
귀퉁이 서재
머신러닝 - 14. 에이다 부스트(AdaBoost) 본문

본 챕터에서는 부스팅 기법 중 가장 기본이 되는 AdaBoost에 대해 알아보겠습니다. 부스팅에 대해서 잘 모르신다면 '머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)'을 참고해주시기 바랍니다.
아래 AdaBoost는 StatQuest의 AdaBoost, Clearly Explained를 요약 정리한 글입니다.
AdaBoost 개요
아래와 같이 노드 하나에 두개의 리프(leaf)를 지닌 트리를 stump라고 합니다.

AdaBoost는 아래와 같이 여러 개의 stump로 구성이 되어있습니다. 이를 Forest of stumps라고 합니다.
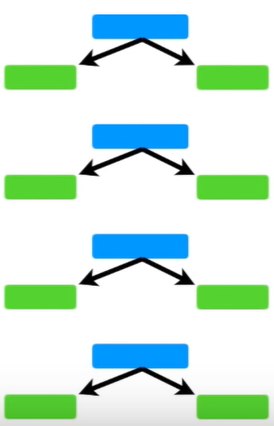
트리와 다르게 stump는 정확한 분류를 하지 못합니다. 여러 질문을 통해 데이터를 분류하는 트리와 다르게, stump는 단 하나의 질문으로 데이터를 분류해야하기 때문입니다. 따라서 stump는 약한 학습기(weak learner)입니다.
이전 챕터에서 살펴봤던 랜덤 포레스트는 여러 개의 트리의 결과를 합산해서 최종 결과를 냅니다. 다수결의 원칙을 통해 말이죠. 최종 분류를 하는데 있어 각각의 트리는 동등한 가중치를 가지고 있습니다.
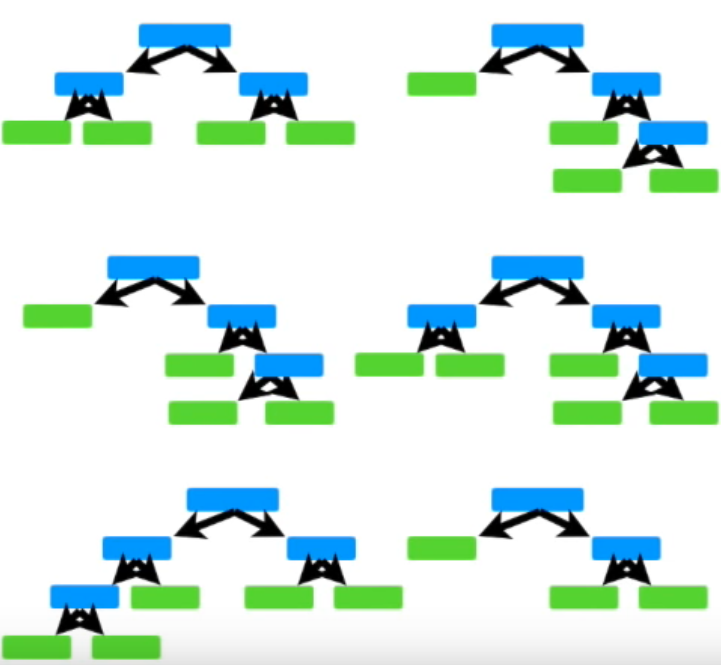
하지만 AdaBoost에서는 특정 stump가 다른 stump보다 더 중요합니다. 즉, 더 가중치가 높습니다. 아래의 그림에서 보는 것처럼 크기가 큰 것은 가중치가 더 높은 stump를 뜻합니다. 여기서 가중치가 높다는 것을 Amount of Say가 높다고 표현합니다. 결과에 미치는 영향이 크다는 뜻입니다.
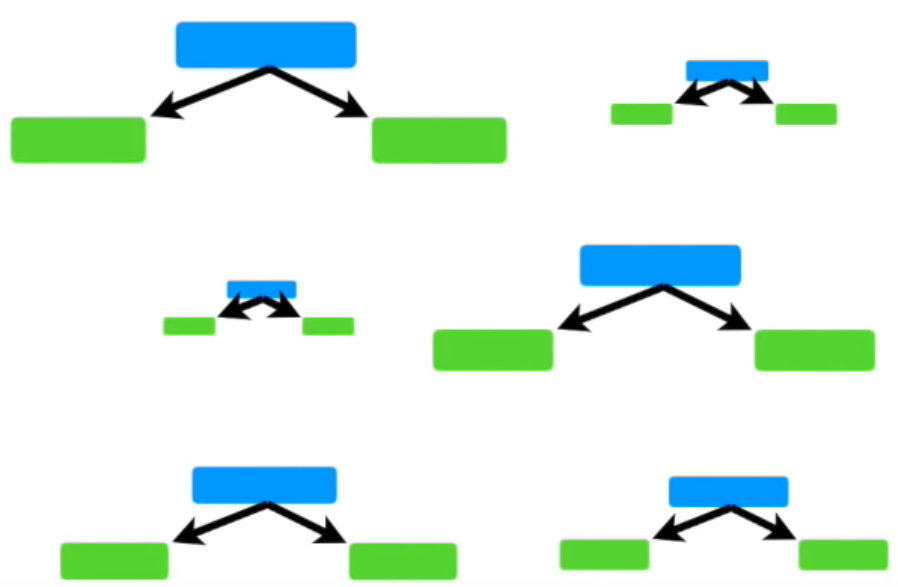
또한, 첫번째 Stump에서 발생한 error는 두번째 Stump의 결과에 영향을 줍니다. 두번째 Stump에서 발생한 error 역시 세번째 Stump의 결과에 영향을 줍니다. 그렇게 마지막 Stump까지 줄줄이 영향을 줍니다.
정리하자면, AdaBoost는 다음과 같은 3가지 특징을 가지고 있습니다.
1. 약한 학습기 (Weak Learner)로 구성되어 있으며, 약한 학습기는 Stump의 형태입니다.
2. 어떤 Stump는 다른 Stump보다 가중치가 높습니다. (Amount of Say가 큽니다.)
3. 각 Stump의 error는 다음 Stump의 결과에 영향을 줍니다.
AdaBoost 작동 원리
이제, AdaBoost의 작동 원리에 대해서 알아보겠습니다.

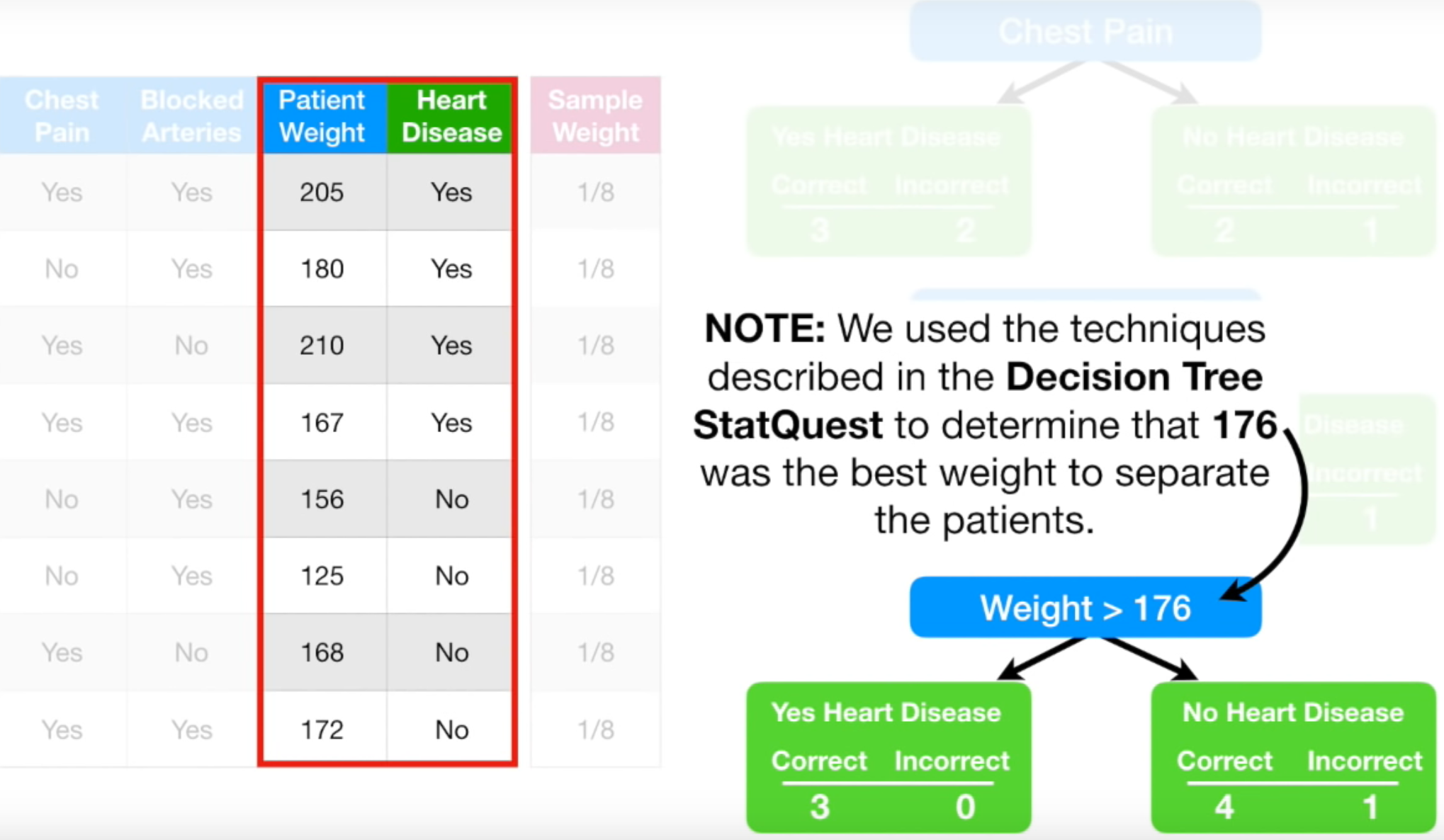
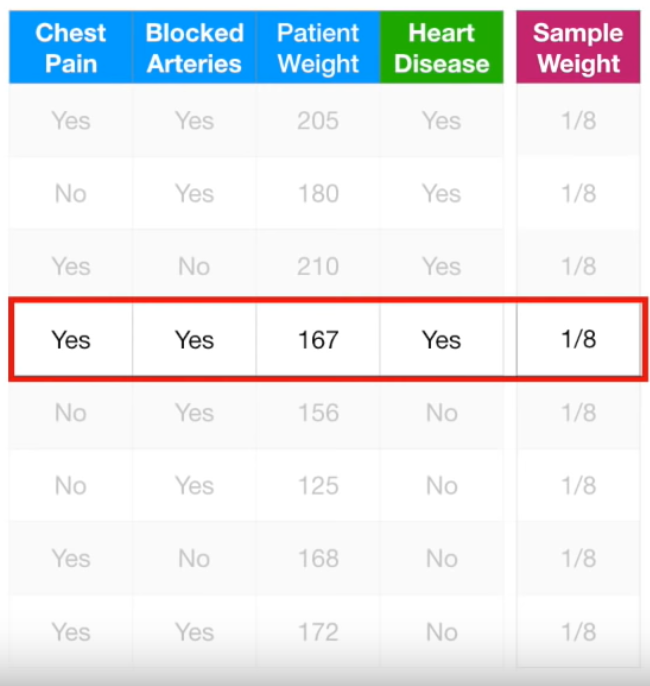
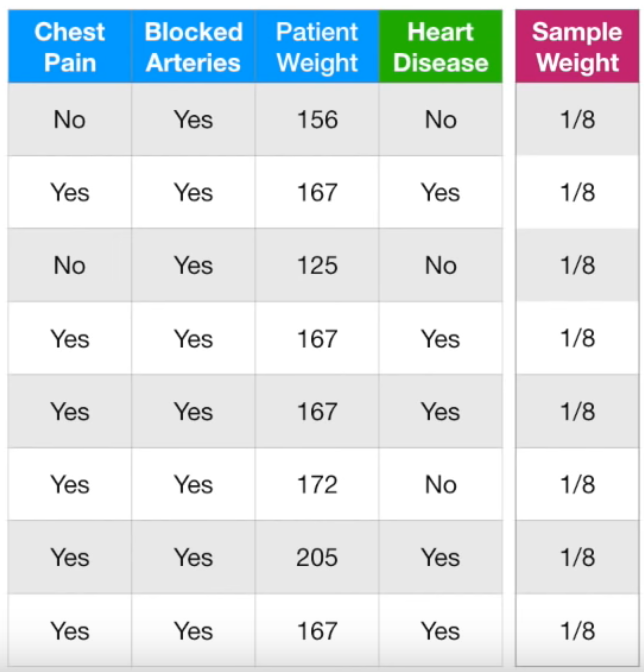
Chest Pain, Blocked Arteries, Patient Weight에 따른 Heart Disease 여부에 대한 데이터입니다. 맨 처음 Sample Weight는 8개의 데이터 모두 동일하게 1/(total number of samples) = 1/8입니다. 모든 sample의 가중치가 1/8로 동일합니다. 이제 각각의 feature가 target value(여기서는 Heart Disease)에 미치는 영향에 대해 살펴보겠습니다.
다음은 Chest Pain과 Heart Disease와의 관계입니다.

단순하게, Chest Pain이 Yes이면 Heart Disease도 Yes라고 판단하는 모델입니다. 총 8개의 데이터 중 Chest Pain이 Yes인 데이터(즉, Heart Disease를 Yes라고 판단한 데이터)는 5개, No인 데이터는 3개입니다. Heart Disease를 Yes라고 판단한 것 중 올바르게 판단한 것은 3개, 틀리게 판단한 것은 2개입니다. 반대로, Heart Disease를 No라고 판단한 것 중 올바르게 판단한 것은 2개, 틀리게 판단한 것은 1개입니다. 따라서 위와 같이 구분이 되었습니다. 참고로 여기서는 모든 Sample Weight가 1/8로 같아서, Sample Weight를 무시해도 됩니다. Sample Weight에 관해서는 다음 단계에서 활용합니다.
이젠, Blocked Arteries와 Heart Disease와의 관계입니다.

마지막으로, Patient Weight와 Heart Disease와의 관계입니다.
이제 각 Stump의 지니 계수를 구합니다.
참고로, 이때 Weight>176을 분기 기준으로 했습니다. 1) 몸무게를 오름차순으로 정렬한 뒤, 2) 인접한 몸무게의 평균을 구한 다음, 3) 각 평균 값마다 지니 불순도를 계산합니다. 4) 가장 작은 지니 불순도를 갖는 인접 몸무게 평균값을 분기 기준으로 잡은 겁니다. 그 값이 176입니다. 이 설명이 헷갈린다면 StatQuest: Decision Trees영상을 14:04초부터 보시기 바랍니다.

마지막 Stump의 지니 계수가 가장 작기 때문에, 마지막 Stump를 forest의 첫 Stump로 지정합니다. 이 Stump가 최종 결과 예측에 얼마만큼 중요한지 알아보겠습니다.
Amount of Say 구하기
바로 위 그림에서 틀리게 분류한 것이 No Heart Disease의 Incorrect로 1개밖에 없습니다. 따라서 Total Error = 1/8입니다.
모든 Sample Weights의 합은 1이기 때문에, Total Error는 0과 1 사이의 값을 갖습니다. Total Error가 Amount of Say를 결정합니다. Amount of Say는 최종 분류에 있어서 해당 Stump가 얼마만큼의 영향을 주는가를 뜻합니다. Amount of Say를 구하는 공식은 아래와 같습니다.
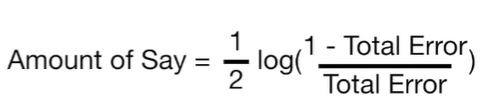
Amount of Say를 그래프로 그려보면 아래와 같습니다. X축은 Total Error, Y축은 Amount of Say입니다. Total Error가 0이면 Amount of Say는 굉장히 큰 양수이고, Total Error가 1이면 Amount of Say는 굉장히 작은 음수가 됩니다. 따라서 Total Error가 0이면 항상 올바른 분류를 한다는 뜻이고, 1이면 항상 반대로 분류를 한다는 뜻입니다. Total Error가 0.5일 때는 Amount of Say가 0입니다. 동전을 던지는 것과 마찬가지로 의미가 없다는 뜻입니다.
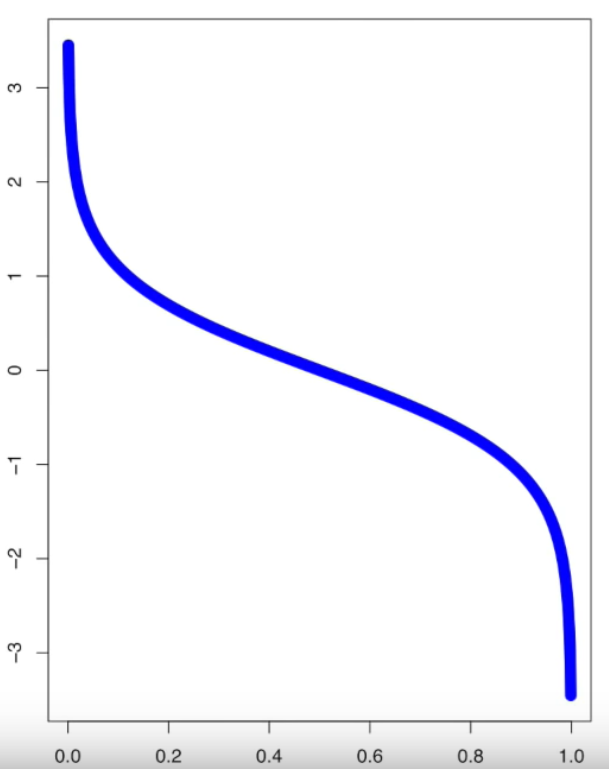
다시 Stump 문제로 돌아가보겠습니다. Total Error = 1/8이라고 했으므로,

= 0.97입니다. 그래프 상에서 표현해보면, Total Error가 1/8이고, Amount of Say = 0.97인 아래 지점입니다.

Chest Pain Stump의 Amount of Say를 구하는 방법입니다. 사실 이 단계는 할 필요가 없지만 Amount of Say를 구하는 방법을 다시 한번 설명하려고 추가했습니다.

이 Stump의 Total Error = 1/8 + 1/8 + 1/8 = 3/8입니다. Amount of Say를 구해보면,

= 0.42입니다.
Blocked Arteries도 동일한 방식으로 Amount of Say를 구해줄 수 있습니다.
샘플 가중치 설정
Adaboost에서는 하나의 Stump가 잘못 분류한 sample에 대해서는 다음 Stump로 넘겨줄 때 가중치를 더 높여서 넘겨줍니다. 그래야 다음 Stump에서 해당 Sample에 더 집중해서 올바로 분류해주기 때문입니다. 맨 처음 Weight Stump에서는 아래 빨간 네모 안에 있는 sample만 잘못 분류했습니다. 따라서 해당 sample의 weight를 1/8보다 크게 하고, 나머지 sample의 weight는 1/8보다 작게 해서 다음 Stump로 넘겨줍니다. 다음 Stump로 넘겨줄 때의 새로운 sample weight를 구하는 공식은 아래와 같습니다. (이전 Stump에서 잘못 분류된 sample인 경우)

(이전 stump에서 잘못 분류된 sample의) New Sample Weight = (1/8) * e^(0.97) = (1/8) * 2.64 = 0.33 입니다. 기존의 sample weight = 1/8 = 0.125였는데 이보다 더 높아졌습니다.
이전 Stump에서 잘 분류된 sample인 경우의 새로운 sample weight 구하는 공식은 아래와 같습니다.

amount of say에 - 부호만 붙이면 됩니다.
(이전 stump에서 잘 분류된 sample의) New Sample Weight = (1/8) * e^(-0.97) = (1/8) * 0.38 = 0.05 입니다. 기존의 weight인 0.125보다 더 작아졌습니다.
다시 설명하자면, 이전 Stump에서 잘못 분류한 sample에는 sample weight를 높여주고, 이전 Stump에서 제대로 분류한 sample에는 sample weight를 줄여줍니다. 그래야 다음 Stump에서 이전 Stump에서 잘못 분류한 것에 더 집중해서 올바로 분류해주기 때문입니다. 새로 구한 sample weight는 아래와 같습니다.
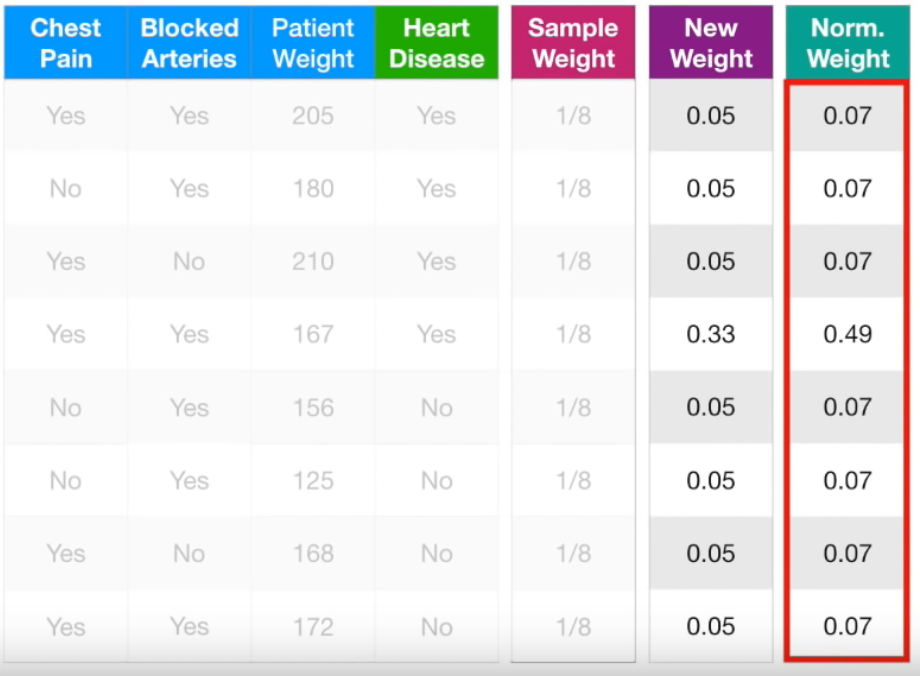
New Sample Weight는 공식에 의해 구한 weight입니다. 단, New Sample Weight를 다 더했을 때 값은 0.68로 1이 되지 않습니다. Sample Weight의 합은 항상 1이 되어야 하므로 오른쪽 Weight처럼 정규화해줍니다. 정규화하는 방법은 각 Weight를 모든 Weight의 합으로 나누어주는 것입니다.
0.05 / 0.68 = 0.07 입니다. 그리하여 정규화한 Weight를 맨 오른쪽에 적었습니다. 이제 기존 Weight는 모두 지우고 정규화한 새로운 Weight만 보겠습니다.

그다음 단계는 샘플링으로 새로운 테이블을 만드는 것입니다. 0부터 1까지 숫자를 무작위로 뽑습니다. 이때 0~0.07 사이의 숫자가 나오면 첫번째 sample을 선택합니다. 0.07~0.14 사이의 숫자가 나오면 두번째 sample을 선택합니다. 0.14~0.21 사이의 숫자가 나오면 세번째 sample을 선택합니다. 0.21~0.70 사이의 숫자가 나오면 네번째 sample을 선택합니다. 눈치 채셨겠지만 sample weight의 누적값에 해당하는 sample을 뽑는 것입니다. 그렇게 원래 테이블의 sample수와 똑같은 sample 수를 가진 새로운 테이블을 구성합니다. 뽑힌 sample들을 보니 중복되는 것도 있습니다. 원래 테이블에서 sample weight가 0.49인 sample이 4번이나 뽑혔습니다. 당연히 0.21 ~ 0.70 사이의 숫자가 나올 확률이 크니, 해당 sample도 많은 겁니다.

이제 원래 테이블은 지우고, 샘플링한 새로운 테이블을 가져옵니다. 모든 sample의 weight는 다시 1/8로 통일합니다. 첫 Stump에서 잘못 분류했던 sample이 4번이나 포함된다고 했습니다. sample weight는 1/8로 동일하더라도 똑같은 데이터가 4개가 있어서 실제로는 4/8의 weight를 갖는 것입니다. 이는 처음에 잘못 분류를 했기 때문에, 그다음에는 weight를 높여서 제대로 분류하기 위함입니다. weight가 높아지니 해당 sample에 가중치를 더 두고 분류를 할 것입니다.
다시 맨 처음했던 것과 같은 방식으로 진행하면 됩니다.
최종 분류
이렇게 여러 차례 진행하면 아래와 같이 각 Stump마다의 Amount of Say가 나옵니다. 왼쪽은 Heart Disease가 있다고 판단한 Stump이고, 오른쪽은 Heart Disease가 없다고 판단한 Stump라고 합시다. 각 Stump의 Amount of Say를 더하면 Total Amount of Say가 나옵니다. 이 경우 Heart Disease가 있다는 것의 Total Amount of Say가 2.7로 더 큽니다(0.97+0.32+0.78+0.63 = 2.7). 따라서 최종적으로 Heart Disease가 있다고 분류를 할 수 있습니다.

각 Stump마다 분류를 해주지만 Stump 하나의 분류력은 굉장히 약합니다. 앞서 말씀드린 것처럼 Stump는 Weak Learner입니다. 하지만 여러 Stump의 결과를 종합하면 강한 학습기(Strong Learner)가 됩니다. 또한, 각 Stump 마다 Amonut of Say가 다릅니다. 각 Stump의 Amount of Say를 합치면 Total Amount of Say가 나오고 이를 통해 최종 분류를 해주는 것입니다.
Reference
'머신러닝' 카테고리의 다른 글
| 머신러닝 - 16. NGBoost (16) | 2019.11.01 |
|---|---|
| 머신러닝 - 15. 그레디언트 부스트(Gradient Boost) (40) | 2019.10.23 |
| 머신러닝 - 13. 파라미터(Parameter)와 하이퍼 파라미터(Hyper parameter) (12) | 2019.09.27 |
| 머신러닝 - 12. 편향(Bias)과 분산(Variance) Trade-off (0) | 2019.09.13 |
| 머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting) (12) | 2019.09.12 |



