
귀퉁이 서재
컴퓨터 비전 - 14. 스타일 전이(Style Transfer) 본문

이번 포스팅에서는 스타일 전이(Style Transfer)의 원리를 알아보고, 코드로 실습까지 해보겠습니다.
스타일 전이(Style Transfer)의 원리
1. 스타일 전이란?
스타일 전이란 콘텐츠 이미지(content image)에 스타일 이미지(style image)의 화풍을 적용해 새로운 이미지를 생성하는 기법을 말합니다. 아래 예시를 보시죠.

원본 이미지인 A(이를 콘텐츠 이미지라고 부름)를 기준으로 각 화풍(이를 스타일 이미지라고 부름)에 맞게 스타일을 적용해 새로운 이미지를 만든 예시들입니다. 반 고흐의 작품이나 뭉크의 작품의 스타일을 적용해서 새로운 이미지를 만들었죠.
스타일 전이는 어떤 원리로 동작하는지 알아봅시다.
먼저, 스타일 전이를 적용하려면 사전 훈련된(pre-trained) CNN 모델을 사용해야 합니다. Style Transfer 논문에서는 VGG19 네트워크를 사용했습니다. 스타일 전이 훈련 시에는 VGG19 네트워크의 가중치는 고정한 뒤 이미지의 픽셀을 직접 변경하면서 훈련합니다. 모델 훈련이라고 하면 일반적으로는 가중치를 업데이트하는 걸 말합니다. 하지만 스타일 전이에서는 가중치는 고정한 채, 이미지의 픽셀을 변경하면서 업데이트를 합니다. 다시 말해 아래와 같은 방식으로 훈련이 됩니다.

맨 처음 랜덤 노이즈 이미지에서 시작해서 이미지의 픽셀을 업데이트합니다. 목표가 되는 타깃 이미지는 고양이 이미지입니다. 원본 고양이 이미지와 랜덤 노이즈 이미지 사이의 손실값을 구해, 손실값이 줄어드는 방향으로 랜덤 노이즈 이미지의 픽셀을 업데이트합니다. 이러한 방식으로 훈련하면 노이즈 이미지로부터 원본 이미지를 생성해낼 수 있습니다.
이때 노이즈 이미지에서 원본 이미지를 생성해내면서, 동시에 스타일 이미지에서 화풍(스타일)을 받아올 수 있습니다. 곧, '랜덤 노이즈와 원본 콘텐츠 이미지 사이의 손실값', '랜덤 노이즈와 스타일 이미지 사이의 손실값'을 동시에 고려해 이미지를 업데이트합니다. 이게 바로 스타일 전이의 프로세스입니다.
2. 손실함수
아래는 스타일 전이 기법에서 사용하는 손실함수입니다.

랜덤 노이즈 이미지(x)는 콘텐츠 이미지(p)와 스타일 이미지(a)를 결합해 새로운 이미지(result x)를 생성합니다. 우선 이미지는 행과 열로 구성돼 있습니다. 그렇지만 계산을 쉽게 하기 위해 하나의 이미지를 하나의 벡터로 표현합니다(p, a, x 등). 그냥 행, 열을 일렬로 쭉 나열해 벡터로 표현했다고 보면 됩니다.
노이즈 이미지에서 시작해 콘텐츠 정보와 스타일 정보를 모두 가져오면서 훈련을 합니다. 여기서 콘텐츠 손실(L_content)이 줄어든다는 건 콘텐츠의 이미지를 잘 가져왔다는 뜻이고, 스타일 손실(L_sytle)이 줄어든다는 건 스타일의 화풍을 잘 가져왔다는 말입니다. α는 콘텐츠 손실의 가중치, β는 스타일 손실의 가중치입니다. 각 가중치가 클수록 해당 손실값을 더 중요하게 여깁니다. 콘텐츠 손실의 가중치(α)와 스타일 손실의 가중치(β) 비율에 따라 생성되는 이미지가 다르다는 말입니다. 다시 말해 α가 클수록 콘텐츠의 이미지를 잘 복원합니다.

왼쪽 상단 그림의 가중치 비율(α / β)은 10^-4입니다. 스타일 손실 가중치(β)가 콘텐츠 손실 가중치(α)보다 10,000배 크다는 뜻이죠. 스타일 손실의 가중치가 크면 클수록 원본 콘텐츠를 확인하기 어렵네요.
스타일 전이 네트워크의 전체 손실은 (콘텐츠 손실 + 스타일 손실)입니다. 그럼 콘텐츠 손실과 스타일 손실 각각을 자세히 살펴보죠.
먼저, 콘텐츠 손실은 아래와 같습니다.
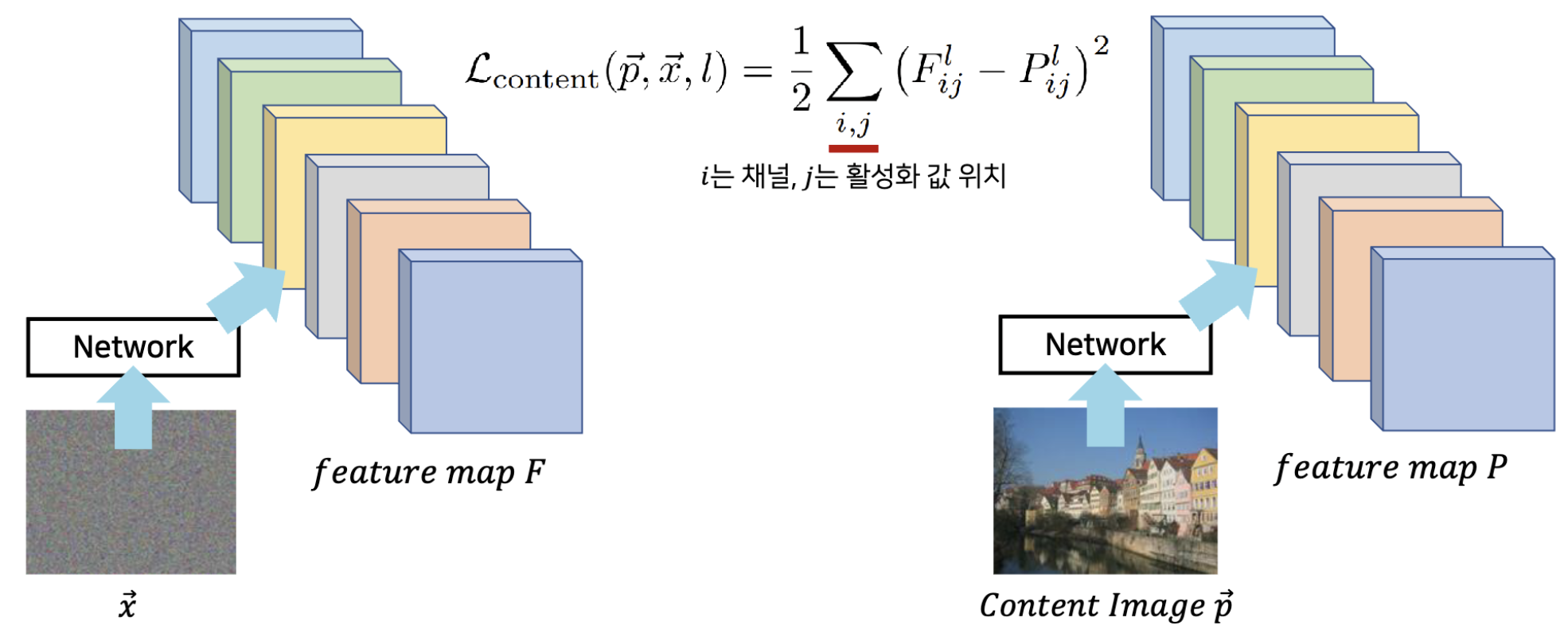
노이즈 이미지(x)가 CNN 네트워크를 거쳐 특정한 피처 맵(F)이 됐습니다. 콘텐츠 이미지(p)도 동일한 CNN 네트워크를 거쳐 피처 맵(p)이 됐고요. 입력 이미지만 다를 뿐이지 네트워크는 동일합니다. 이때, l은 레이어(layer)의 인덱스, i는 피처맵상 채널의 위치, j는 벡터상 활성화(activation) 값의 위치를 의미합니다. 예컨대, 기호 F_ij^l 가 나타내는 의미는 l번째 레이어에서 i번째 채널에서의 j번째 활성화 값을 뜻합니다. 노이즈 이미지와 콘텐츠 이미지 각각에 대하여 '같은 레이어에서 같은 채널에서의 같은 활성화 값'을 구해 손실값을 구한 거죠. 이게 바로 콘텐츠 손실값입니다. 콘텐츠 손실값 덕분에 두 이미지(노이즈 이미지와 콘텐츠 이미지)의 활성화 값이 비슷해지도록 훈련됩니다. 요약하면 훈련하는 과정에서 노이즈 이미지가 콘텐츠 이미지와 비슷해진다는 이야기입니다.
다음으로는 스타일 손실을 알아봅시다.
스타일 손실을 구하려면 두 피처 사이의 상관관계를 먼저 정의해야 합니다. 두 피처 간 스타일이 비슷하다는 말은 상관관계가 높다는 뜻입니다. 그리고 두 피처 간 상관관계는 두 피처의 내적(dot product)으로 나타낼 수 있습니다. 두 피처 간 패턴이 비슷하면 내적이 크고, 패턴이 다르면 내적도 작기 때문이죠. 이때 특정 레이어에 있는 피처 간 모든 조합별 상관관계를 Matrix 형태로 구한 것을 Gram Matrix라고 합니다. 아래 그림을 보시죠.
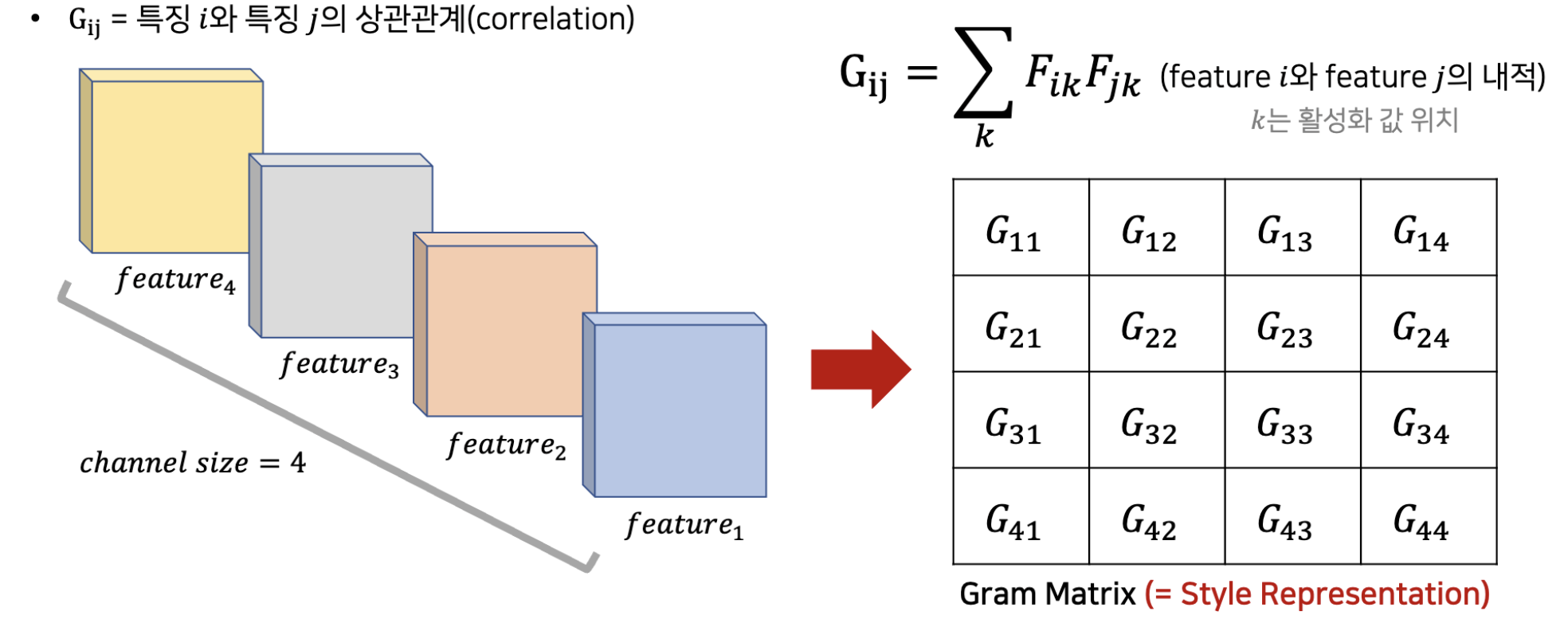
예컨대 Gram Matrix의 1행 2열(G_11) 값은 피처 1과 피처 2 사이의 상관관계(즉, 내적)를 말합니다. Gram Matrix의 행과 열 크기는 해당레이어의 채널수(여기선 4)와 같습니다. 위 그림에서 표시된 상관관계 수식(G_ij)에서 i, j는 서로 다른 채널(즉 서로 다른 피처)의 인덱스를 말하고, k는 피처에 존재하는 각각의 원소(활성화값)의 위치를 말합니다.
스타일과 관련한 훈련을 할 때는 노이즈 이미지의 Gram Matrix와 스타일 이미지의 Gram Matrix의 차이가 줄어들도록 훈련합니다. 스타일 손실은 아래 수식과 같습니다.
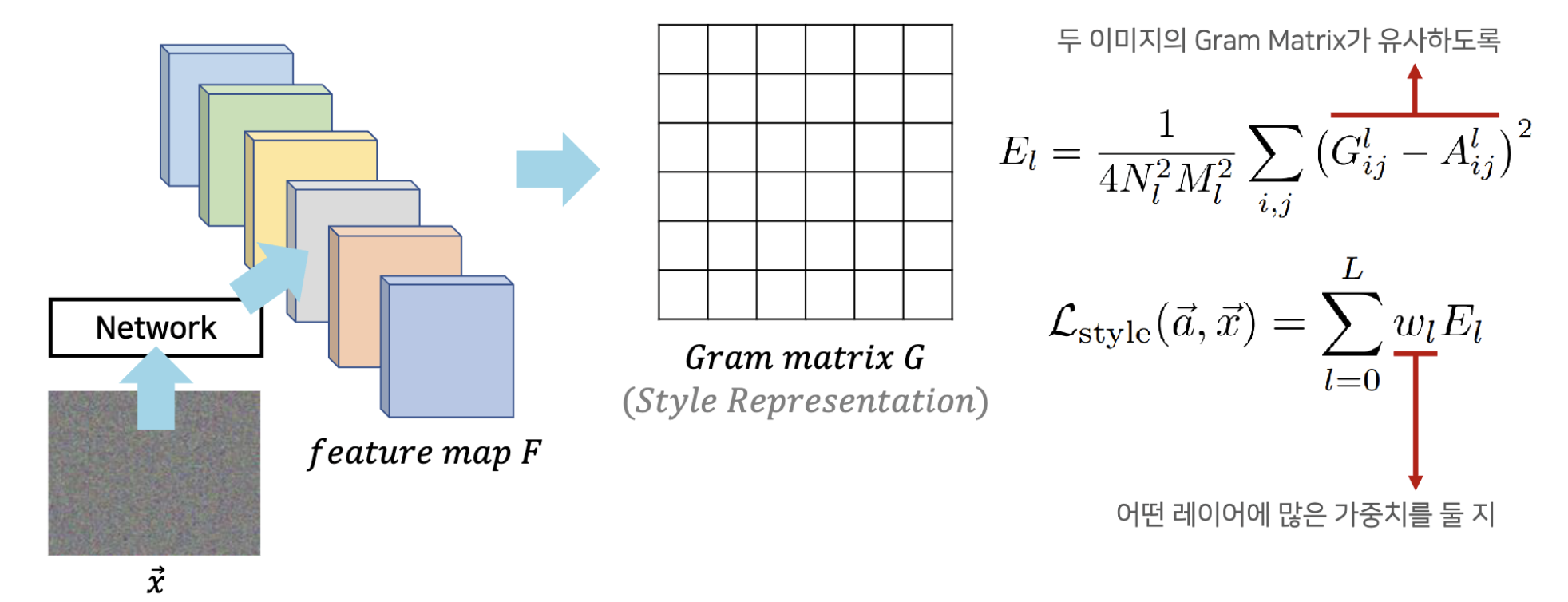
G는 노이즈 이미지(x)에서 구한 Gram Matrix, A는 스타일 이미지에서 구한 Gram Matrix입니다. 두 Matrix의 원소별 차이를 스타일 손실로 잡습니다. 곧, 두 이미지의 Gram Matrix가 비슷해지도록 훈련하게 되죠.
이 수식에서 N_l은 레이어 l에서의 피처맵 개수(채널수), M_l은 레이어 l에서의 '피처의 높이 x 피처의 너비'(즉, 벡터의 개수)를 의미합니다. 이 값들로 나눠주는 까닭은 정규화를 하기 위해서입니다. 일반적인 CNN에서 레이어가 깊어질수록 채널수가 많아지고 피처맵의 너비와 높이가 줄어듭니다. 레이어에 따라 Gram Matrix 값의 범위가 달라지는 현상을 막기 위해 정규화를 해주는 것입니다.
일반적으로 콘텐츠 손실은 하나의 레이어에서만 구합니다. 반면 스타일 손실은 5개의 레이어에서 구합니다. 레이어 5개 각각에서 Gram Matrix를 구한 뒤, 각 레이어마다의 Gram Matrix가 비슷해지도록 업데이트를 하는 것이죠. 이때 어떤 레이어에 가중치를 줄지 결정하는 매개변수가 w_l입니다.
콘텐츠 손실을 1개의 레이어에 대해서, 스타일 손실은 5개의 레이어에 대해서 구한다고 했죠? 총 6개의 레이어가 VGG19 네트워크에서 어떤 레이어인지 알아보죠.
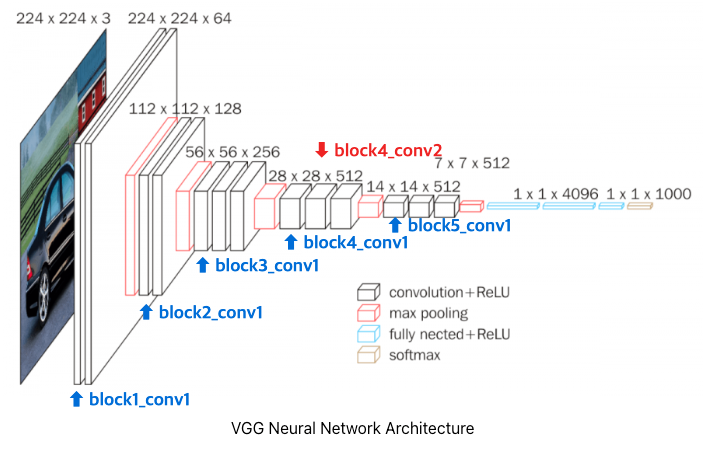
파란색으로 표시한 block1_conv1부터 block5_conv1까지가 스타일 손실을 구하는 레이어입니다. 빨간색으로 표시한 block4_conv2가 콘텐츠 손실을 구하는 레이어이고요.
지금까지 살펴본 손실을 한눈에 봅시다. 전체 손실은 아래와 같습니다.
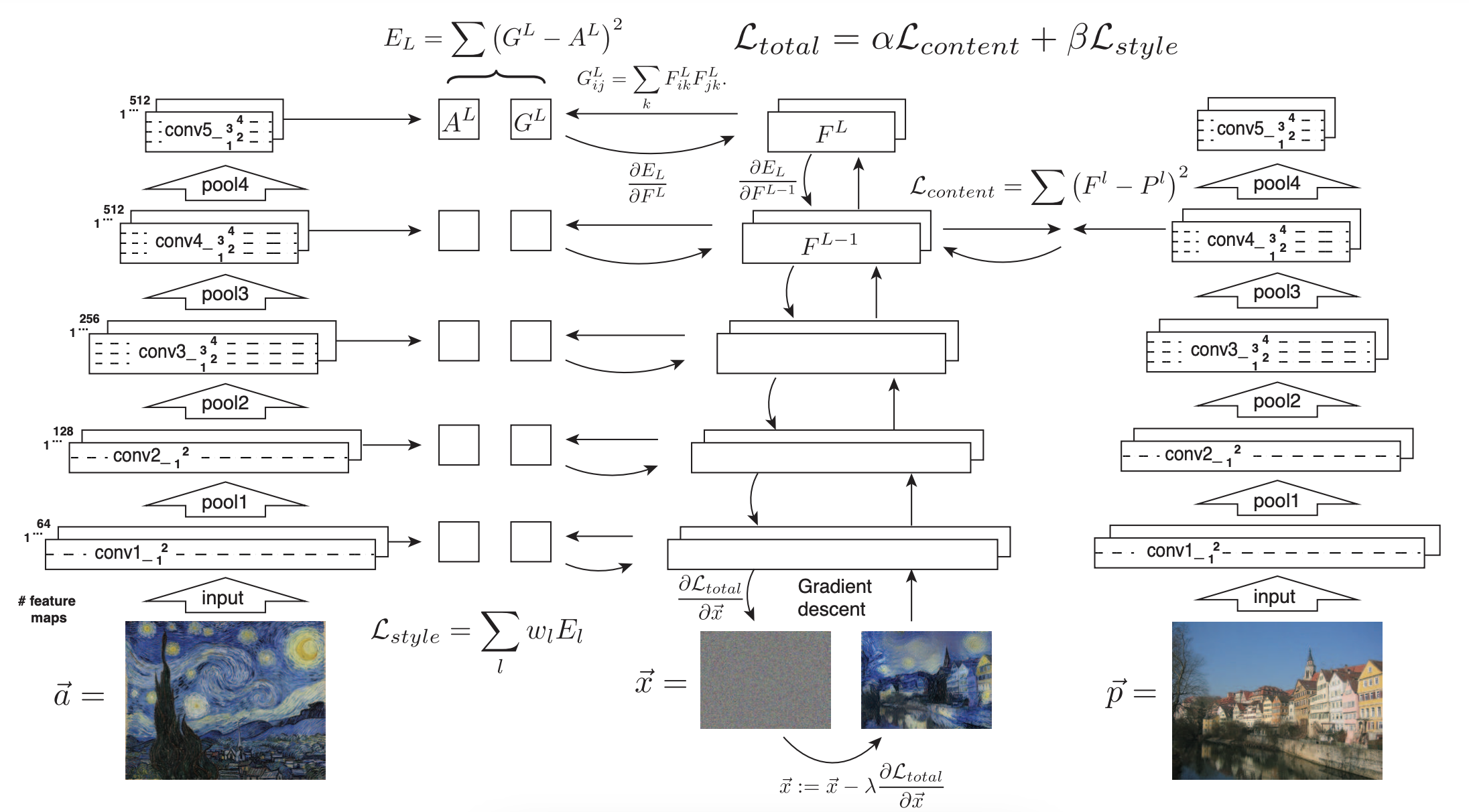
초기 랜덤 노이즈 이미지(x)는 스타일 이미지(a)에서 스타일 정보를 가져오고, 콘텐츠 이미지(p)에서 콘텐츠 정보를 가져오며 훈련을 합니다. 스타일 손실을 구하기 위해 5개 레이어에서 Gram Matrix를 구합니다. 노이즈 이미지를 입력한 동일한 네트워크에서도 같은 레이어 5개에서 Gram Matrix를 구합니다. 두 Gram Matrix의 차이를 바탕으로 스타일 손실(L_style)을 구했죠. 콘텐츠 손실은 1개 레이어로만 구합니다. '노이즈 이미지를 전달한 네트워크 내 특정 레이어'와 '콘텐츠 이미지를 전달한 (동일한) 네트워크 내 특정 레이어' 사이의 손실값(L_content)을 구했죠. 스타일 손실(L_style)과 콘텐츠 손실(L_content)에 각각 가중치 β와 α를 곱한 뒤, 두 값을 합하면 최종 손실값이 됩니다. 이 손실값을 최소화하는 방향으로 스타일 전이가 이루어집니다.
3. 이미지 재건(Image Reconstruction)
스타일 전이 논문에서는 이미지 재건까지 수행해봤습니다. 각 레이어마다 이미지를 재건하면 어떻게 되는지 알아봤습니다.
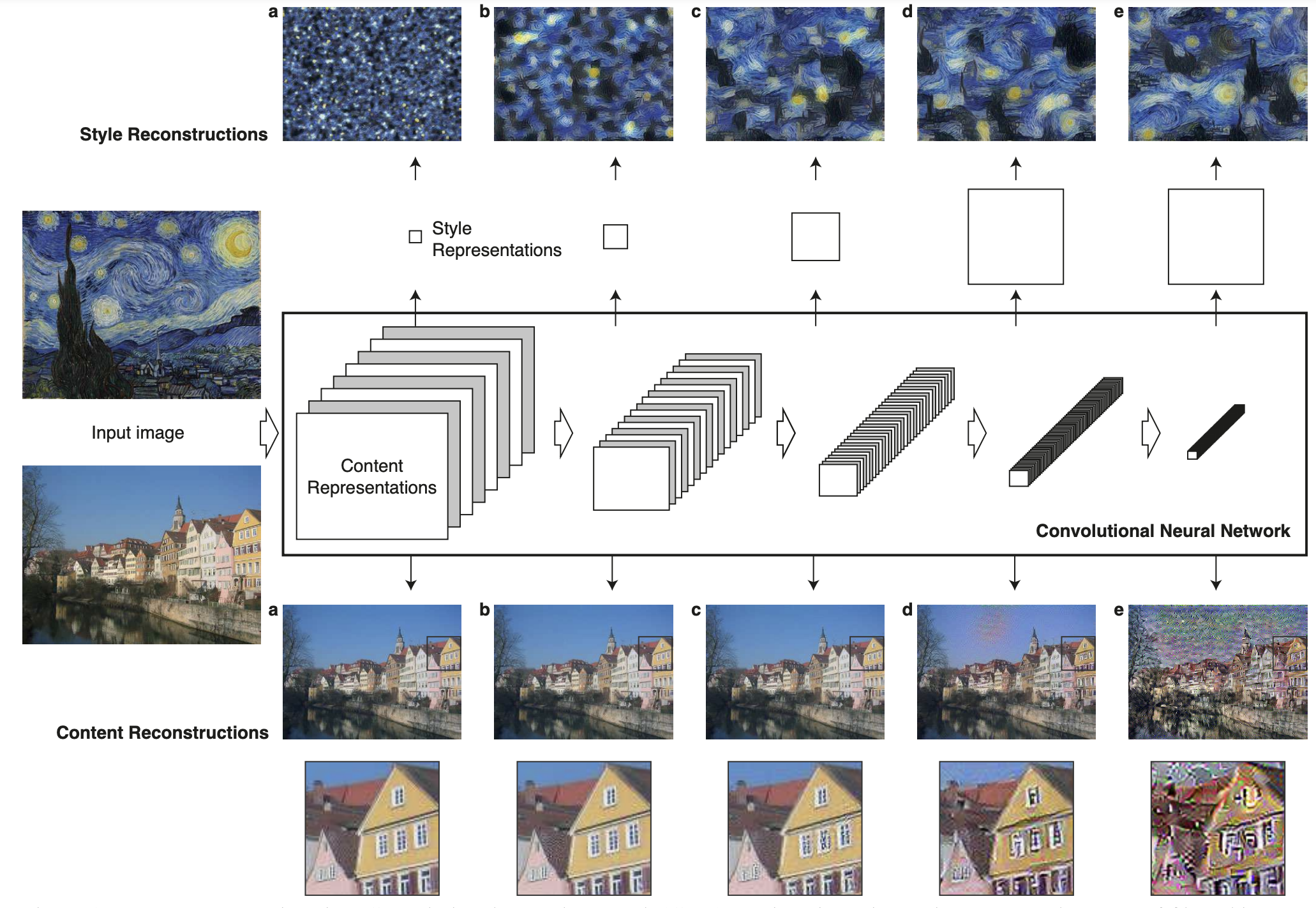
먼저 위쪽의 스타일 재건을 보시죠. a부터 e이미지까지 생성된 스타일 이미지가 다르죠? 어떤 레이어를 바탕으로 스타일 손실을 잡았는지에 따라 최종 생성된 스타일 이미지가 다릅니다. 아래와 같이 손실값을 구할 레이어를 잡았습니다.
(a) → conv1_1,
(b) → conv1_1, conv2_1
(c) → conv1_1, conv2_1, conv3_1
(d) → conv1_1, conv2_1, conv3_1, conv4_1
(e) → conv1_1, conv2_1, conv3_1, conv4_1, conv5_1
레이어를 많이 포함할수록 스타일(화풍)을 더 잘 재건하네요. 참고로, Gram Matrix(Styel Representation)의 크기는 뒤쪽 레이어일수록 커집니다. Gram Matrix의 크기는 채널수와 같은데, 뒤쪽 레이어일수록 피처의 크기가 작아지면서 채널수가 커집니다. 그래서 앞쪽 레이어보다 뒤쪽 레이어의 Gram Matrix 크기가 더 크네요.
아래쪽 그림은 콘텐츠를 재건한 예시를 보여줍니다. 아래와 같이 손실값을 구할 레이어를 잡았습니다.
(a) → conv1_2
(b) → conv2_2
(c) → conv3_2
(d) → conv4_2
(e) → conv5_2
레이어가 깊어질수록 구체적인 픽셀 정보가 없어지네요. 뒤쪽 레이어로 잡을수록 원본 이미지의 콘텐츠가 없어진다는 말입니다.
어떤 레이어를 바탕으로 스타일 손실, 콘텐츠 손실을 구할지에 따라 스타일 전이 결과 이미지가 달라지겠습니다.
4. 초기 스타일 전이 네트워크의 한계
초기 스타일 전이 논문에서는 스타일 전이의 두 가지 한계를 말합니다. 첫 번째로 훈련 속도가 느리다는 점입니다. 훈련 속도는 이미지의 해상도(크기)와 관련 있습니다. 이미지가 크면 훈련 속도도 느려지지요. 그래서 간단한 실습을 할 때는 이미지 크기를 줄여서 해야 합니다.
두 번째 문제는 스타일이 무엇인지 정확히 정의하기 어렵다는 점입니다. 우리는 직관적으로 스타일이 무엇인지 이해하지만, 논리적으로 혹은 수식으로 정의하긴 어려울 것 같습니다. 아래 스타일 전이 예시를 보시죠.

스타일 이미지에서 스타일을 따와서, 콘텐츠 이미지에 잘 적용했네요. 그런데 여기서 스타일이란 무엇인지를 명확하게 말하긴 힘듭니다. 대략 색감 정도라고 밖에 말할 수 없겠군요.
스타일 전이 실습
지금까지 스타일 전이의 원리를 알아봤습니다. 이번에는 코드로 간단하게 구현해보겠습니다. 코드는 텐서플로의 Neural style transfer 튜토리얼을 바탕으로 작성했습니다.
아래 코드는 구글 Colab을 바탕으로 설명합니다.
1. 사전 훈련된 VGG19 모델 불러오기
가장 먼저 라이브러리를 불러옵니다.
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np이어서 이미지넷으로 사전 훈련된 VGG19 네트워크를 불러오겠습니다.
network = tf.keras.applications.VGG19(include_top=False, weights='imagenet')- include_top=False : 전결합층(fully-connected layers)은 제외하고 오직 합성곱 계층(convolutional layers)과 풀링 계층(pooling layers)만 가져오겠다는 뜻입니다. 불러온 VGG19 네트워크로 분류를 할 건 아니므로, 마지막 전결합층은 빼준 것입니다.
- weights='imagenet' : 이미지넷 데이터셋으로 사전 훈련된 모델을 불러오겠다는 말입니다.
불러온 VGG19 네트워크의 아키텍처를 살펴보시죠.
network.summary()공간 제약상 출력 결과는 생략하겠습니다. 인풋 레이어부터 최종 block5_pool 레이어까지 잘 출력이 됩니다. include_top=False로 설정해서 불러왔기 때문에 전결합층은 없습니다.
전체 레이어 개수를 살펴보기 위해 len(network.layers)를 출력하면 22가 나오네요. 레이어 개수가 22개입니다.
2. 이미지 불러온 뒤 전처리하기
다음으로는 스타일 전이에 사용할 콘텐츠 이미지와 스타일 이미지를 불러와 전처리를 해보겠습니다. 이미지를 먼저 구글 드라이브 저장합니다. 그다음 저장된 이미지를 Colab에 불러와 사용해보겠습니다. 구글 드라이브에 접근하기 위해 마운트를 먼저 합니다.
from google.colab import drive
drive.mount('/content/drive')콘텐츠 이미지부터 불러와보죠. unsplash에서 다운로드한 코뿔소 이미지입니다(이미지 출처 : https://unsplash.com/ko/%EC%82%AC%EC%A7%84/jBjQA3LU9Dc).
content_image_path = '/content/drive/MyDrive/colab/Computer-Vision-Course/Data/Images/rhinoceros.jpg'
content_image = tf.keras.preprocessing.image.load_img(content_image_path)불러온 이미지를 출력해보죠.
plt.imshow(content_image);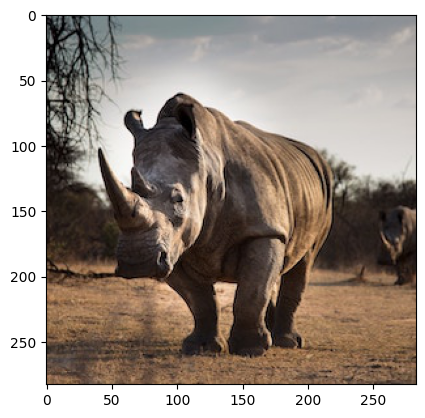
tf.keras.preprocessing.image.load_img()로 불러온 이미지는 PIL 타입입니다.
type(content_image)PIL.JpegImagePlugin.JpegImageFile
텐서플로로 스타일 전이 작업을 하려면 PIL 타입을 넘파이 타입으로 바꿔줘야 합니다. img_to_array() 메서드로 구현할 수 있습니다.
# Convert PIL image to numpy type to work with TensorFlow
content_image = tf.keras.preprocessing.image.img_to_array(content_image)
type(content_image), content_image.shape, content_image.min(), content_image.max()(numpy.ndarray, (283, 283, 3), 0.0, 255.0)
넘파이 타입으로 잘 바뀌었습니다. 형상은 (283, 283, 3)이네요. 가로, 세로 크기가 각각 283이고, 채널수가 3개(RGB)라는 말입니다. 이미지의 픽셀 최솟값, 최댓값은 각각 0.0과 255.0입니다. 스타일 전이 작업을 위해서는 픽셀 범위를 정규화해줘야 합니다. 모든 픽셀을 255로 나눠 0~1 사잇값으로 정규화하겠습니다.
# Normalizing
content_image = content_image / 255
content_image.min(), content_image.max()(0.0, 1.0)
정규화가 잘 됐네요. 이어서 차원을 하나 더하겠습니다. 이미지를 딥러닝 모델에 전달하려면 배치 크기에 해당하는 차원이 하나 더 있어야 합니다.
content_image = content_image[tf.newaxis, :]차원을 하나 추가했으니, 최종 형상을 출력해보죠.
content_image.shape(1, 283, 283, 3)
원래는 형상이 (283, 283, 3)이었는데, 맨 앞에 배치 크기에 해당하는 차원이 더해졌네요. 이로써 콘텐츠 이미지를 불러오고 전처리(넘파이 타입으로 변경, 정규화, 차원 추가) 작업까지 해줬습니다.
다음으로는 스타일 이미지를 불러와서 같은 전처리 작업을 하겠습니다. 스타일 이미지로는 반 고흐의 'starry night'를 사용하겠습니다.
style_image_path = '/content/drive/MyDrive/colab/Computer-Vision-Course/Data/Images/starrynight.jpg'
style_image = tf.keras.preprocessing.image.load_img(style_image_path)
plt.imshow(style_image);
여기에 전처리 작업을 하겠습니다. 콘텐츠 이미지 때와 마찬가지로 넘파이 타입 변경, 정규화, 차원추가를 합니다.
# Preprocessing
style_image = tf.keras.preprocessing.image.img_to_array(style_image)
style_image = style_image / 255
style_image = style_image[tf.newaxis, :]
style_image.shape(1, 560, 600, 3)
3. 네트워크 만들기
지금까지 사전 훈련된 VGG19 네트워크를 불러왔고, 전처리한 이미지까지 준비했습니다. 이제는 본격적으로 스타일 전이 네트워크를 만들어보겠습니다. 네트워크를 만들기 위해서 콘텐츠 레이어와 스타일 레이어를 정해야 합니다. 콘텐츠 레이어는 노이즈 이미지와 콘텐츠 이미지 사이의 손실을 구하는 레이어입니다. 스타일 레이어는 노이즈 이미지와 스타일 이미지 사이의 손실을 구하는 레이어고요. 논문에서와 마찬가지로 콘텐츠 레이어는 한 개, 스타일 레이어는 5개로 정했습니다. 각 레이어의 이름을 리스트로 할당하고, 레이어의 개수도 변수로 지정했습니다.
content_layers = ['block4_conv2']
style_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)스타일 레이어의 출력값을 볼까요? 총 다섯 가지입니다.
[network.get_layer(name).output for name in style_layers][<KerasTensor: shape=(None, None, None, 64) dtype=float32 (created by layer 'block1_conv1')>,
<KerasTensor: shape=(None, None, None, 128) dtype=float32 (created by layer 'block2_conv1')>,
<KerasTensor: shape=(None, None, None, 256) dtype=float32 (created by layer 'block3_conv1')>,
<KerasTensor: shape=(None, None, None, 512) dtype=float32 (created by layer 'block4_conv1')>,
<KerasTensor: shape=(None, None, None, 512) dtype=float32 (created by layer 'block5_conv1')>]
입력값을 얻으려면 input을 호출하면 됩니다.
network.input<KerasTensor: shape=(None, None, None, 3) dtype=float32 (created by layer 'input_1')>
이젠 스타일 전이를 위한 VGG 레이어를 정의해보죠. 먼저 VGG 네트워크를 불러온 뒤, 입력받은 레이어(콘텐츠 레이어와 스타일 레이어를 전달할 것임)마다 출력값을 내도록 정의합니다.
def build_vgg_layers(layer_names):
'''return output activation value'''
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
network = tf.keras.Model(inputs=[vgg.input], outputs=outputs)
return network앞서 정의한 build_vgg_layers() 함수에 스타일 레이어를 전달해보겠습니다.
# extract image style
style_extractor = build_vgg_layers(style_layers)결과를 보려면 style_extractor.summary()를 출력해보면 됩니다.
style_extractor의 출력값을 볼까요?
style_extractor.outputs[<KerasTensor: shape=(None, None, None, 64) dtype=float32 (created by layer 'block1_conv1')>,
<KerasTensor: shape=(None, None, None, 128) dtype=float32 (created by layer 'block2_conv1')>,
<KerasTensor: shape=(None, None, None, 256) dtype=float32 (created by layer 'block3_conv1')>,
<KerasTensor: shape=(None, None, None, 512) dtype=float32 (created by layer 'block4_conv1')>,
<KerasTensor: shape=(None, None, None, 512) dtype=float32 (created by layer 'block5_conv1')>]
스타일 레이어의 출력값이므로 총 5개입니다. 이 style_extractor에 실제 스타일 이미지를 전달해서 5가지 출력값의 형상을 출력해보겠습니다.
# 5 values with ReLU activation are applied
style_outputs = style_extractor(style_image)
style_outputs[0].shape, style_outputs[1].shape, style_outputs[2].shape, style_outputs[3].shape, style_outputs[4].shape(TensorShape([1, 560, 600, 64]),
TensorShape([1, 280, 300, 128]),
TensorShape([1, 140, 150, 256]),
TensorShape([1, 70, 75, 512]),
TensorShape([1, 35, 37, 512]))
총 5가지 출력값이 반환됐네요. (배치 크기, 이미지 크기1, 이미지 크기2, 채널수)를 의미합니다. 앞쪽 레이어일수록 이미지 크기가 크고 채널수가 적습니다. 뒤로 갈수록 이미지 크기가 작아지고 채널수가 많아지고요.
다음으로 Gram Matrix를 구하는 함수를 정의해봅시다. 아래 코드는 텐서플로 튜토리얼에서 그대로 가지고 왔습니다.
# https://www.tensorflow.org/api_docs/python/tf/einsum
# Loss between the style and the content image (see original paper, section 2.2)
def gram_matrix(layer_activation):
result = tf.linalg.einsum('bijc,bijd->bcd', layer_activation, layer_activation)
input_shape = tf.shape(layer_activation)
num_locations = tf.cast(input_shape[1] * input_shape[2], tf.float32)
return result / num_locations # NormalizingGram Matrix의 예시를 보려면 gram_matrix(style_outputs[0])를 출력해보세요.
다음으로 스타일 전이를 위한 모델 클래스를 만들어보겠습니다. __init__ 함수에는 build_vgg_lagyers()에 스타일 레이어와 콘텐츠 레이어 모두를 전달합니다. 이어서 call() 함수를 정의할 때는 입력값에 255를 곱합니다. 입력값이 0~1 사잇값이므로 이를 역정규화하기 위함이죠. 이 값을 VGG19 모델에 넣기 위해 전처리 작업을 합니다. vgg19.preprocess_input() 메서드로 구현할 수 있습니다. 최종 출력값 중 첫 5개는 스타일 레이어의 출력값이고, 나머지 하나는 콘텐츠 레이어의 출력값입니다. 이 출력값들을 딕셔너리로 저장해 반환합니다.
class StyleContentModel(tf.keras.models.Model):
'''Build a model that returns the style and content tensors.'''
def __init__(self, style_layers, content_layers):
super().__init__()
self.vgg = build_vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False # Because this network won't be trained
def call(self, inputs):
inputs = inputs * 255.0 # Denormalizing (Expects float input in [0,1])
# Data is preprocessed and passed to the VGG (normalized from -127.50 to +127.50)
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs = outputs[:self.num_style_layers]
content_outputs = outputs[self.num_style_layers:]
style_outputs = [gram_matrix(style_output) for style_output in style_outputs]
content_dict = {content_name: value for content_name, value in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value for style_name, value in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}스타일 전이를 위한 extractor를 만들기 위해 앞서 만든 StyleContentModel 클래스에 스타일 레이어와 콘텐츠 레이어를 전달합니다. 여기서 style_layers와 content_layers는 각각 스타일 레이어 이름과 콘텐츠 레이어 이름이 담긴 리스트입니다.
extractor = StyleContentModel(style_layers, content_layers)이 extractor에 콘텐츠 이미지를 전달해 출력값을 result에 저장해보겠습니다.
results = extractor(content_image)그리고 그 값(딕셔너리 형태로 반환한다고 했죠?)을 출력해보시죠.
for key, value in results.items():
print(key, value.keys())content dict_keys(['block4_conv2'])
style dict_keys(['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1'])
콘텐츠 레이어와 스타일 레이어의 이름이 출력됐네요. 스타일 타깃값과 콘텐츠 타깃값을 잡으려면 다음과 같이 key 값으로 지정해주면 됩니다.
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']4. 모델 훈련
지금까지 다룬 코드를 바탕으로 모델 훈련 코드를 짜보겠습니다.
초기 노이즈 이미지는 new_image 변수에 할당하겠습니다. 옵티마이저는 Adam으로 하고 학습률은 0.07로 해보겠습니다. 콘텐츠 가중치와 스타일 가중치는 각각 1과 1,000으로 잡겠습니다. 에폭은 200번 돌리겠습니다.
스타일 손실, 콘텐츠 손실을 각각 구한 뒤, 두 손실의 합을 최종 손실로 잡습니다. 최종 손실 값이 작아지도록 모델을 훈련하며 new_image를 갱신하는 겁니다. 최종적으로 구한 new_image는 0~1 사잇값을 갖도록 클리핑까지 해주었습니다.
new_image = tf.Variable(content_image)
optimizer = tf.optimizers.Adam(learning_rate=0.07)
content_weight = 1 # The greater the content weight, the greater the retention of the original image content
style_weight = 1000 # The greater the style weight, the more styles are preserved
num_epochs = 200
verbose = 25
for epoch in range(num_epochs):
with tf.GradientTape() as tape:
outputs = extractor(new_image)
content_outputs = outputs['content']
style_outputs = outputs['style']
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name] - content_targets[name]) ** 2) for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name] - style_targets[name]) ** 2) for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
total_loss = content_loss + style_loss
gradient = tape.gradient(total_loss, new_image)
optimizer.apply_gradients([(gradient, new_image)])
new_image.assign(tf.clip_by_value(new_image, 0.0, 1.0))
if (epoch + 1) % verbose == 0:
print(f'Epoch {epoch + 1} | content loss: {content_loss} | style loss: {style_loss} | total loss {total_loss}')
plt.imshow(tf.squeeze(new_image, axis=0))
plt.show()Epoch 200 | content loss: 599827.125 | style loss: 42334543872.0 | total loss 42335141888.0
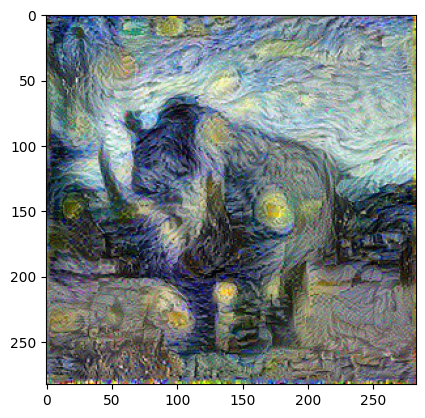
어떤가요? 코뿔소 사진이 고흐 화풍 같아졌나요? 물론 여기서는 빠르게 결과를 보기 위해 해상도도 아주 낮은(한 장에 100KB가 안 되는) 사진을 사용했습니다. 좋은 해상도의 사진을 사용해보고, 콘텐츠/스타일 가중치, 학습률, 에폭 등의 파라미터도 조정해보면 더 품질 좋은 이미지가 나올 겁니다. 물론 그만큼 훈련 시간은 오래 걸리죠.
5. 스타일 전이 결과 출력
원본 콘텐츠 이미지, 스타일 전이 생성 이미지, 스타일 이미지를 나란히 출력해서 비교해봅시다.
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(30, 8))
ax1.imshow(tf.squeeze(content_image, axis=0))
ax1.set_title('Content image')
ax2.imshow(tf.squeeze(new_image, axis=0))
ax2.set_title('New image')
ax3.imshow(tf.squeeze(style_image, axis=0))
ax3.set_title('Style image')
plt.axis('off');
간단한 실습이라 썩 만족스러운 결과는 아니지만 어느 정도 고흐 화풍을 담은 결과를 구했습니다.
다른 콘텐츠 이미지, 다른 스타일 이미지를 적용하면서 실험해보세요. 저는 모네 그림을 스타일 이미지로 활용해서 돌려보니 아래와 같은 결과를 얻었습니다. 고흐의 스타일 이미지를 사용할 때보다 품질이 떨어지지만 이미지의 해상도와 모델 파라미터를 조정하면 더 괜찮은 결과를 얻을 수 있을 겁니다.

참고 자료
Jones Granatyr(Udemy) - "Computer Vision: Master Class"
동빈나 - "CNN을 활용한 스타일 전송(Style Transfer) | 꼼꼼한 딥러닝 논문 리뷰와 코드 실습"
'컴퓨터 비전' 카테고리의 다른 글
| 컴퓨터 비전 - 13. 딥드림(Deep Dream)이란? (0) | 2023.06.05 |
|---|---|
| 컴퓨터 비전 - 12. 자세 추정(Pose Estimation)이란? (2) | 2023.06.02 |
| 컴퓨터 비전 - 11. YOLO v1, v2, v3 개요와 실습 (0) | 2023.05.06 |
| 컴퓨터 비전 - 10. R-CNN vs. SPP-net vs. Fast R-CNN vs. Faster R-CNN 개요 (4) | 2023.03.15 |
| 컴퓨터 비전 - 9. 객체 탐지(Object Detection) 개요 (4) | 2023.03.14 |



