
귀퉁이 서재
논문 리뷰 - Fast R-CNN 톺아보기 본문

본 글에서 주요 내용 위주로 Fast R-CNN 논문을 번역/정리했습니다. 글 중간에 <NOTE>로 부연 설명을 달아놓기도 했습니다. 틀린 내용이 있으면 피드백 부탁드립니다.
- 논문 제목: Fast R-CNN
- 저자: Ross Girshick
- 기관: Microsoft Research
- 개정 발표: 2015년 9월 (첫 발표: 2015년 4월)
Abstract
본 논문에서는 '빠른 공간 기반 합성곱 신경망 모델(Fast Region-based Convolutional Network method, Fast R-CNN)'을 소개합니다. Fast R-CNN은 이전의 R-CNN이나 SPP-net과 비교해, 속도도 빠르고 성능도 좋습니다. Fast R-CNN은 PASCAL VOC 2012에서 R-CNN보다 VGG16 네트워크를 9배나 빠르게 훈련합니다. 테스트 단계에서는 213배나 빠르죠. 동시에 mAP도 더 높습니다. SPP-net과 비교하면 Fast R-CNN은 VGG16을 3배 빠르게 훈련합니다. 테스트 단계에서는 10배 빠릅니다. mAP도 역시 높고요. 참고로, Fast R-CNN은 파이썬과 C++로 구현되어 있습니다.
1. Introduction
최근(논문이 쓰인 2015년), 깊은 합성곱 신경망이 이미지 분류나 객체 탐지 성능을 크게 향상시켰습니다. 이미지 분류와 비교해서 객체 탐지 분야는 객체 위치까지 찾아야 하니 더 어려운 분야죠. 객체 위치를 찾아야 하는 작업이 추가로 필요해 객체 탐지 모델은 multi-stage 파이프라인을 갖습니다. multi-stage 파이프라인 때문에 속도도 느리고 파이프라인이 복잡하죠.
객체의 위치를 정확히 찾아야 하는 작업 때문에 복잡해지는 것이죠. 구체적으로는 두 가지 작업이 복잡합니다. 첫째, 여러 후보 영역(후보 경계 박스)을 처리해야 합니다. 둘째, 후보 영역은 대략적인 위치만 나타내는데, 이를 바탕으로 정확한 위치를 알아내야 합니다. 이런 복잡함을 해결하려면 속도, 정확성, 파이프라인의 간결성 가운데 하나와 타협해야 합니다.
이 논문에서는 최신 합성곱 신경망 기반 객체 탐지 모델의 훈련 절차를 간소화하는 방법을 소개합니다. 객체를 분류하는 일(classify object proposals)과 후보 영역에서 정확한 객체 위치를 탐색하는 일(refine their spatial locations)을 동시에 배우는 single-stage 훈련 알고리즘을 제안합니다.
<NOTE> 기존 객체 탐지 모델은 이미지 분류와 위치 찾기를 각각 다른 파이프라인에서 처리했습니다. multi-stage 모델이었죠.
Fast R-CNN은 객체 탐지 네트워크(VGG16)를 R-CNN보다 9배 빠르게, SPP-net보다 3배 빠르게 훈련합니다. 테스트 단계에서는 PASCAL VOC 2012로 객체 탐지하는 데 0.3초가 걸립니다(후보 영역 제안 시간은 제외). mAP는 66%를 달성하죠. 참고로, R-CNN의 mAP는 62%입니다. 이때 사용한 장비는 엔비디아 K40 GPU입니다.
1.1 R-CNN and SPP-net
R-CNN은 객체의 후보 영역을 분류하는 데 깊은 신경망을 사용하기 때문에 객체 탐지 성능이 우수합니다. 그렇지만 다음과 같이 눈에 띄는 단점이 있죠.
1. Training is a multi-stage pipeline.
R-CNN은 먼저 로그손실(log-loss)을 이용해 합성곱 신경망을 파인 튜닝합니다. 이어서 SVM으로 합성곱 신경망으로 구한 피처들을 처리하죠. SVM이 객체 탐지기 역할을 합니다. 마지막으로 경계 박스 회귀를 합니다.
<NOTE> 이렇듯 합성곱 신경망도 훈련하고, SVM으로 분류를 하고, 경계 박스 회귀도 합니다. 세 가지 단계가 필요하죠. 그래서 multi-stage 파이프라인입니다. 그만큼 복잡하다는 이야기입니다.
2. Training is expensive in space and time.
R-CNN은 시간도 오래 걸리고, 저장 공간도 많이 필요합니다. SVM과 경계 박스 회귀 훈련을 위해서 이미지의 각 객체 후보 영역에서 피처를 추출합니다. 피처들은 디스크 공간을 차지하죠. VGG16과 같은 깊은 신경망으로는 5,000개 이미지를 갖는 PASCAL VOC 2007 훈련 데이터셋을 처리하는 데 GPU로 2.5일이 걸립니다. 게다가 수백 GB의 저장 공간이 필요합니다.
3. Object detection is slow.
테스트 단계에서, 각 테스트 이미지마다 각 객체 후보 영역에서 피처를 추출합니다. 그렇기 때문에 GPU에서 객체 탐지하는 데 이미지당 47초가 걸립니다(VGG16 기준). 객체 탐지 속도가 너무 느리네요.
R-CNN은 느립니다. 각 후보 영역마다 합성곱 신경망을 훈련해야 하기 때문이죠. 이 방식은 후보 영역끼리 연산 결과를 공유하지 않습니다. 반면, SPP-net은 연산 결과를 공유하기 때문에 R-CNN보다 속도가 빠릅니다. SPP-net은 먼저 입력 이미지 전체에서 합성곱 계층의 피처 맵을 구합니다. 피처 맵에서 후보 영역들을 추출합니다. 후보 영역을 하나의 피처 맵에서 구한다는 말입니다. 곧, 피처 맵을 공유한다는 뜻이죠. 각 후보 영역마다 spatial pyramid 풀링을 적용해 고정된 크기의 피처 벡터를 구합니다. 이 피처 벡트가 전결합 계층의 입력값이 됩니다. 테스트 단계에서 SPP-net은 R-CNN보다 10 ~ 100배가량 빠릅니다. 훈련 단계에서는 속도가 3배 빠릅니다.
하지만 SPP-net도 단점이 있습니다. R-CNN과 마찬가지로, 훈련 구조가 multi-stage 파이프라인으로 이루어져 있습니다. 피처 추출, 로그손실로 신경망 파인 튜닝, SVM 훈련, 경계 박스 회귀로 나뉘죠. 역시나 피처들은 저장 공간을 차지합니다. 반면 R-CNN과 다르게 SPP-net에서 수행하는 파인 튜닝은 spatial pyramid 풀링 계층 앞에 있는 합성곱 신경망 계층을 업데이트하지 않습니다. 이런 한계(합성곱 계층이 파인 튜닝되지 않는 점)는 깊은 신경망 모델의 정확성을 끌어올리는 데 지장을 줍니다.
1.2 Contributions
연구진은 R-CNN과 SPP-net의 단점을 극복할 새로운 알고리즘을 제시합니다. 바로 Fast R-CNN입니다. Fast R-CNN이라고 부른 까닭은 훈련과 테스트 단계에서 '빠르기' 때문입니다. Fast R-CNN은 다음과 같은 여러 장점이 있습니다.
- R-CNN, SPP-net보다 객체 탐지 성능이 좋습니다.
- 훈련이 single-stage입니다. multi-task loss를 사용하면서 말이죠.
- 훈련을 하면서 네트워크 전체 파라미터를 업데이트할 수 있습니다.
- 피처 캐싱(feature caching)을 하기 위한 저장 공간이 필요 없습니다.
<NOTE> 3번을 보시죠. SPP-net에서 spatial pyramid 풀링 계층 앞에 있는 합성곱 신경망 계층은 업데이트되지 않았습니다. 반면, Fast R-CNN은 네트워크 전체 파라미터를 업데이트할 수 있다는 말입니다. 네트워크를 일부만 업데이트하는 것보단 전체를 업데이트하는 게 더 유리하겠죠.
2. Fast R-CNN architecture and training
다음 그림은 Fast R-CNN의 구조입니다. Fast R-CNN은 전체 이미지를 입력받아 후보 영역을 구합니다.
<NOTE> crop, warp된 이미지를 입력받는 R-CNN과 다르죠?
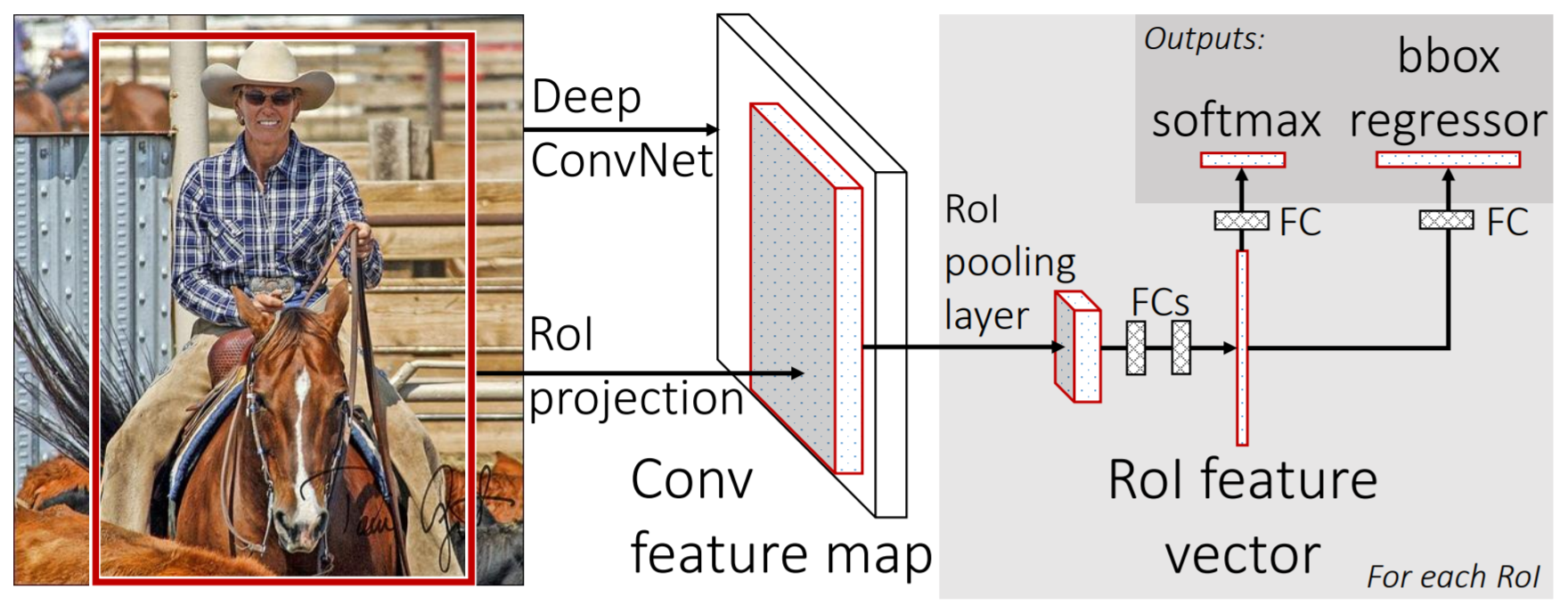
전체 이미지를 먼저 여러 합성곱 신경망으로 처리합니다. 뒤이어 최대 풀링을 거쳐 피처 맵을 구하죠. 그리고 RoI(Region of Interest) 풀링 계층은 피처 맵에서 고정된 크기의 피처 벡터를 추출합니다. 각 피처 벡터는 두 가지 전결합 계층의 입력값이 됩니다. 첫 번째 전결합 계층은 소프트맥스로 클래스의 확률을 구합니다. 클래스 개수가 K 개라고 할 때, 소프트맥스 결괏값 개수는 총 (K+1) 개입니다. 배경까지 포함하기 때문이죠. 두 번째 전결합 계층은 경계 박스의 좌표값을 구해줍니다. 이러한 Fast R-CNN 구조는 multi-task loss값을 사용해 end-to-end 훈련을 할 수 있습니다.
2.1 The RoI Pooling layer
RoI 풀링 계층은 최대 풀링을 사용해 RoI 영역 안에 있는 피처를 작은 피처 맵으로 변환합니다. 이 피처 맵은 크기가 고정된 형태입니다. 곧, (H x W) 형태라는 말입니다. H와 W는 특정 RoI와 독립적인 하이퍼파리미터입니다. RoI는 피처 맵으로 사상된(projection) 사각형 윈도우를 뜻합니다. RoI는 네 가지 값을 갖는 튜플 형태입니다. (r, c, h, w)인데, (r, c)는 좌상단 좌표값, (h, w)는 높이와 너비를 말합니다. RoI 풀링에 사용하는 윈도우 크기는 (h/H x w/W)가 됩니다. 아래 그림을 보면 이해가 쉬울 겁니다.
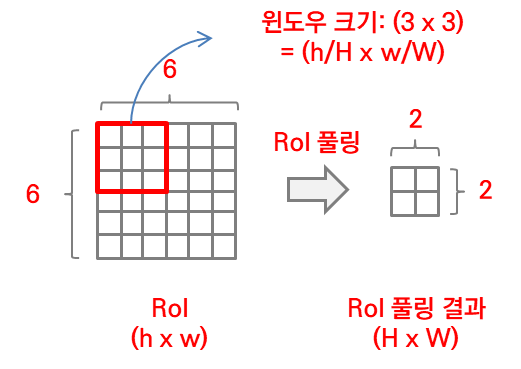
RoI 계층은 Spp-net에서 사용하는 spatial pyramid pooling 계층과 비슷합니다. spatial pyramid pooling 계층에 pyramid level이 딱 하나만 있는 경우로 볼 수 있습니다.
2.2 Initializing from pre-trained networks
Fast R-CNN도 이미지넷에서 사전 훈련된 네트워크를 뼈대로 사용합니다. 사전 훈련된 네트워크를 초기화할 때 세 가지 변형을 가합니다.
첫째, 마지막 풀링 계층을 RoI 풀링 계층으로 바꿉니다. 첫 번째 전결합 계층이 (H x W) 크기를 받을 수 있게 말이죠. 참고로, VGG16에서는 H = W = 7입니다.
둘째, 네트워크의 마지막 전결합 계층과 소프트맥스는 두 가지 계층으로 나눕니다. 1) {전결합 + 소프트맥스} 계층과 경계 박스 회귀 계층이죠.
<NOTE> 이미지 분류에서 사용하는 VGG16은 마지막 부분에 전결합 계층을 거쳐 소프트맥스를 적용합니다. 이미지를 분류만 하면 되기 때문이죠. 하지만 Fast R-CNN은 RoI 풀링 계층을 거친 후에 두 가지 분기로 나뉘는데, 이때 {전결합 + 소프트맥스} 계층과 경계 박스 회귀 계층으로 나뉜다는 말입니다.
셋째, 네트워크가 입력 데이터 두 개를 받도록 수정합니다. 이미지 데이터와 해당 이미지의 RoI 데이터를 받게끔 말이죠.
2.3 Fine-tuning for detection
역전파로 네트워크의 모든 가중치를 훈련할 수 있다는 점은 Fast R-CNN의 가장 큰 장점입니다. 먼저, SPP-net은 spatial pyramid 풀링 계층 이전의 가중치를 왜 업데이트하지 못하는지 설명해보겠습니다.
훈련 샘플, 즉 RoI를 서로 다른 이미지에서 구할 때는 SPP 계층을 통해 역전파를 적용하는 것이 굉장히 비효율적입니다. R-CNN과 SPP-net은 이런 방식으로 네트워크를 훈련합니다. 각 RoI가 굉장히 큰 receptive field를 갖기 때문에 비효율적입니다. RoI가 입력 이미지의 꽤 많은 영역을 차지하죠. 그렇기 때문에 거의 입력 이미지 전체를 훈련하는 꼴이 되어 버립니다.
연구진은 더 효율적인 훈련 방식을 제안합니다. 훈련하는 동안 피처를 공유하는 방식이죠. Fast R-CNN 훈련에서 SGD(stochastic gradient descent, 확률적 경사 하강법) 미니 배치가 샘플링됩니다. 먼저 N개 이미지를 샘플링하고, 이어서 샘플링한 각 이미지에서 R/N개 RoI를 샘플링합니다. 중요한 점은 같은 이미지에서 뽑은 RoI는 순전파와 역전파를 하면서 연산 결과와 메모리를 공유한다는 것입니다. N이 작을수록 미니 배치 연산은 줄어듭니다. 예를 들어, N = 2, R = 128이라고 해봅시다. 그러면 서로 다른 128개의 이미지에서 RoI 한 개를 뽑을 때보다 64배나 빠릅니다.
<NOTE> 2개(=N)의 이미지를 샘플링하여 각 이미지마다 RoI 64개(=R/N=128/2)를 샘플링하기 때문입니다. 128개를 샘플링하는 경우와 2개를 샘플링하는 경우의 속도 차이는 64배가 나겠죠. 2개의 이미지에서 64개의 RoI를 샘플링할 때는 RoI가 연산과 메모리를 공유하기 때문에 손실이 발생하지 않습니다.
게다가 Fast R-CNN은 소프트맥스 분류기, 경계 박스 회귀를 동시에 최적화하도록 한번에 파인 튜닝을 합니다(one-stage). R-CNN은 소프트맥스 분류기, SVM, 경계 박스 회귀를 따로따로 처리했죠(multi-stage).
Multi-task loss.
Fast R-CNN은 두 가지 출력 계층을 갖습니다. 첫 번째 계층은 RoI마다 (K+1)개 확률값을 출력합니다. K는 클래스 개수인데 배경까지 더해 (K+1)인 겁니다. 두 번째 계층은 경계 박스 좌표를 출력합니다. K개 객체마다 (좌상단 x좌표, 좌상단 y좌표, 너비, 높이)를 구해줍니다.
p = 예측 클래스 값, u = 실제 클래스 값, t = 예측 경계 박스 좌표, v = 실제 경계 박스 좌표라고 할 때 multi-task loss 수식은 다음과 같습니다.

①은 클래스 분류 손실값입니다. 로그손실로 계산합니다. ②는 경계 박스 회귀의 손실값입니다. 이때 ③ 아이버슨 괄호를 곱해줍니다. 아이버슨 괄호는 u가 1 이상일 땐 1, 1 미만일 땐 0을 반환하는 함수입니다. u=1은 객체가 있다는 뜻이고, u=0은 객체가 없다는 뜻입니다. 곧, u=0일 땐 배경이라는 이야기죠. 따라서 객체가 있을 때만 경계 박스 회귀 손실값이 필요하고 배경일 땐 필요 없습니다. ④는 클래스 분류 손실값과 경계 박스 회귀 손실값 사이의 균형을 맞춰주는 하이퍼파라미터입니다. 참고로, ② 경계 박스 회귀 손실값을 다음과 같이 구합니다.
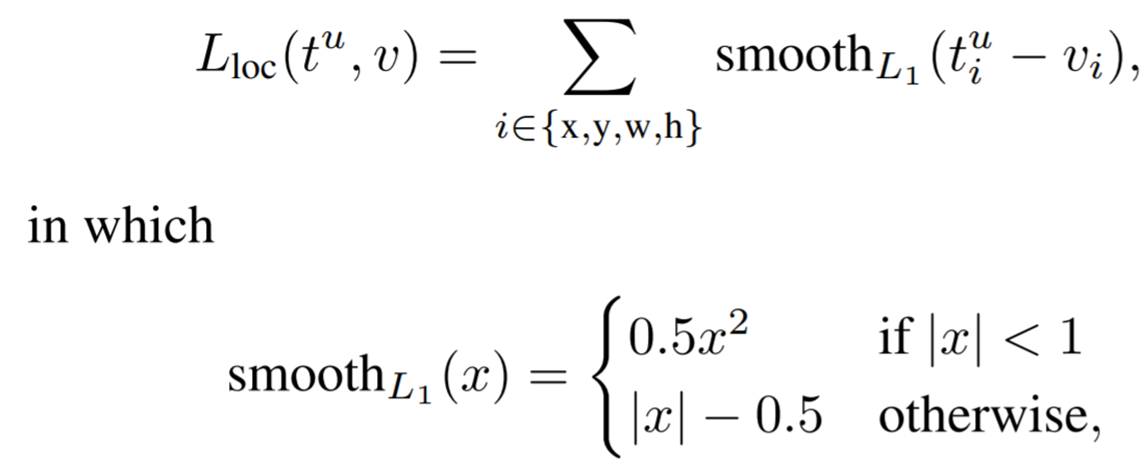
Mini-batch sampling.
파인 튜닝하는 동안 각 SGD 미니 배치는 N=2가 되게 이미지를 샘플링합니다. R=128이므로, 각 이미지마다 RoI를 64개 뽑습니다. 후보 영역에서 실제 경계 박스와 IoU 0.5 이상인 RoI를 25% 뽑습니다. 이 RoI를 positive 샘플로 간주합니다. 즉, u=1이라는 말입니다. 후보 영역에서 뽑은 나머지 RoI 중 실제 경계 박스와 IoU가 0.1 이상 0.5 미만인 RoI는 배경으로 간주합니다. negative 샘플로 간주한다는 뜻이죠. u=0입니다. 데이터 증강을 위해 훈련하는 동안 50% 확률로 좌우 대칭을 합니다. 이외에 다른 데이터 증강은 하지 않았습니다.
2.4 Scale invariance
스케일 불변(scale invariant)한 객체 탐지를 수행하기 위해 두 가지를 실험했습니다. (1) 'brute-force' 학습과 (2) 이미지 피라미드 방식입니다. brute-force 방식에서는 훈련과 테스트에서 모두, 각 이미지를 사전에 정의한 픽셀 크기로 처리합니다.
반면 이미지 피라미드 방식(multi-scale 방식)은 이미지 피라미드를 통해 스케일 불변성을 갖게 합니다. 사전에 정의한 크기로만 학습하는 게 아니라 여러 이미지 크기를 활용한다는 겁니다. 테스트 단계에서는 정규화된 후보 영역을 위해 이미지 피라미드를 사용합니다. 훈련 단계에서는 피라미드 스케일을 무작위로 뽑습니다. 데이터 증강 형식으로 말이죠. GPU 메모리 한계 때문에 작은 네트워크에서만 multi-scale 훈련을 했습니다.
3. Fast R-CNN detection
3.1 Truncated SVD for faster detection
이미지 분류 시 순전파를 할 때, 전결합 계층에서 소요하는 시간이 합성곱 계층에서 소요하는 시간 대비 상대적으로 짧습니다. 하지만 객체 탐지를 할 때는 그렇지 않습니다. 처리해야 할 RoI가 많기 때문에 전결합 계층에서 소요하는 시간이 거의 절반을 차지합니다. 다행히도 Truncated 특이값 분해(SVD)를 적용하면 전결합 계층에서 소요하는 시간이 훨씬 짧아집니다. 다음 그림은 Truncated SVD를 적용하기 전과 후의 각 계층별 순전파 소요 시간을 나타냅니다.
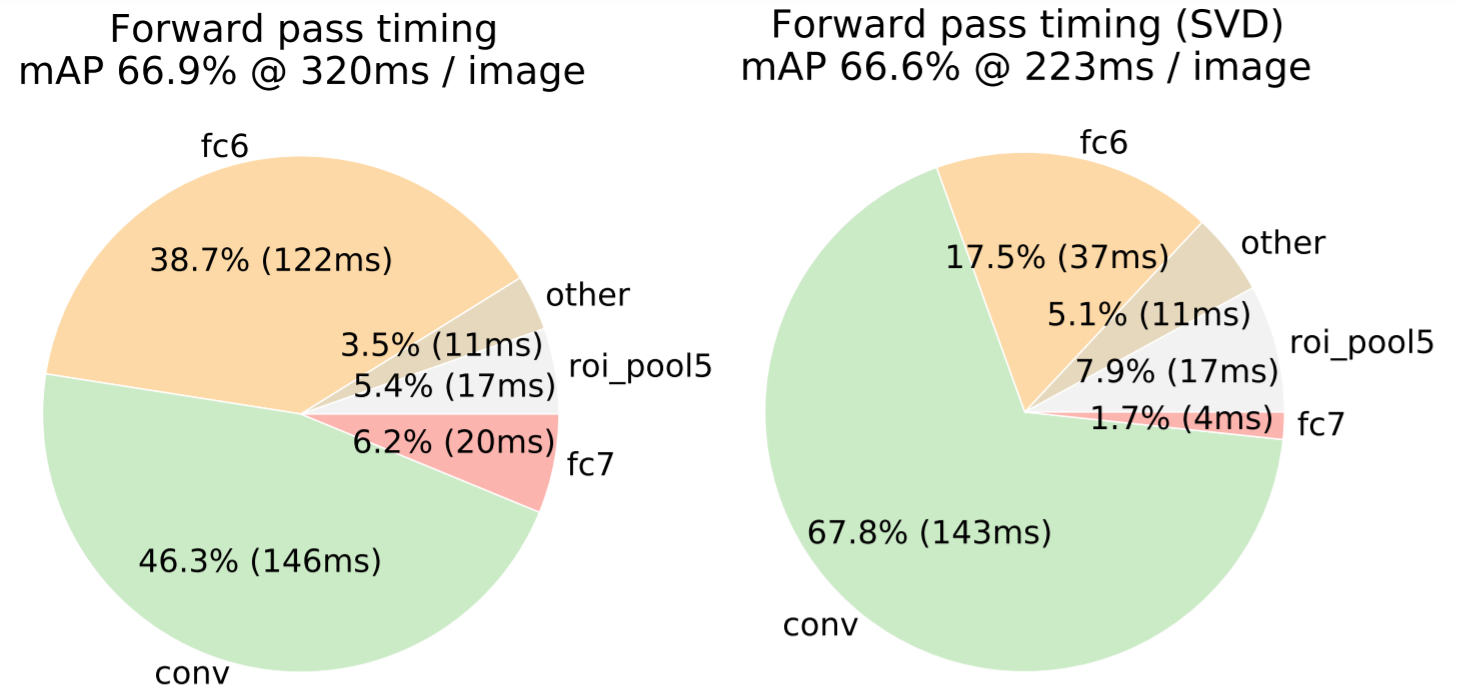
<NOTE> 특이값 분해에 관한 자세한 설명은 머신러닝 - 20. 특이값 분해(SVD)를 참고하세요.
4. Main results
Fast R-CNN의 성능과 속도가 얼마나 좋아졌는지 살펴보시죠.
4.2 ~ 4.3 VOC 2007, 2010 and 2012 results
다음 표는 기존 모델과 Fast R-CNN의 성능을 비교한 표입니다. 표에서 FRCN이 Fast R-CNN의 약자입니다.
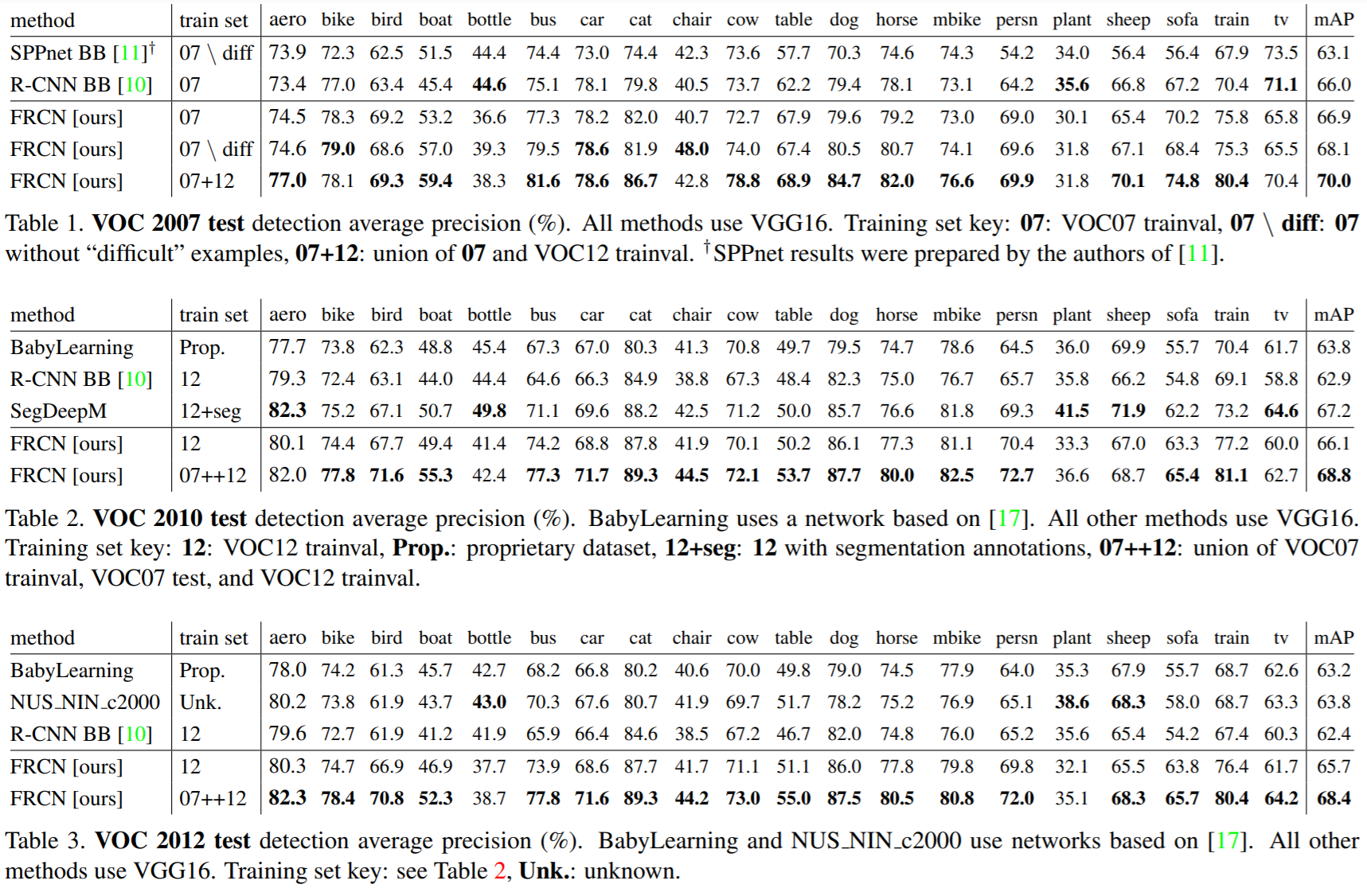
보다시피 Fast R-CNN이 다른 모델들보다 mAP가 더 좋습니다. 특히 데이터셋을 많이 사용할수록 mAP가 더 높아지네요.
4.4 Training and testing time
이번에는 Fast R-CNN의 속도를 살펴보시죠. 다음 표는 Fast R-CNN, R-CNN, SPP-net 간 속도를 비교한 표입니다. 훈련 시간(hours)과 테스트 속도(seconds per image), 그리고 mAP를 나타냅니다. S, M, L은 각각 small, medium, large의 약자로 모델의 크기를 의미합니다. S면 간단한 모델, L이면 복잡한 모델을 뜻하죠.
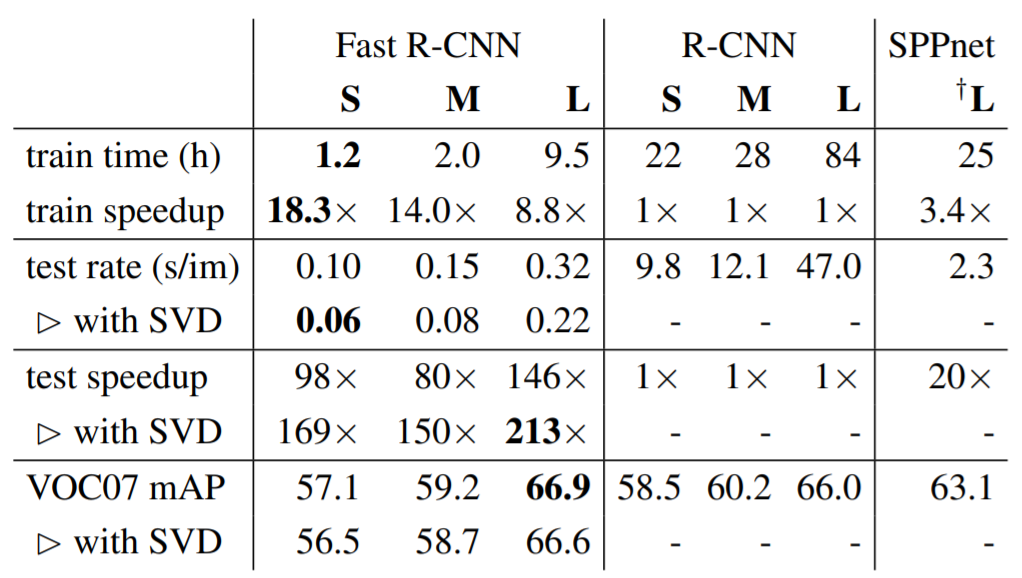
가령 Fast R-CNN(L)은 R-CNN보다 테스트 처리 속도가 146배 빠릅니다(SVD를 적용하지 않은 경우). SVD를 적용하면 213배나 더 빠르죠. 훈련 시간은 84시간에서 9.5시간으로 줄어듭니다. 게다가 Fast R-CNN은 피처를 공유하기 때문에 저장 공간도 수백 GB나 절약합니다.
4.5 Which layers to fine-tune?
SPP-net에서는 전결합 계층만 파인 튜닝해줘도 충분했습니다. Fast R-CNN보다 깊은 신경망이 아니기 때문이죠. 연구진은 Fast R-CNN이 꽤나 깊은 신경망이라서 파인 튜닝을 합성곱 계층까지 적용해보는 실험을 했습니다. 다음 표는 계층별 파인 튜닝에 따른 mAP 결과를 비교해놓은 표입니다. 참고로 네트워크는 VGG16입니다.

<NOTE> SPP-net은 전결합 계층만 파인 튜닝했는데 mAP가 63.1입니다. 반면 Fast R-CNN은 전결합 계층만 파인 튜닝할 경우 mAP가 SPP-net보다 낮은 61.4지만, conv2_1 이후 합성곱까지 파인 튜닝하면 67.2로 늘어납니다. conv3_1 이후 합성곱까지 파인 튜닝하면 mAP 66.9가 됩니다.
모든 합성곱 계층을 파인 튜닝하는 게 항상 좋다는 뜻일까요? 아닙니다. 크기가 작은 네트워크의 첫 번째 합성곱 계층(conv1)은 테스크와 무관합니다(task-independent).
<NOTE> 테스크와 무관하다는 말은 어떤 이미지를 분류하든 관계없이 파라미터가 같다는 말입니다. 곧, 고양이와 강아지를 구분하는 작업이든, 소와 말을 구분하는 작업이든 첫 번째 계층에서 수행하는 일은 같다는 의미입니다. 세세한 분류가 아니라 형상이나 선 등을 구분하는 일을 하는 데는 객체 종류와 상관없기 때문이죠.
그렇기 때문에 첫 번째 계층을 파인 튜닝하든 하지 않든 mAP에는 영향을 주지 않습니다. VGG16에서는 conv3_1 이후로 파인 튜닝을 하면 됩니다. (1) conv2_1 이후로 파인 튜닝하면 conv3_1 이후 파인 튜닝하는 것에 비해 훈련 속도가 1.3배 느려집니다(12.5 vs. 9.5 시간). 그리고 (2) conv1_1 이후로 파인 튜닝하면 GPU 메모리를 초과합니다. 게다가 conv2_1 이후로 파인 튜닝한 mAP는 conv3_1 이후 파인 튜닝한 mAP에 비해 겨우 0.3점 높습니다(66.9 → 67.2). 본 논문에서 사용한 모든 Fast R-CNN 결과는 VGG16의 conv3_1 이후로 파인 튜닝한 결과입니다. 또한 모든 작은 모델(S, M)은 conv2 이후로 파인 튜닝했습니다.
5. Design evaluation
Fast R-CNN을 이해하기 위해 PASCAL VOC 2007 데이터셋에서 실험해봤습니다.
5.1 Does multi-task training help?
multi-task 훈련은 편리합니다. task를 연속으로 훈련하는 파이프라인을 사용하지 않아도 되기 때문입니다. 또한, multi-task 훈련을 할 때는 합성곱 계층의 파라미터를 공유하기 때문에 성능이 더 좋아질 가능성도 있습니다. multi-task 훈련이 Fast R-CNN의 객체 탐지 성능을 높여줄까요?
이 질문에 답하려면 전체 손실에서 분류 손실만 남겨둔 상태로 베이스라인 네트워크를 훈련해봐야 합니다. 아래 수식이 전체 손실을 구하는 수식인데, 이 수식에서 λ=0으로 설정하면 ① 분류 손실만 남습니다.
이렇게 훈련한 베이스라인 모델을 아래 표에서 S, M, L로 표기했습니다.

각 그룹의 두 번째 열을 보시죠. 두 번째 열은 multi-task 손실(즉, 전체 손실 수식에서 λ=1로 설정한 경우)을 사용해 훈련한 모델을 나타냅니다. 단, 테스트 단계에서 경계 박스 회귀는 사용하지 않았고요. 이렇게 하면 multi-task 손실을 사용하지 않은 베이스라인 모델과 성능을 일대일로 비교할 수 있습니다. 보다시피 multi-task 훈련을 할 때가 그렇지 않을 때보다 mAP가 높습니다. mAP가 0.8 ~ 1.1까지 높아집니다. multi-task 훈련이 확실히 효과가 있다는 뜻이네요.
마지막으로, 분류 손실로만 훈련된 베이스라인 모델에 경계 박스 회귀 계층을 덧붙이고, ② 경계 박스 회귀 손실만을 사용해 훈련해봤습니다(그 외 다른 파라미터는 고정(frozen)함). 그 결과가 세 번째 열에 나타나 있습니다. 곧 stage-wise 훈련은 아무것도 하지 않은 베이스라인(첫 번째 열)보다는 성능이 좋지만 multi-task 훈련보다는 성능이 나쁩니다.
5.2 Scale invariance: to brute force or finesse?
스케일 불변한(scale-invariant) 객체 탐지를 위해 두 가지 기법을 비교해봤습니다. 무차별 대입 학습(brute-force learning)과 이미지 피라미드 기법입니다. 무차별 대입 학습은 단일 스케일(single scale) 훈련을 말하고, 이미지 피라미드 기법은 멀티 스케일(multi-scale) 훈련을 말합니다. 두 기법을 사용할 때, 이미지 너비와 높이 중 더 작은 값을 스케일 s로 정의합니다. 모든 단일 스케일(single-scale) 실험에서는 s=600 픽셀입니다. 다만, 너비 혹은 높이 중 긴 부분이 1,000 픽셀을 넘지 않도록 한도를 정하기 때문에, 그런 경우에는 s가 600 픽셀보다 작기도 합니다. 이 값은 GPU 메모리를 초과하지 않으면서 VGG16를 파인 튜닝하기에 적합한 값으로 정합니다.
PASCAL VOC 데이터셋 이미지는 평균적으로 384 x 473 크기입니다. 그래서 단일 스케일 훈련을 할 때는 1.6배 키워 사용합니다(384 * 1.6 = 약 600).
멀티 스케일 훈련을 할 때는 다섯 가지 s값을 사용합니다. s ∈ {480, 576, 688, 864, 1200}. SPP-net 논문에서도 사용한 값인데, SPP-net과 비교하기 위해 같은 값을 사용했습니다. GPU 메모리 초과를 방지하려고, 높이나 너비 중 긴 부분이 2,000 픽셀을 넘지 않도록 했습니다.
다음 표는 단일 스케일과 멀티(5개) 스케일로 훈련과 테스트를 한 모델 S와 M의 결과를 보여줍니다. L 모델은 GPU 메모리 한계로 멀티 스케일 훈련을 하지 못했습니다.
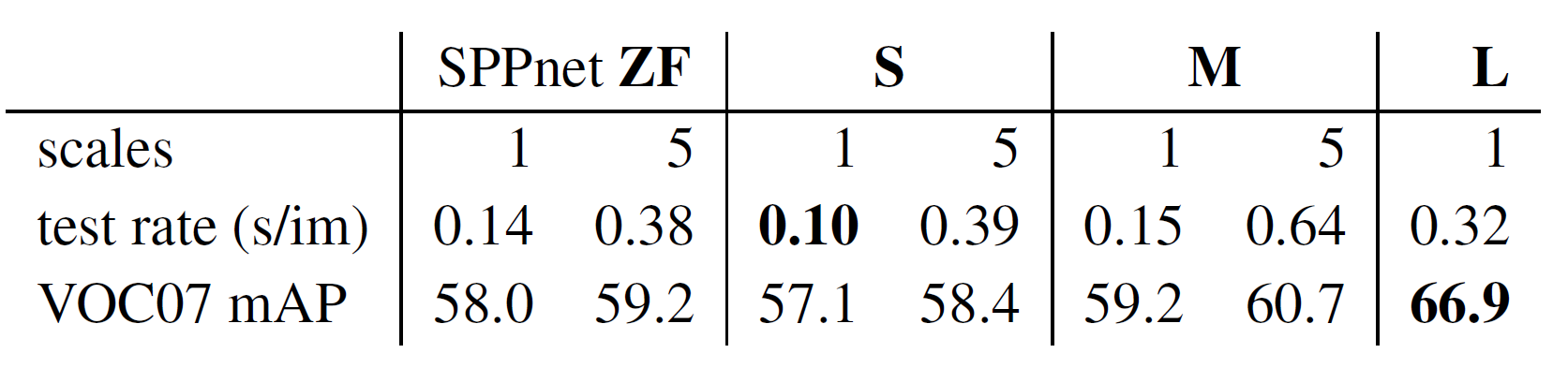
보다시피 단일 스케일과 멀티 스케일은 속도와 성능 간 트레이드오프(trade-off) 관계가 있네요. 멀티 스케일로 훈련하면 mAP는 조금 늘어나는데 비해 속도는 상대적으로 많이 느려집니다. 단일 스케일로 훈련한 모델 L은 66.9%의 mAP를 달성했습니다. R-CNN이 달성한 mAP 66.0%보다 높은 수치죠.
멀티 스케일이 속도가 느려지는 것 대비 성능 향상이 미미하기 때문에, 본 섹션 외에는 모두 단일 스케일로 훈련과 테스트를 합니다. s=600으로 잡고요.
5.3 Do we need more training data?
훈련 데이터가 많아지면 당연히 객체 탐지 성능이 좋아집니다. 성능 향상을 위해 PASCAL VOC 2007 훈련, 검증 데이터셋과 VOC 2012 훈련, 검증 데이터셋을 합쳐서 이미지를 늘려 훈련했습니다. 이렇게 훈련 데이터를 늘린 결과 mAP가 66.9%에서 70.0%로 향상됐습니다.
5.4 Do SVMs outperform softmax?
Fast R-CNN은 SVM 분류기 대신 소프트맥스 분류기를 사용합니다. R-CNN과 SPP-net에서는 SVM 분류기를 사용했죠. 다음은 SVM 분류기를 사용한 R-CNN과 SVM과 소프트맥스 분류기를 사용한 Fast R-CNN의 mAP를 비교한 표입니다. 서로 같은 환경에서 비교하려고 훈련 알고리즘이나 하이퍼파라미터는 동일하게 설정했습니다.
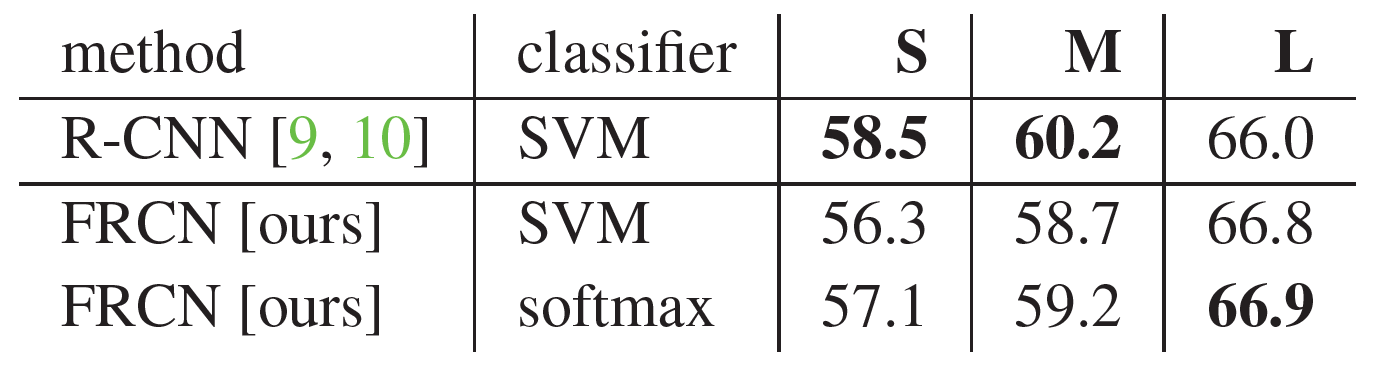
보다시피 소프트맥스 분류기를 사용한 경우에 SVM을 사용한 경우보다 mAP가 높네요. 작게는 0.1, 크게는 0.8까지 좋아집니다.
5.5 Are more proposals always better?
다음 그래프는 후보 영역 개수에 따른 mAP와 AR을 보여줍니다(VOC 2007 테스트 데이터셋에서 실험).
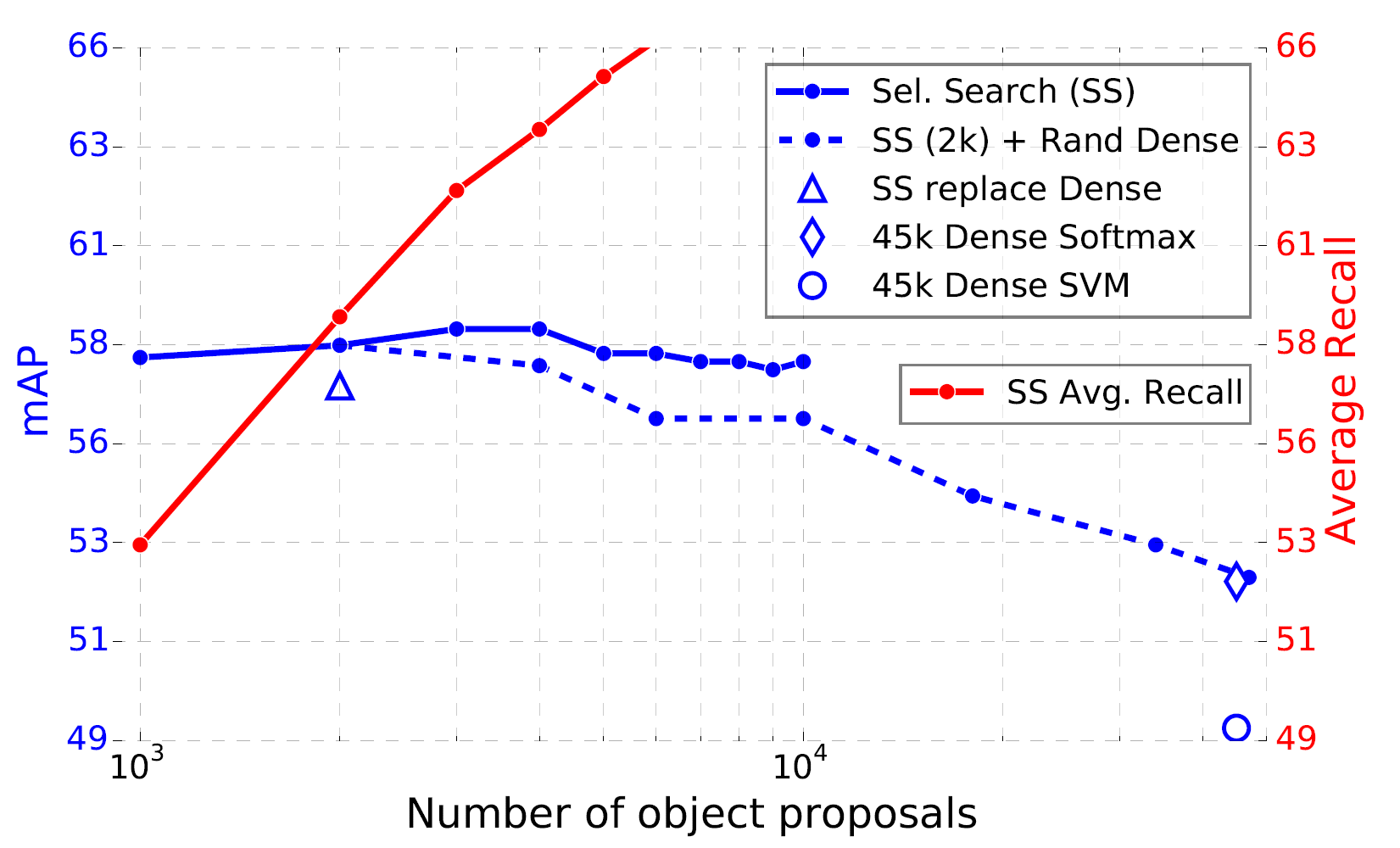
후보 영역이 많을수록 mAP는 대개 좋아집니다. 그러나 과하게 많으면 오히려 mAP가 조금씩 떨어집니다. 실제 실험해보기 전까진 후보 영역이 얼마나 많아야 성능이 최고로 좋아지는지 알 수는 없습니다. 또한, 위 그래프에서 보다시피 AR이 높다고 mAP가 반드시 비례해서 높아지지는 않습니다.
6. Conclusion
본 논문에서는 Fast R-CNN을 제안했습니다. R-CNN과 SPP-net을 개선한 모델이죠. 최신(state-of-the-art) 객체 탐지 모델을 제시하기도 했지만, 여러 실험을 통해 새로운 인사이트도 제시했습니다.
'논문 리뷰' 카테고리의 다른 글
| 논문 리뷰 - SSD(Single Shot MultiBox Detector) 톺아보기 (0) | 2022.03.30 |
|---|---|
| 논문 리뷰 - Faster R-CNN 톺아보기 (0) | 2022.03.17 |
| 논문 리뷰 - SPP-net 톺아보기 (0) | 2022.02.26 |
| 논문 리뷰 - R-CNN 톺아보기 (7) | 2022.02.02 |
| 논문 리뷰 - YOLO(You Only Look Once) 톺아보기 (17) | 2020.10.14 |



