBOW 신경망을 학습시킬 것입니다.

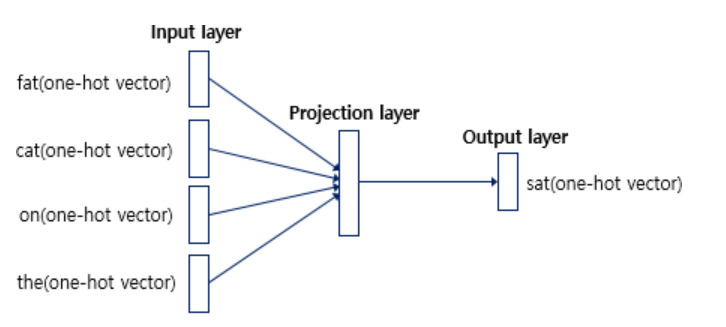
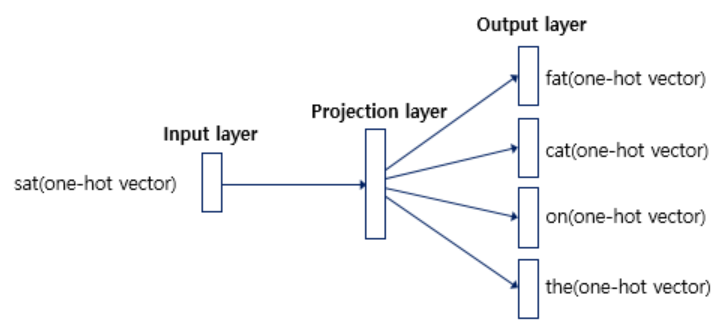
CBOW 신경망을 학습시켜 나온 최적의 가중치가 바로 워드 임베딩된 벡터입니다. CBOW 모델은 맥락 단어로부터 타깃 단어를 예측하는 모델이라고 했습니다. 따라서 CBOW 모델의 입력(input)은 맥락 단어의 원-핫 벡터이고, 출력(output)은 타깃 단어의 원-핫 벡터입니다. 아래는 CBOW 신경망 모델의 개괄적인 모습입니다. 윈도우가 2일 때의 예이며, 입력인 맥락 단어는 fat, cat, on, the이며 출력인 타깃 단어는 sat입니다.
Layer를 좀 더 확대시켜볼까요?
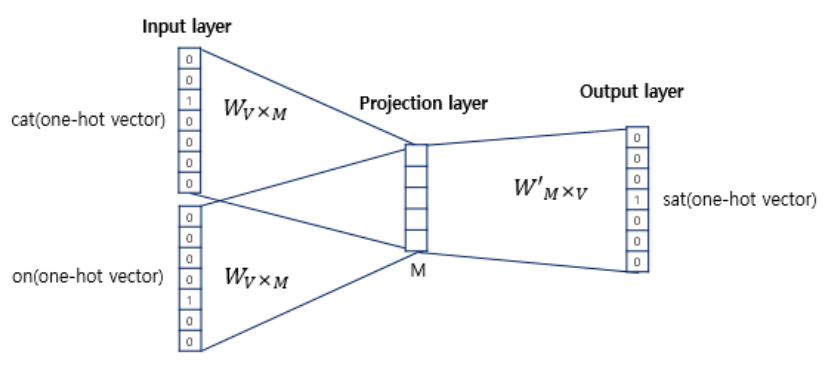
지면 관계상 fat과 the는 생략되어 있습니다. 입출력 데이터가 모두 원-핫 벡터임을 알 수 있습니다. 여기서 투사층(projection layer)의 크기는 M인데 이는 워드 임베딩 결과의 차원입니다. 위 그림에서 M은 5인데, 그러면 CBOW 모델의 결과로 도출된 워드 임베딩 벡터의 차원이 5가 된다는 뜻입니다.
입력층(input layer)에서의 가중치 행렬 W의 크기는 V x M입니다. V는 단어의 갯수이므로 위 그림에서 V = 7입니다. 따라서 가중치 행렬 W의 크기는 7 x 5입니다. 반면 출력층의 W' 행렬의 크기는 M x V, 즉 5 x 7입니다. W와 W'는 서로 다른 행렬임에 주의해야 합니다.
CBOW 신경망 모델은 입력 벡터(맥락 단어)를 통해 출력 벡터(타깃 단어)를 맞추기 위해 계속해서 학습하며 이 가중치 행렬 W와 W'을 갱신합니다.
입력층의 입력 벡터와 가중치 행렬 W가 어떻게 곱해지는지 보겠습니다.

위 그림에서 맥락 단어의 원-핫 벡터를 x라 표기했습니다. 예를 들어 x_cat (cat에 대한 웟-핫 벡터)은 3번째 인덱스만 1이고 나머지는 다 0입니다. 이와 가중치 행렬 W를 곱해주면 W의 3행에 해당하는 벡터가 도출됩니다. 그저 가중치 행렬 W에서 '입력 벡터에서 1이 포함된 인덱스'에 해당하는 행을 추출하는 작업일 뿐입니다. 다시 말해, 원-핫 벡터 x에서 1의 값을 가지고 있는 인덱스를 i라 할 때, 가중치 행렬 W의 i번째 행을 가져오는 작업입니다.
뒤에서도 말하겠지만 가중치 행렬 W가 결국 우리가 구하고자 하는 워드 임베딩 결과입니다. 즉 좋은 워드 임베딩 값을 구하기 위해서는 가중치 행렬 W를 잘 학습해야 합니다.

입력인 맥락 단어가 총 4개이므로 각 입력 원-핫 벡터와 가중치 행렬 W를 곱한 벡터 v가 4개 도출될 것입니다. 이제 이 벡터들의 평균 벡터를 구해야 합니다. 구해진 모든 v벡터 (v_fat, v_eat, v_on, v_the)를 더한 뒤 4로 나누어주면 됩니다. 4는 어떻게 나온 값일까요? 2 x (window size)입니다. 앞서 윈도우 사이즈를 2로 정했기 때문에 타깃 단어 앞 뒤로 2개의 맥락 단어를 입력 값으로 사용했습니다. 따라서 2 x 2 = 4이므로 4로 나누어주면 됩니다. 이제 평균 벡터 v를 구했습니다. 평균 벡터 v의 크기는 M입니다. (즉 5입니다.)
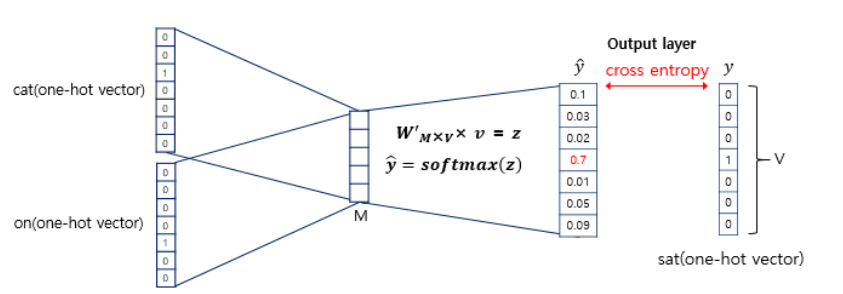
위에서 구한 평균 벡터 v를 출력층 가중치 행렬 W'와 곱합니다. 곱해서 얻어진 z 벡터의 크기는 V (즉 7)입니다. 이 벡터 z에 소프트맥스(Softmax)를 취해주면 확률 값에 해당하는 벡터 값이 구해집니다. 소프트맥스를 취해주면 모든 원소의 합이 1인 상태로 바뀌기 때문에 확률을 나타내는 것이라 보면 됩니다. 소프트맥스를 취해준 벡터와 실제 타깃 단어의 원-핫 벡터의 손실 함수(Loss function)로 cross-entropy를 사용합니다. cross-entropy에 대해 수식을 제외하고 직관적으로 설명하면 다음과 같습니다.
우리가 원하는 타깃 단어의 원-핫 벡터는 (0, 0, 0, 1, 0, 0, 0)입니다. 우리가 마지막에 소프트맥스를 취해준 벡터가 (0, 0, 0, 1, 0, 0, 0)에 가까울수록 cross-entropy값은 0이 되고, (0, 0, 0, 1, 0, 0, 0)과 달라질수록 1에 가까운 값이 됩니다. 즉, 손실 함수로 cross-entropy를 사용한다는 것은 CBOW 신경망을 통해 최종적으로 도출한 벡터가 타깃 벡터와 최대한 똑같아지게 하라는 뜻입니다. 이런 식으로 학습을 반복하며 가중치 행렬 W와 W'를 갱신합니다. 학습이 잘 되면 W와 W'의 값은 거의 비슷하기 때문에 어떤 것을 워드 임베딩 행렬로 사용해도 됩니다. 때로는 W와 W'의 평균값을 사용하기 합니다.
학습을 진행할수록 맥락으로부터 타깃 단어를 잘 추측하는 방향으로 가중치 행렬 W가 갱신됩니다. 그리고 놀랍게도 이렇게 해서 얻은 분산 표현 W에는 '단어의 의미'도 잘 녹아 있습니다.
Skip-gram
위에서 설명했듯이 Skip-gram은 CBOW의 반대입니다. CBOW가 맥락 단어로부터 타깃 단어를 예측했다면 Skip-gram은 타깃 단어로부터 맥락 단어를 예측합니다. 아래와 같이 말입니다.
CBOW는 입력층에서 벡터들의 평균치를 구했지만 Skip-gram에서는 그럴 필요가 없습니다. Skip-gram이 CBOW보다 성능이 우수하기 때문에 보통 Word2Vec을 쓴다고 하면 Skip-gram을 씁니다.
네거티브 샘플링(Negative Sampling)
단어가 적을 때는 상관없지만 단어가 100만 개 정도로 많아진다면 신경망 학습하는데 시간이 너무 많이 걸릴 겁니다. 아래의 계산에서 로드가 많이 걸립니다.
1. projection layer와 출력층 가중치 행렬의 곱
2. 소프트맥스 계산
단어의 수가 많아지면 당연히 가중치 행렬의 크기도 커져서 시간도 많이 들고 메모리도 많이 필요합니다. 신경망의 가중치를 갱신할 때 역전파 단계에서 갱신합니다. 그런데 단어가 100만 개 정도로 많다면 모든 단어 벡터들에 대해서 가중치를 갱신해야 합니다. 이를 개선하는 방법이 바로 네거티브 샘플링(Negative Sampling)입니다.
네거티브 샘플링은 소프트맥스를 할 때 모든 단어 대상으로 확률을 구하지 않고 일부 단어만 사용하여 계산을 하는 방식입니다. 윈도우 사이즈 내에 존재하지 않는 단어(negative)에 대해서는 일부(통상 5~20개)만 선택하여 소프트맥스를 계산하는 것입니다. 이렇게 함으로써 성능은 그대로 유지하고 계산 시간은 단축할 수 있습니다.
Word2Vec 실습
nltk의 영화리뷰 데이터를 활용하여 word2vec 실습을 해보겠습니다. 우선, nltk를 임포트하고 nltk내의 영화 리뷰 데이터를 다운로드합니다. word2vec을 활용하여 워드 임베딩을 하기 위해 영화 리뷰 말뭉치(코퍼스)를 구해야 합니다. 아래 코드와 같이 코퍼스는 리스트의 리스트 형태로 구합니다.
import nltk
nltk.download('movie_reviews')
from nltk.corpus import movie_reviews
sentences = [list(s) for s in movie_reviews.sents()]
sentences[0]['plot',
':',
'two',
'teen',
'couples',
'go',
'to',
'a',
'church',
'party',
',',
'drink',
'and',
'then',
'drive',
'.']이제, gensim 라이브러리의 Word2Vec 모듈을 사용하여 모델을 훈련합니다. Word2Vec(sentences) 코드 자체에 훈련 과정이 포함되어 있습니다.
from gensim.models.word2vec import Word2Vec
%time
model = Word2Vec(sentences)CPU times: user 40.6 s, sys: 1.89 s, total: 42.5 s
Wall time: 30.2 sinit_sims는 메모리상에서 불필요한 것을 제거해주는 코드입니다.
model.init_sims(replace=True)최종적으로 훈련이 완료된 Word2Vec모델을 활용하여 단어 간 유사도를 구해보겠습니다.
model.wv.similarity('actor', 'actress')0.8754437model.wv.similarity('he', 'she')0.86498755model.wv.similarity('actor', 'she')0.21053177유사도가 1에 가까울수록 두 단어는 유사한 단어이고, 0에 가까울수록 유사하지 않은 단어입니다. 이제 주어진 하나의 단어와 유사도가 가장 비슷한 단어를 추출해보겠습니다.
model.wv.most_similar('mother')[('father', 0.9660244584083557),
('wife', 0.9611752033233643),
('son', 0.9609498381614685),
('daughter', 0.9452119469642639),
('brother', 0.9245003461837769),
('husband', 0.9124630093574524),
('girlfriend', 0.9120829701423645),
('sister', 0.9014248847961426),
('boyfriend', 0.8968999981880188),
('partner', 0.876598596572876)]father와 유사도가 가장비슷한 것을 볼 수 있습니다.
References
Reference1: 딥러닝을 이용한 자연어처리 (워드투벡터)
Reference3: 데이터 사이언스 스쿨 (단어 임베딩과 word2vec)
Reference4: The Illustrated Word2vec Review (KR)
Reference5: 밑바닥부터 시작하는 딥러닝2
'자연어 처리 (NLP)' 카테고리의 다른 글
| NLP - 13. 시퀀스-투-시퀀스(seq2seq) (0) | 2020.06.20 |
|---|---|
| NLP - 12. 글로브(GloVe) & 엘모(ELMo) (0) | 2020.06.19 |
| NLP - 10. 워드 임베딩 (Word Embedding) (2) | 2020.06.14 |
| NLP - 9. 토픽 모델링: 잠재 의미 분석(LSA) (0) | 2020.03.19 |
| NLP - 8. 코사인 유사도(Cosine Similarity) (9) | 2020.02.17 |



