
귀퉁이 서재
NLP - 13. 시퀀스-투-시퀀스(seq2seq) 본문

이번 글은 RNN(Recurrent Neural Network)에 대해 이미 알고 있다는 가정 하에 썼습니다. RNN에 대해 잘 모르신다면 RNN을 먼저 배워오시기를 추천드립니다.
NLP 분야에서 seq2seq는 기계 번역, 문장 생성, 질의응답, 메일 자동 응답 등에 활용되는 모델입니다. 우선 기계 번역에 대해 알아보겠습니다. 예전의 기계 번역은 주로 규칙 기반(rule based)이었습니다. 문맥을 전체적으로 고려하지 않고 단어와 단어를 1:1로 번역하기 때문에 결과가 좋지 않았습니다. 극단적인 예이긴 하지만 아래와 같습니다.
성능이 좋지 않은 규칙 기반 번역: 나는 그곳에 갔다 -> I there went ??
'나는'을 I, '그곳에'를 there, '갔다'를 went로 단어 간 1:1 번역이기 때문에 결과가 좋지 않습니다.
하지만 시간이 지나 통계 기반(statistical based) 번역이 새로 등장했습니다. 통계 기반 번역 모델을 구축하기 위해서는 동일한 텍스트를 2가지 이상의 언어로 표현하고 있는 데이터가 필요합니다. 이를 병렬 말뭉치(병렬 코퍼스)라고 합니다.
'나는 그곳에 갔다'라는 한국어 문장과 'I went there'이라는 영어 문장을 이미 가지고 있는 상태에서 언어 모델의 입력(input)으로 한국어 문장을 넣어주고 타깃(target)으로 영어 문장을 넣어줍니다. 이런 식으로 동일한 의미를 지닌 2가지 이상의 언어 텍스트를 대량으로 활용하여 언어 모델을 학습시킵니다. 이제 훈련이 완료된 언어 모델은 '나는 그곳에 갔다'를 보면 'I went there'이 번역된 문장일 확률이 높다고 판단하고 해당 번역문을 출력해줍니다. 2000년 초 구글 번역기도 통계 기반이었다고 합니다. 하지만 통계 기반 번역도 여러모로 손이 많이가 크게 성공적이진 못했습니다.
하지만 NLP가 등장하며 기계 번역은 성능이 크게 향상되었습니다. 본격적으로 기계 번역으로 많이 활용되는 seq2seq에 대해 알아보겠습니다. 이번 장도 '딥러닝을 이용한 자연어 처리' 위키닥스를 참고하여 작성했음을 밝힙니다.
seq2seq 모델이란?
sequence-to-sequence(seq2seq) 모델은 한 문장(시퀀스)을 다른 문장(시퀀스)으로 변환하는 모델을 의미합니다. 아래는 seq2seq 모델을 통해 한 문장을 다른 문장으로 변환하는 예시입니다.
"I am a student" -> [Seq2Seq model] -> "je suis étudiant"
번역기와 같은 방식이라고 보면 됩니다. 영어 문장을 입력(input)으로 seq2seq 모델에 넣으면 불어 문장을 출력(output)합니다. 이제 seq2seq 내부 구조에 대해 알아보겠습니다.
seq2seq 내부 구조
seq2seq를 Encoder-Decoder 모델이라고도 합니다. 아래와 같이 seq2seq 모델은 인코더(Encoder)와 디코더(Decoder)로 구성되어 있기 때문입니다. 문자 그대로 인코더는 입력 데이터를 인코딩(부호화)하고, 디코더는 인코딩 된 데이터를 디코딩(복호화)합니다. 즉, 인코더는 입력을 처리하고 디코더는 결과를 생성합니다.
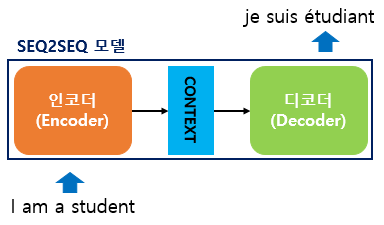
인코더와 디코더는 각각 어떤 역할을 할까요? 인코더는 'I am a student'라는 입력 문장을 받아 Context 벡터를 만듭니다. Context 벡터는 'I am a student'에 대한 정보를 압축하고 있는 벡터입니다. Context 벡터는 다시 디코더로 전달되며 디코더는 이를 활용하여 최종적으로 'je suis étudiant'라는 불어 문장을 생성합니다. 즉, 인코더는 문장을 가지고 Context 벡터를 만들어주는데, 이 Context 벡터에는 문장에 대한 정보가 응축되어 있습니다. 반면 디코더는 정보가 응축되어 있는 Context 벡터로부터 다른 문장을 생성해줍니다. 참고로, 간단한 seq2seq 모델에서 Context 벡터는 인코더의 마지막 스텝이 출력한 은닉 상태와 같습니다.
인코더와 디코더를 한층 더 들여다 보겠습니다.

인코더나 디코더는 RNN으로 구성되어 있습니다. 그중 LSTM이나 GLU가 사용되는데 위 예시에서는 LSTM을 사용했습니다. 인코더의 LSTM은 단어 순으로 입력을 받습니다. 아까 말씀드린 것처럼 인코더 LSTM의 마지막 은닉 상태가 바로 Context 벡터입니다.
인코더의 LSTM 계층은 오른쪽(시간 방향)으로도 은닉 상태를 출력하고 위쪽으로도 은닉 상태를 출력합니다. 이 구성에서 더 위에는 다른 계층이 없으니 LSTM 계층의 위쪽 출력은 폐기됩니다. 위 그림과 같이 인코더에서는 마지막 문자를 처리한 후 LSTM 계층의 은닉 상태 층인 Context 벡터를 디코더로 전달합니다.
디코더는 입력 문장을 통해 출력 문장을 예측하는 언어 모델 형식입니다. 위 그림에서 <sos>는 문장의 시작(start of string)을 뜻하고 <eos>는 문장의 끝(end of string)을 뜻합니다. 인코더로부터 전달받은 Context 벡터와 <sos>가 입력되면 그다음에 등장할 확률이 가장 높은 단어('je')를 예측합니다. 다음 스텝에서는 이전 스텝의 예측 값인 'je'가 입력되고 'je' 다음에 등장할 확률이 가장 높은 단어('suis')를 예측합니다. 이런 식으로 문장 내 모든 단어에 대해 반복합니다. 하지만 이는 Test 단계에서의 디코더 작동 원리입니다.
Training 단계에서는 교사 강요(teacher forcing) 방식으로 디코더 모델을 훈련합니다.
여기서 잠깐! 교사 강요(teacher forcing)란?
보통 RNN은 (n-1) 스텝에서의 출력 값을 n 스텝의 입력값으로 사용합니다. 즉, (n-1) 스텝에서 RNN 모델이 예측한 값을 n 스텝의 입력값으로 사용한다는 것입니다. 하지만 교사 강요는 이와 다릅니다. 교사 강요는 (n-1) 스텝의 예측 값을 n 스텝의 입력값으로 사용하는 것이 아니라 (n-1) 스텝의 실제값을 n 스텝의 입력값으로 넣어주는 방식입니다. 왜 이렇게 할까요?
(n-1) 스텝의 예측값이 실제값과 다를 수 있기 때문입니다. 예측은 예측일 뿐 실제와 다를 수 있습니다. 따라서 정확한 데이터로 훈련하기 위해 예측값을 다음 스텝으로 넘기는 것이 아니라 실제값을 매번 입력값으로 사용하는 것입니다. 이런 방식을 교사 강요라고 합니다.
다시 말하면 디코더의 훈련 단계에서는 교사 강요 방식으로 훈련하지만 테스트 단계에서는 일반적인 RNN 방식으로 예측합니다. 즉, 테스트 단계에서는 Context 벡터를 입력값으로 받아 이미 훈련된 디코더로 다음 단어를 예측하고, 그 단어를 다시 다음 스텝의 입력값으로 넣어줍니다. 이렇게 반복하여 최종 예측 문장을 생성하는 것입니다.
헷갈릴까봐 다시 설명하자면 디코더의 훈련 단계에서는 필요한 데이터가 Context 벡터와 <sos>, je, suis, étudiant입니다. 하지만 테스트 단계에서는 Context 벡터와 <sos>만 필요합니다. 훈련 단계에서는 교사 강요를 하기 위해 <sos>뿐만 아니라 je, suis, étudiant 모두가 필요한 것입니다. 하지만 테스트 단계에서는 Context 벡터와 <sos>만으로 첫 단어를 예측하고, 그 단어를 다음 스텝의 입력으로 넣습니다.
이제 단어 입력 부분을 더 세분화해서 살펴보겠습니다.

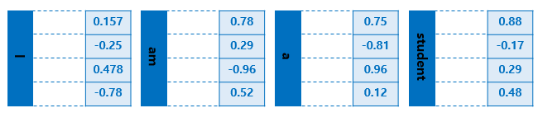
딥러닝 모델은 문자보다 숫자에 대한 성능이 더 좋습니다. 따라서 모든 문자는 숫자화해야 하며, 이를 워드 임베딩(Word Embeddings)이라고 합니다. I, am, a, student라는 문자도 모두 숫자로 즉, 벡터로 표현해야 합니다. 아래는 I, am, a, student에 대해 워드 임베딩을 한 결과인 벡터를 나타냅니다. 아래는 각 단어에 대해 4차원으로 표현했지만 실제는 몇백 차원으로도 표현한다고 합니다.
잠시 RNN에 대해 복습해보겠습니다.
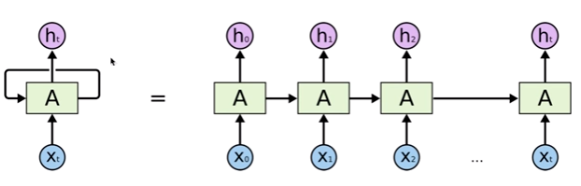
RNN은 각각의 스텝마다 두 개의 입력값을 받습니다. 하나는 (n-1) 스텝에서의 출력 값이고 다른 하나는 t스텝에서의 입력값입니다. 따라서 첫 번째 스텝에서의 출력값은 두번째 스텝에 입력이 되고, 두번째 스텝에서의 출력값은 세번째 스텝에 입력되고.. (n-1)번째 스텝에서의 출력값은 n번째 스텝에서의 입력이 됩니다. 따라서 n번째 스텝에서의 최종 출력값에는 첫번째부터 (n-1)번재 스텝에 대한 모든 정보가 녹아 있습니다.
이와 마찬가지로 테스트 단계에서 디코더는 인코더의 마지막 RNN 은닉층인 Context 벡터와 <sos>를 입력값으로 받습니다. 디코더의 첫번째 RNN 셀은 Context 벡터와 <sos>를 통해 첫 단어를 예측합니다. 이 단어는 두 번째 스텝의 RNN 셀의 입력값이 됩니다. 두 번째 스텝의 RNN 셀은 첫 번째 스텝의 RNN 셀이 예측한 단어와 두 번째 스텝에서의 입력값을 받아 두 번째 단어를 예측합니다. 이런 식으로 최종 예측 값이 <eos> 일 때까지 반복합니다.
이제 디코더의 출력층을 더 자세히 알아보겠습니다.
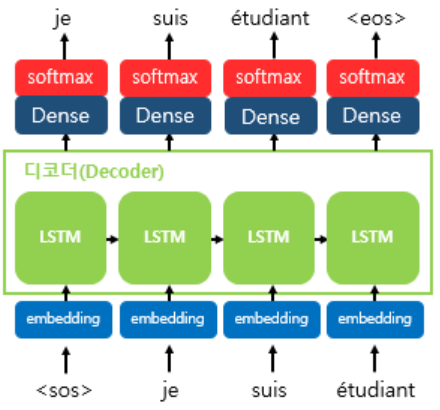
디코더 RNN 셀의 출력으로 다양한 단어에 대한 벡터 값이 나올 것입니다. 그중 확률이 가장 높은 단어를 선택하기 위해 softmax를 취해줍니다. 이를 통해 최종 예측 단어를 생성합니다.
seq2seq에 대해 정리해보겠습니다. seq2seq는 인코더와 디코더로 구성되어 있으며, 인코더는 입력 문장의 정보를 압축하는 기능을 합니다. 압축된 정보는 Context 벡터라는 형식으로 디코더에 전달됩니다. 디코더는 훈련 단계에서는 교사 방식으로 훈련되며, 테스트 단계에서는 인코더가 전달해준 Context 벡터와 <sos>를 입력값으로 하여 단어를 예측하는 것을 반복하며 문장을 생성합니다.
이상으로 seq2seq에 대해 알아봤습니다.
References
Reference1: 딥러닝 자연어 처리 이해하기! - 기계번역편(NMT), seq2seq란?
Reference2: 케라스를 이용해 seq2seq를 10분 안에 알려주기
Reference3: 딥러닝을 이용한 자연어 처리(시퀀스-투-시퀀스)
Reference4: 밑바닥부터 시작하는 딥러닝2
'자연어 처리 (NLP)' 카테고리의 다른 글
| NLP - 14. 어텐션(Attention) (10) | 2020.06.24 |
|---|---|
| NLP - 12. 글로브(GloVe) & 엘모(ELMo) (0) | 2020.06.19 |
| NLP - 11. 워드투벡터(Word2Vec) (3) | 2020.06.16 |
| NLP - 10. 워드 임베딩 (Word Embedding) (2) | 2020.06.14 |
| NLP - 9. 토픽 모델링: 잠재 의미 분석(LSA) (0) | 2020.03.19 |



