
귀퉁이 서재
머신러닝 - 16. NGBoost 본문

앤드류 응 교수가 속해있는 스탠퍼드 ML Group에서 최근 새로운 부스팅 알고리즘을 발표했습니다. 머신러닝의 대가인 앤드류 응 교수의 연구소에서 발표한 것이라 더 신기하고 관심이 갔습니다. 2019년 10월 9일에 발표한 것으로 따끈따끈한 신작입니다. 이름은 NGBoost(Natural Gradient Boost)입니다. Natural Gradient이기 때문에 NGBoost지만 Andrew Ng의 NG를 따서 좀 노린 것 같기도 하네요.. 엔쥐부스트라 읽어야 하지만 많은 혹자들이 앤드류 응 교수의 이름을 따서 응부스트라 읽을 것 같기도 합니다.
어쨌든 다시 본론으로 넘어가면, 지금까지 부스팅 알고리즘은 XGBoost와 LightGBM이 주름잡았습니다. 캐글의 많은 Top Ranker들이 XGBoost와 LightGBM으로 좋은 성적을 내고 있습니다. NGBoost도 그와 비슷한 명성을 갖게 될지는 차차 지켜봐야겠죠.
이번 글은 NGBoost 논문과 홈페이지 그리고 Towards Data Science의 글을 참고하여 작성했습니다.
State of the art
XGBoost Gihub의 Star는 17.6k 개인데 비해 NGBoost Github의 Star는 아직 196개입니다. 제가 Star를 하나 눌러서 197개가 됐습니다. 커밋 이력도 3,929개와 194개로 비교가 되는군요. NGBoost는 이 글을 쓰는 시점을 기준으로 불과 2일 전에 커밋된 것도 있습니다. 아직도 모델을 개발 중이라는 것을 알 수 있습니다. 기본적으로 GBM에 있는 early_stopping, random_state 옵션이 NGBoost에는 아직 없습니다. 이 글을 쓰는 시점에는 없지만 머지않아 업데이트가 될 거라 생각합니다.


유튜브에서 검색해볼까요?
관련 없는 영상 하나만 검색될 뿐 NGBoost가 전혀 검색이 되지 않습니다. 조만간 NGBoost 관련 영상이 많이 올라오겠죠.
NGBoost 특징
1. NGBoost는 XGBoost나 LightBoost보다 성능이 조금 더 좋습니다.
Kaggle의 집값 예측 데이터를 활용하여 테스트해봤을 때 NGBoost가 XGBoost나 LightGBM보다 성능이 조금 더 좋았습니다. (Reference1)

2. 확률적인 예측을 해줍니다. (예측의 불확실성을 측정해줍니다.)
확률적 예측이란 말그대로 예측을 확률에 기반해서 한다는 뜻입니다. 여러 feature를 기반으로 집 값을 예측한다고 합시다. 일반적인 모델을 활용하면, '집의 위치, 주변 환경, 평수, 건축 연도 등을 고려해 5억이다'라고 예측을 할 것입니다. 예측은 언제나 불확실성을 내포합니다. 사용한 모델이 5억이라고 예측했을 때 신뢰성이 얼마나 되는지 알 수 없습니다. 하지만 NGBoost는 예측의 불확실성까지 알려줍니다. '집의 위치, 주변 환경, 평수, 건축년도 등을 고려해 5억 일 확률은 75%다'라고 말이죠. 예측의 불확실성을 측정하는 것은 의료나 날씨 분야에 있어 중요합니다.
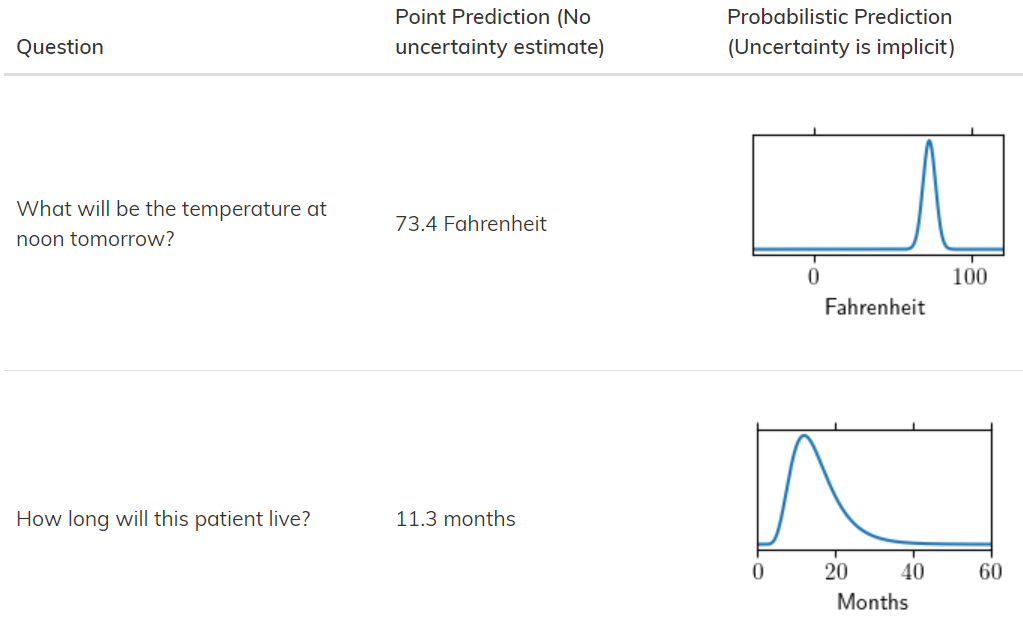
기존의 모델에게 '내일 날씨가 몇도일 것 같니?'라고 물어보면 '73.4도(화씨)입니다.'라고 대답합니다. 하지만 NGBoost는 응답에 대한 확률 분포를 보여줄 수 있습니다. 73.4도일 확률은 몇 프로고 72.4도일 확률은 몇 프로고.. 등등으로 말입니다.
아래는 NGBoost로 학습시킨 확률 회귀 선입니다.

두꺼운 선은 예측 값의 평균이며, 가는 선은 95% 확률 예측 구간입니다. 가는 선 사이에 예측 값이 있을 확률이 95% 이상이라는 것입니다. 앞서 말씀드린 바와 같이 NGBoost는 확률적 예측을 가능케 합니다.
3. XGBoost, LightGBM보다 컴퓨팅 시간이 오래 걸립니다.
유일한 단점입니다. 성능도 좋고, 결과값에 대한 확률 분포까지 보여주려니 시간이 많이 걸리는 건 당연지사겠죠. 샘플링을 통해 시간을 줄여줄 수 있겠습니다.
NGBoost 구성

NGBoost는 위 그림과 같이 Base Learners, Probability Distribution, Scoring Rule로 구성되어 있습니다.
Base (Weak) Learner
가장 기본적인 학습기는 결정트리(Decision Tree)입니다.
Probability Distribution
Input을 받아 약학습기(Weak Learner)로 예측한 결과 활용하여 확률 분포를 만듭니다. 확률 분포는 결괏값(Target Value)의 타입에 따라 바뀔 것입니다. 일상생활에 대한 값이라면 정규 분포를, Binary값이라면 베르누이 분포를 따라야 합니다.
Scoring Rule
예측한 확률 분포와 실제 Target Value를 토대로 성능 측정을 합니다. 성능 측정을 위한 알고리즘은 MLE(Maximum Likelihood Estimation)이나 Continuous Ranked Probability Score(CRPS)를 주로 씁니다.
위 단계를 반복하며 성능을 높여갑니다.
NGBoost의 내부적인 알고리즘은 저도 정확히 이해하지 못했습니다. NGBoost의 특징과 간단한 구성요소에 대해서만 알아봤고 시간이 허락할 때 논문 전체를 읽어볼 예정입니다.
References
Reference1: Towards Data Science (NGBoost Explained)
Reference2: Standford ML Group (NGBoost: Natural Gradient Boosting for Probabilistic Prediction)
Reference3: NG Boost 논문 (Natural Gradient Boosting for Probabilistic Prediction)
'머신러닝' 카테고리의 다른 글
| 머신러닝 - 18. 선형판별분석(LDA) (0) | 2020.01.01 |
|---|---|
| 머신러닝 - 17. 회귀 평가 지표 (8) | 2019.12.06 |
| 머신러닝 - 15. 그레디언트 부스트(Gradient Boost) (40) | 2019.10.23 |
| 머신러닝 - 14. 에이다 부스트(AdaBoost) (19) | 2019.10.04 |
| 머신러닝 - 13. 파라미터(Parameter)와 하이퍼 파라미터(Hyper parameter) (12) | 2019.09.27 |



