
귀퉁이 서재
컴퓨터 비전 - 10. R-CNN vs. SPP-net vs. Fast R-CNN vs. Faster R-CNN 개요 본문
컴퓨터 비전 - 10. R-CNN vs. SPP-net vs. Fast R-CNN vs. Faster R-CNN 개요
Baek Kyun Shin 2023. 3. 15. 21:53
초창기 객체 탐지 모델인 R-CNN, SPP-net, Fast R-CNN, Faster R-CNN에 관해 알아보겠습니다. 각 객체 탐지 모델의 논문 전체를 따로 정리해 놓았는데, 자세한 내용이 궁금한 분은 아래 링크를 참고해주세요.
이 글에서는 R-CNN, SPP-net, Fast R-CNN, Faster R-CNN의 핵심 구조를 알아보겠습니다.
1. R-CNN
기존 localization 구조의 문제점과 해결 방안
객체 localization을 할 때 원본 이미지와 annotation 정보를 활용합니다. 원본 이미지를 활용해 이미지 분류를 수행하고, annotation 정보를 활용해 경계 박스를 예측합니다(bounding box regression). 그런데 한 이미지 안에 객체가 여러 개면 이야기가 달라집니다. 한 이미지 안에 있는 여러 객체를 제대로 탐지하지 못하게 되죠. 문제를 해결하려면 새로운 방식을 도입해야 합니다. 슬라이딩 윈도 방식과 영역 추정 방식이 있습니다.
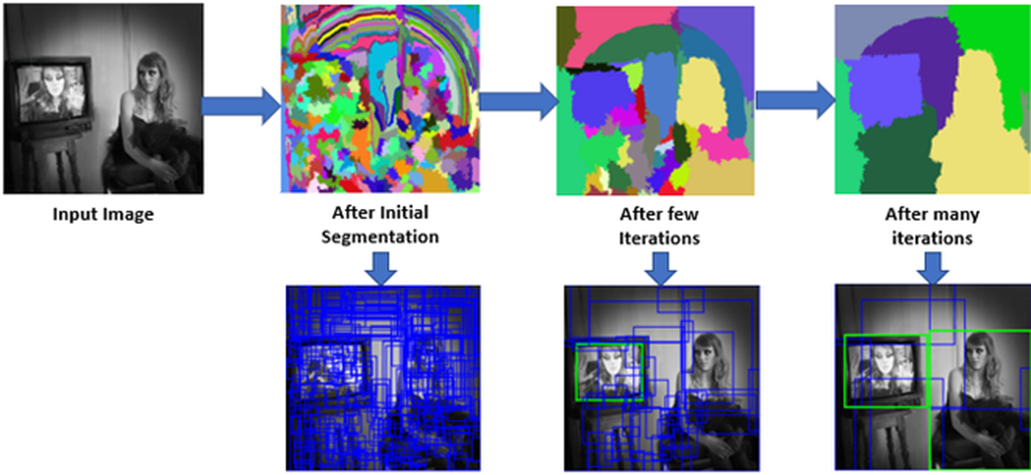
슬라이딩 윈도(Sliding Window) 방식이란 사각형 윈도를 이미지 왼쪽 위부터 오른쪽 아래까지 이동하면서 객체를 탐지하는 방식입니다. 아래는 오드리 햅번 이미지에 슬라이딩 윈도를 적용한 예시입니다.

윈도가 이동하면서 윈도 안에 있는 객체를 탐지하는 방식이죠. 이러한 슬라이딩 윈도 방식은 초기 객체 탐지 기법으로 활용되었습니다. 하지만 이 또한 문제점이 있습니다. 슬라이딩 윈도 크기에 딱 맞지 않는 객체가 있을 수 있다는 점입니다. 가령 물체가 윈도 크기보다 클 수 있고, 반대로 작아서 윈도 안에 여러 물체가 있을 수도 있죠. 이를 해결하기 위해 다양한 크기의 윈도우를 사용하는 방법이 있습니다. 또한 윈도우 크기는 고정하되 이미지 크기를 바꿔가면서 슬라이딩 윈도를 적용할 수도 있습니다. 다만, 여러 크기의 윈도와 여러 크기의 이미지를 활용해 스캔하므로 검출 성능도 떨어지고, 시간도 오래 걸립니다. 게다가 윈도가 이미지의 모든 영역을 훑기 때문에 더욱 시간이 오래 걸립니다. 객체가 없는 영역(배경)도 무조건 훑어야 해서 효율이 떨어지기도 하죠.
슬라이딩 윈도의 문제를 개선한 방식이 바로 다음에 알아볼 영역 추정 방식입니다. 영역 추정 기법이 나오면서 슬라이딩 윈도 방식은 더 이상 활용되지 않았지만 객체 탐지 발전에 기술적인 뿌리가 됐습니다.
선택적 탐색(Selective Search)
영역 추정(Region Proposal) 혹은 영역 제안이란 객체가 있을 만한 후보 영역을 먼저 찾아주는 방법입니다. 이후에 그 영역을 바탕으로 객체를 찾습니다. 모든 영역을 훑는 슬라이딩 윈도보다 효율적이죠. 대표적인 영역 추정 기법으로는 선택적 탐색(Selective Search)이 있습니다.
선택적 탐색은 속도도 빠르고 예측 성능도 좋은 영역 추정 알고리즘입니다. 먼저 이미지에서 비슷한 색상, 무늬, 크기, 형태에 따라 영역을 그룹핑합니다. 이렇게 그룹핑한 영역을 바탕으로 경계 박스를 추정하죠.

비슷한 영역을 그룹핑하는 작업을 딱 한 번만 하면 너무 많은 경계 박스를 생성합니다. 그렇기 때문에 비슷한 영역끼리 그룹핑하는 작업을 여러 차례 반복하며 영역을 추정합니다. 다음 그림은 선택적 탐색 기법으로 경계 박스를 추정하는 예시입니다.
R-CNN 구조
R-CNN은 영역 추정(region proposal) 기법을 적용한 객체 탐지 알고리즘입니다.
<NOTE> 영역 추정과 CNN을 결합했다는 이유로 R-CNN(Region-based Convolutional Neural Network)이라고 부릅니다.
다음 그림을 보시죠. R-CNN의 객체 탐지 프로세스입니다.
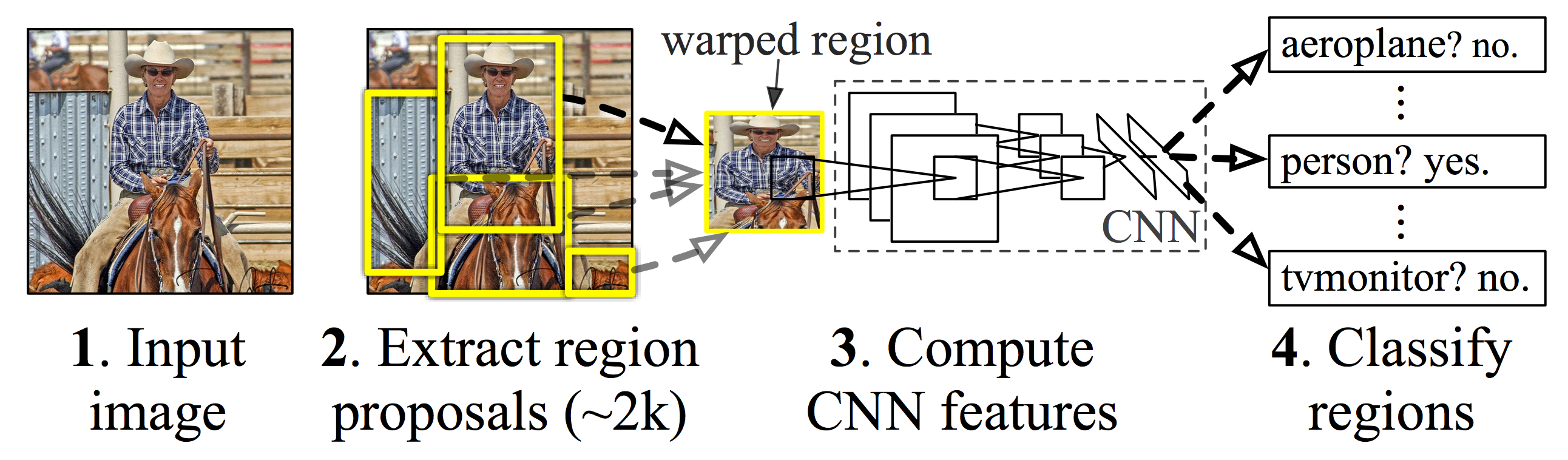
- (이미지 입력) 먼저 입력 이미지를 받습니다. 어떤 크기의 이미지든 괜찮습니다.
- (영역 추정 및 이미지 warping) 원본 이미지에 영역 추정 기법(구체적으로는 선택적 탐색(selective search))을 적용해 후보 영역 2,000개를 뽑아냅니다. 후보 영역이란 객체가 있을 만한 영역을 말합니다. 사각형 경계 박스로 표시하죠. 이때 후보 영역의 크기나 가로세로 비율은 다 다릅니다. 그런데 뒤에서 전결합 계층에 전달하려면 데이터 크기가 일정해야 합니다. 그래서 모든 후보 영역을 (227 x 227) 픽셀 크기로 변형해야 합니다. 이렇게 이미지를 일정한 크기로 변형하는 방법을 warping이라고 합니다. 후보 영역의 크기나 가로세로 비율이 제각각이더라도 warping한 후보 영역(warped region)은 크기가 일정합니다.
- (CNN 훈련) warping한 후보 영역을 CNN에 전달해 훈련합니다. 이때 뼈대가 되는 CNN 모델은 이미지넷 데이터셋으로 사전 훈련한 AlexNet입니다. 전결합 계층까지 순전파를 마친 뒤, 출력값을 다음 계층인 SVM에 전달합니다.
- (SVM으로 분류) 보통 CNN에서는 전결합 계층 다음에 소프트맥스를 사용해서 결과를 출력합니다. 하지만 R-CNN에서는 전결합 계층 다음에 SVM을 활용해 분류를 수행합니다. 다시 말해, 딥러닝은 전결합 계층에서 끝난다고 볼 수 있죠. 전결합 계층 이후로는 머신러닝 모델인 SVM으로 새롭게 분류를 하기 때문이죠. '전결합 계층이 출력한 피처 벡터 자체를 피처로 보고 SVM을 수행하는 겁니다. 더불어, 경계 박스 회귀를 통해 객체를 포함하는 경계 박스의 좌표값도 예측합니다.
이런 구조를 사용하면 이미지 안에 객체가 여러 개여도 잘 탐지할 수 있습니다. 기존 localization 구조와 가장 큰 차이는 영역 추정이 있는지 없는지 여부입니다. R-CNN 구조를 정리하면 다음과 같습니다.
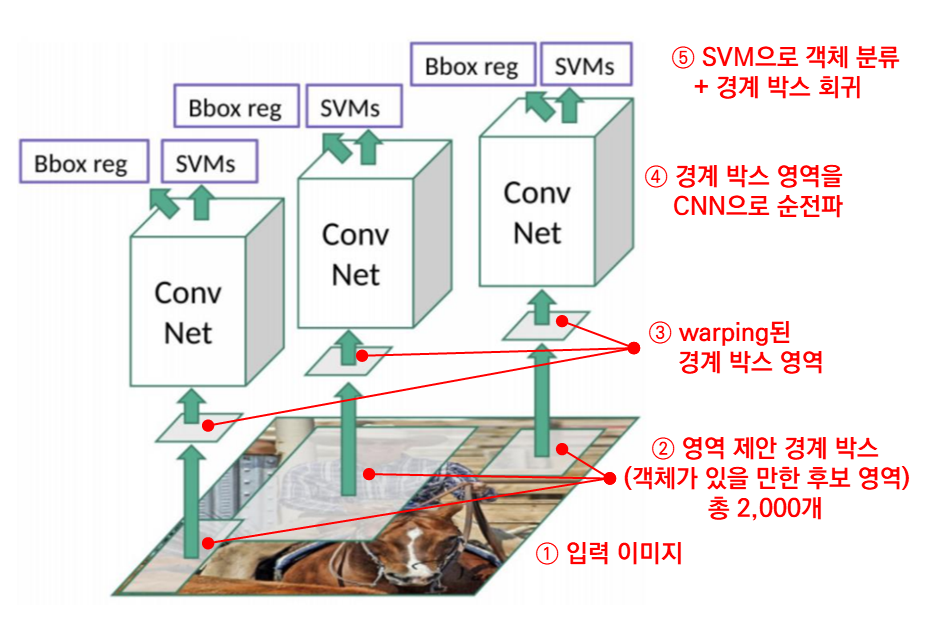
R-CNN은 객체 탐지에 딥러닝을 적용한 최초 알고리즘입니다. R-CNN은 동시대 다른 알고리즘에 비해 꽤 높은 객체 탐지 성능을 보입니다. R-CNN 덕분에 딥러닝 기반 객체 탐지 알고리즘의 성능이 입증되었습니다. 영역 추정 기법을 적용한다는 새로운 지평도 열었지요. 반면, R-CNN은 구조나 학습 절차가 복잡하고, 객체 탐지 시간도 너무 오래 걸립니다. 한 이미지당 GPU로는 13초, CPU로는 53초가 걸리니까요. 한 이미지마다 선택적 탐색으로 후보 영역 2,000개를 뽑고, 2,000개의 후보 영역을 모두 CNN으로 처리하는 데 시간이 많이 걸리기 때문입니다. 이후로는 탐지 시간을 줄이고 복잡하게 분리된 모델 구조를 통합하는 방향으로 연구가 진행됐습니다.
2. SPP-net
R-CNN 개선책
R-CNN은 원본 이미지에서 선택적 탐색으로 후보 영역 2,000개를 추출합니다. 이어서 후보 영역 2,000개를 모두 CNN에 전달해 각각 합성곱 연산을 하죠. 그렇기 때문에 시간이 오래 걸린다고 했습니다. 모든 후보 영역마다 합성곱 연산을 하지 않고 원본 이미지로 한 번만 합성곱 연산을 하면 어떨까요? 대신 피처 맵 위에 후보 영역 경계 박스를 표시해둬도 되지 않을까요? 그렇게 하면 R-CNN의 단점을 개선할 수 있겠네요. 다음 그림을 보시죠. R-CNN 개선책입니다.
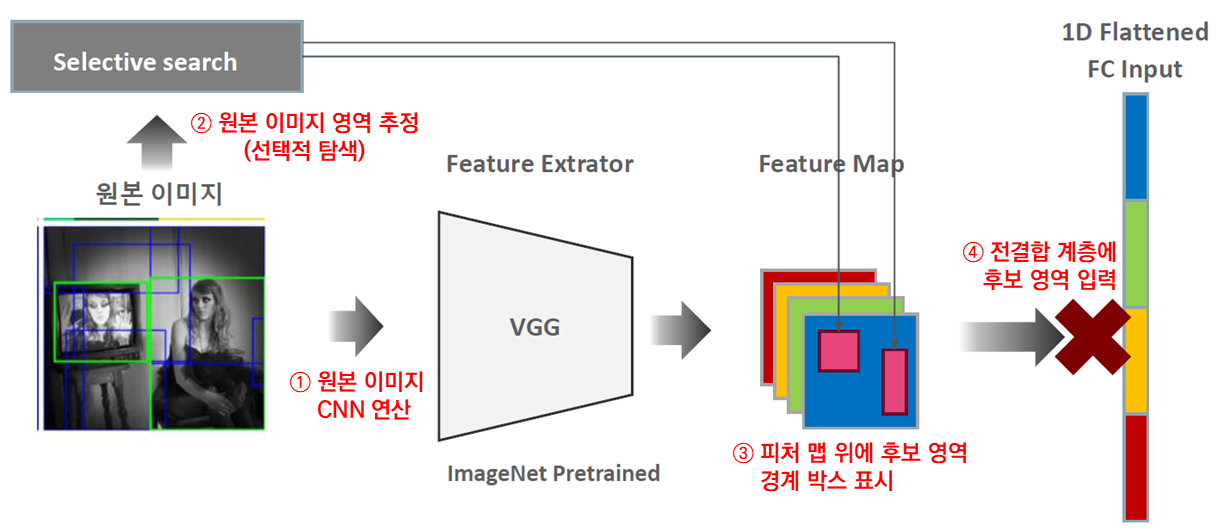
① 먼저 원본 이미지 전체를 CNN에 전달해 합성곱 연산을 합니다. 선택적 탐색으로 구한 후보 영역 2,000개를 합성곱 연산한 R-CNN과 다르죠? 원본 이미지 전체를 한 번만 합성곱 연산했습니다. ② 동시에 원본 이미지로 영역 추정도 합니다. 선택적 탐색으로 말이죠. 그럼 후보 영역을 구할 수 있겠죠? 이렇게 구한 후보 영역을 ③ '앞서 원본 이미지의 합성곱 연산으로 구한 피처 맵' 위에 표시합니다. 그럼 피처 맵 위에 후보 영역 경계 박스가 여러 개 표시됩니다.

④ 이 후보 영역을 전결합 계층에 전달합니다.
그런데 여기서 문제가 생깁니다. 전결합 계층에 입력하는 데이터 크기는 일정해야 합니다. 변하는 게 아니라 고정돼야 한다는 말이죠. 피처 맵 위에 표시된 후보 영역은 크기가 제각각이죠? 전결합 계층에 입력하지 못합니다. 후보 영역을 전결합 계층에 전달하려면 데이터 크기를 일정하게 맞춰야 합니다. 이 역할을 하는 계층이 SPP(Spatial Pyramid Pooling) 계층입니다. SPP를 적용한 모델이 바로 SPP-net(Spatial Pyramid Pooling Network)이죠. 다음은 SPP-net의 구조입니다. 피처 맵과 전결합 계층 사이에 SPP 계층을 두었죠.
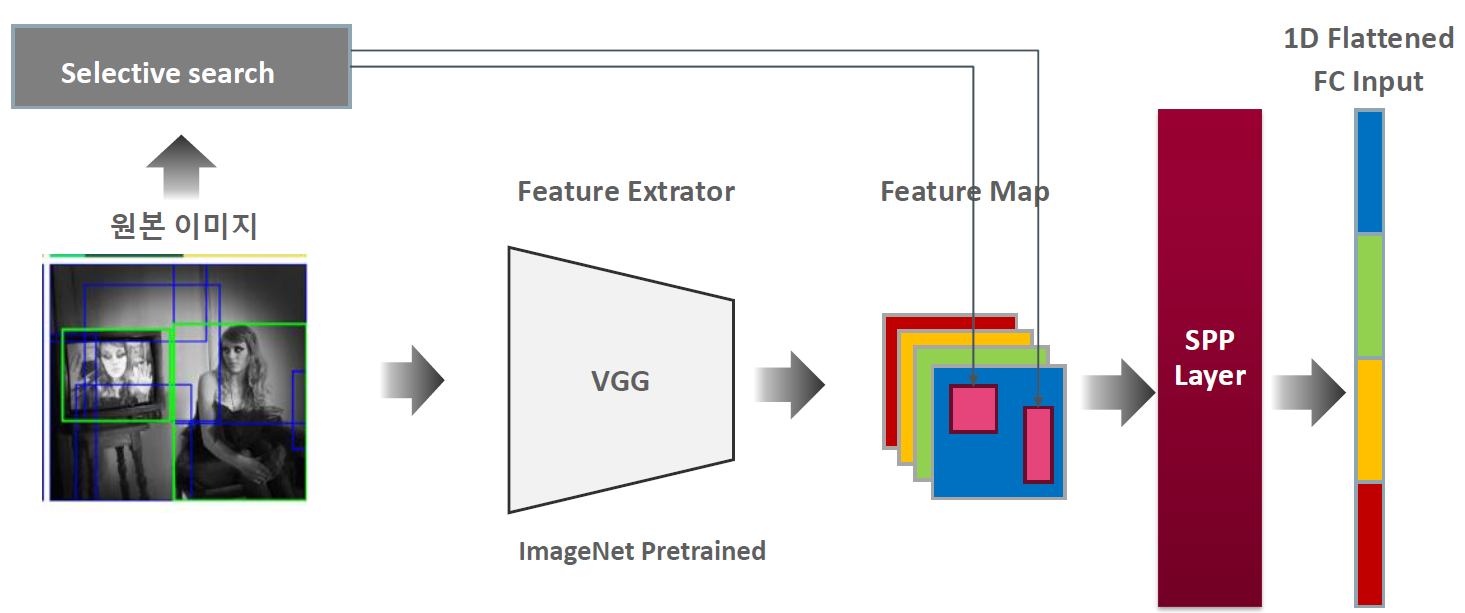
SPP-net 구조
앞서 SPP-net 구조를 간단히 알아봤는데, 이번에는 세부적으로 살펴봅시다.
먼저 SPP 계층에서 어떤 일을 하는지 알아보죠. 다음은 SPP 계층에서 수행하는 공간 피라미드 풀링(Spatial Pyramid Pooling, SPP) 예시입니다.
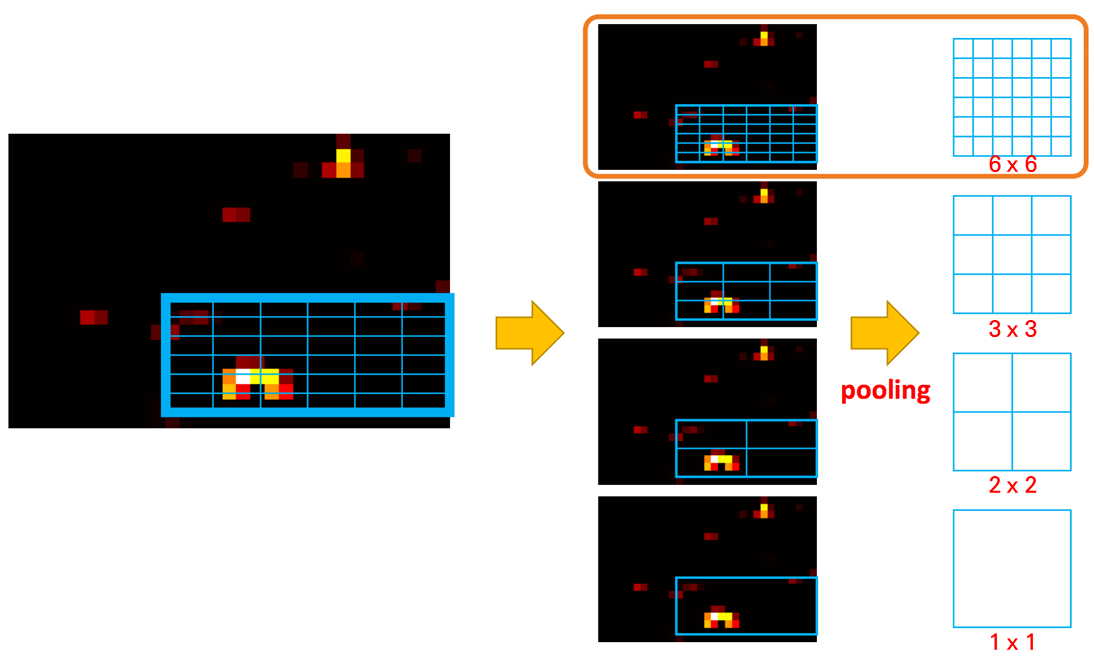
피처 맵 위에 표시한 후보 영역 경계 박스를 여러 단계로 나눕니다. 앞 예시는 (6 x 6), (3 x 3), (2 x 2), (1 x 1)로 격자를 나눠 최대풀링(Max Pooling)하는 예시입니다. 후보 영역을 여러 단계로 나누어 풀링한다고 해서 공간 피라미드 풀링이라고 부릅니다. 공간 피라미드 풀링을 적용하면 '피처 맵 위에 표시한 후보 영역 경계 박스'는 50개의 데이터로 압축됩니다. 6x6 + 3x3 + 2x2 + 1x1 = 50이기 때문이죠. 주목할 점을 후보 영역 경계 박스가 크든 작든, 가로세로 비율이 다르든 관계없이 50개의 데이터로 압축됩니다. 다음 그림을 보면 이해될 겁니다. 어떤 크기든 (2 x 2)로 격자를 나눠 풀링할 수 있기 때문에, 결괏값 크기는 4로 같습니다.

결국 SPP 계층은 전결합 계층에 입력하도록 데이터 크기를 일정하게 맞추는 역할을 합니다.
이제 SPP-net의 전체 구조를 보시죠.
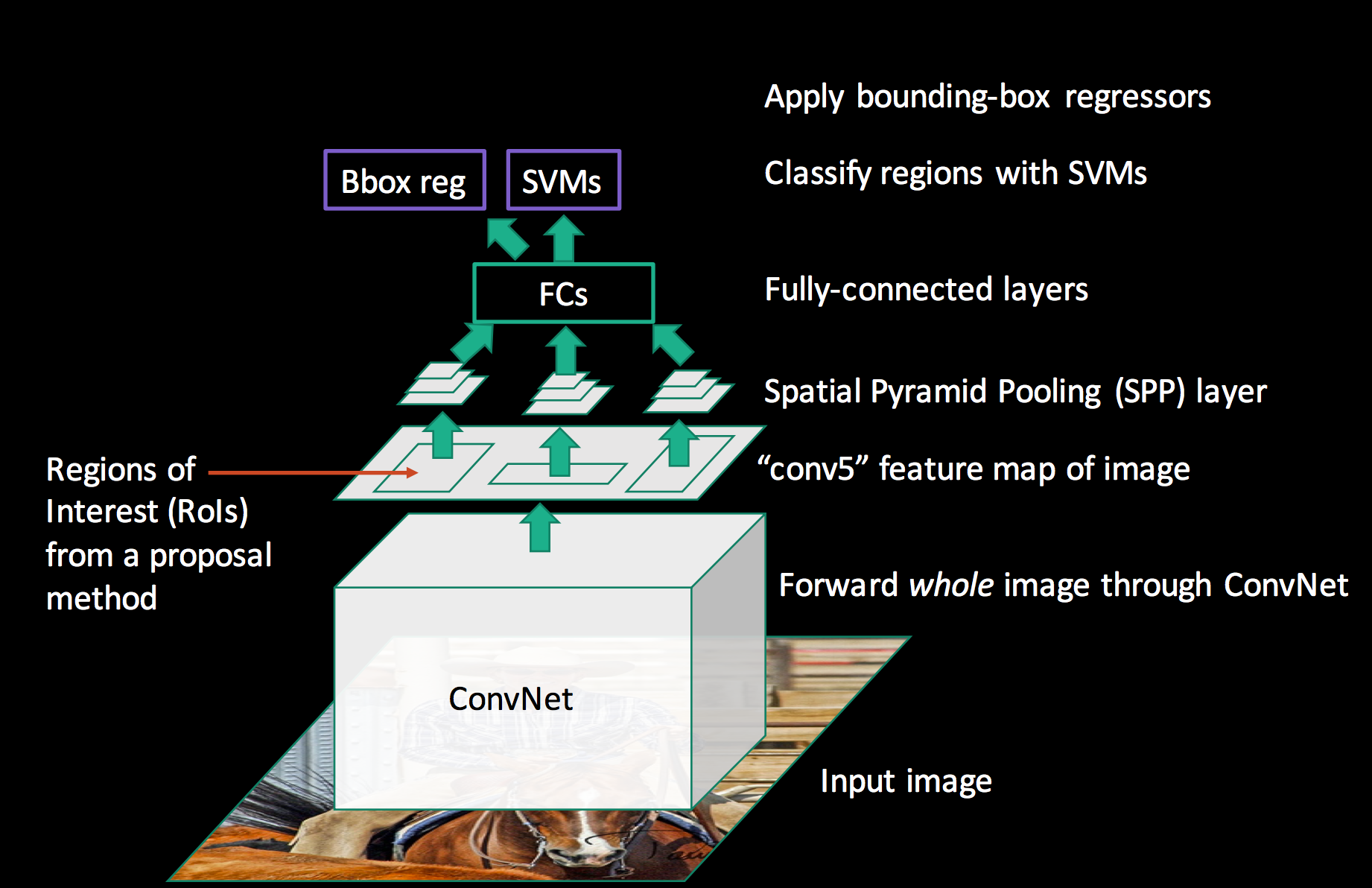
입력 이미지 전체를 한 번만 합성곱 연산합니다. 동시에 영역 추정도 해서 후보 영역 경계 박스도 구하고요. 이어서 피처 맵에 경계 박스를 표시합니다. 이 경계 박스들을 SPP 계층에 전달해 여러 피라미드로 최대 풀링해 데이터 크기를 일정하게 맞춥니다. 전결합 계층에 전달하기 위해서죠. 그다음은 R-CNN과 같습니다. SVM으로 분류를 수행하고, 별도로 경계 박스 회귀를 통해 객체가 있는 영역의 좌표값도 구합니다.
요약하면 R-CNN과 SPP-net은 한 이미지마다 CNN을 2,000번 거치는지, 한 번 거치는지 차이가 있습니다. SPP-net은 한 번만 CNN을 통과하는 대신 SPP 계층을 활용해 전결합 계층에 입력할 수 있도록 데이터 크기를 맞춰주고요.
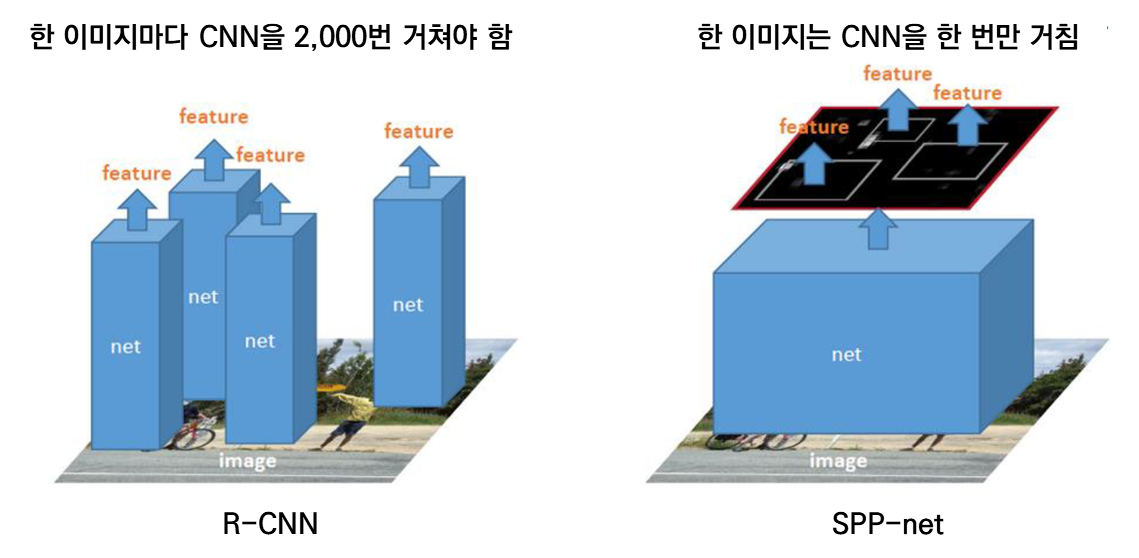
3. Fast R-CNN
Fast R-CNN은 SPP-net을 조금 변형한 네트워크입니다. SPP-net은 SPP 계층을 갖지만, Fast R-CNN은 SPP(spatial pyramid pooling) 계층 대신 RoI 풀링 계층을 갖습니다. RoI 풀링 계층은 Spp-net에서 사용하는 SPP계층과 비슷합니다. SPP 계층에 피라미드 단계가 딱 하나만 있는 경우로 볼 수 있습니다. SPP 계층과 마찬가지로 최대 풀링을 수행해서 작은 피처 맵으로 압축합니다. 단, 여러 격자를 갖는 SPP 계층과 달리 하나의 격자만 갖죠.

RoI 계층이 출력한 데이터는 전결합 계층에 입력합니다. 소프트맥스로 분류를 수행하고, 경계 박스 회귀를 통해 후보 영역 경계 박스를 더 최적화합니다(객체 위치를 제대로 나타내도록 좌표값을 조정한다는 말입니다). 분류를 소프트맥스로 수행했다는 점이 SPP-net과 다르네요. SPP-net은 별도 머신러닝 모델인 SVM으로 분류를 수행했으니 말이죠.
다음 두 그림은 Fast R-CNN의 구조를 나타냅니다.
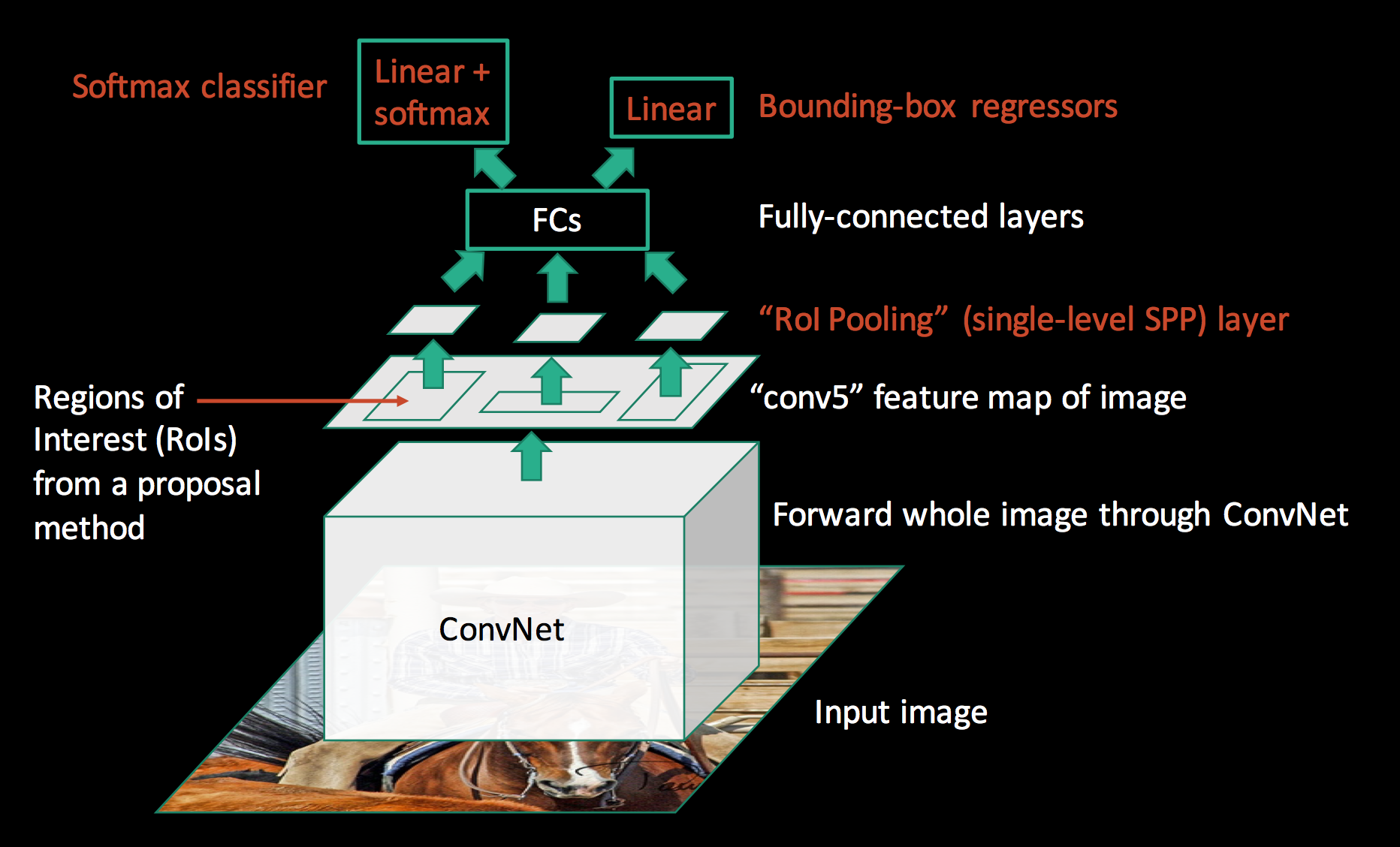
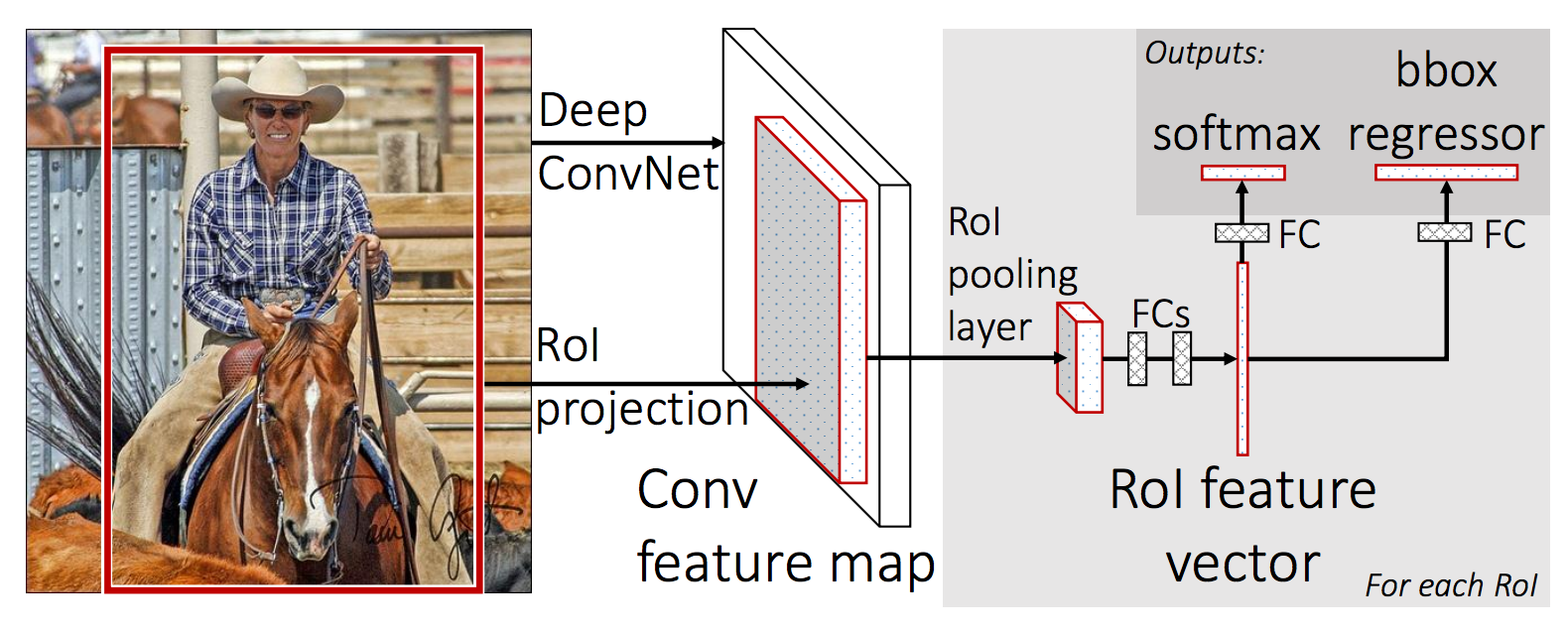
SPP-net과 Fast R-CNN은 또 다른 차이가 있습니다. SPP-net은 합성곱 계층은 고정된 채로 전결합층 이후로만 파인 튜닝이 가능했습니다. 반면 Fast R-CNN은 합성곱 계층을 포함해 네트워크 전체를 훈련할 수 있습니다. 참고로, 분류 계층의 손실 함수는 로그손실(log loss)이고, 회귀 계층의 손실 함수는 L1 손실 함수입니다. Fast R-CNN은 multi-task 손실 함수를 활용해 분류와 회귀를 함께 최적화합니다. 분류를 별도로 수행하지 않고, 딥러닝 모델 안으로 끌고 들어 왔으니 분류와 회귀를 한 번에 훈련할 수 있는 것입니다.
아래 그림은 SPP-net과 Fast R-CNN의 구조 차이를 보여줍니다.
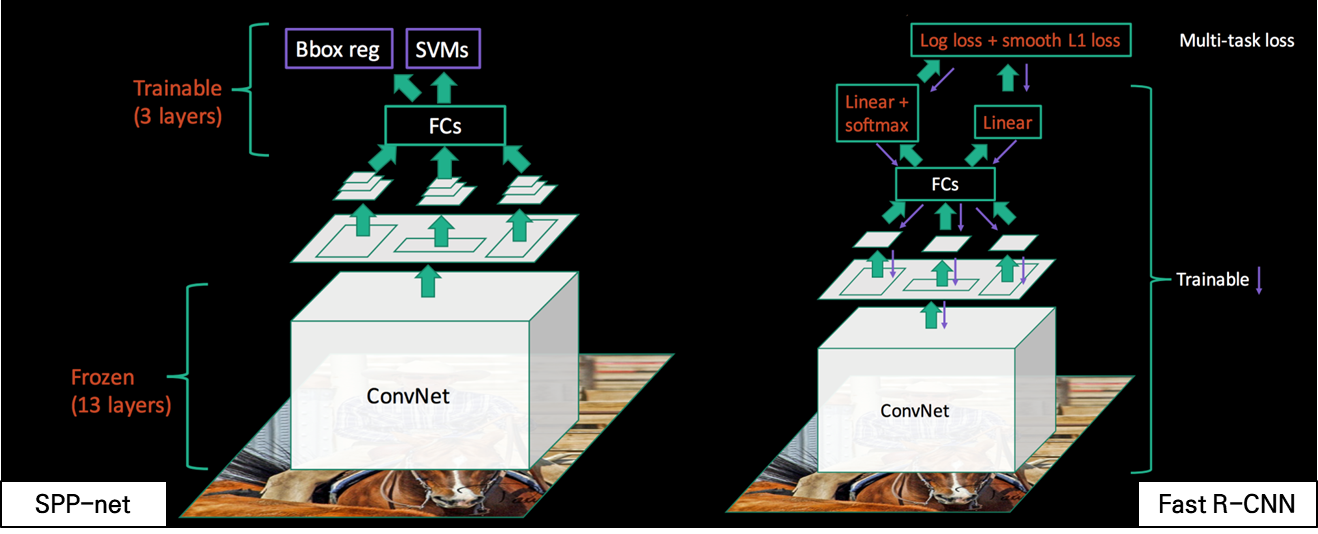
Fast R-CNN 객체 탐지 프로세스
그럼 종합해서 Fast R-CNN의 객체 탐지 프로세스를 설명해보겠습니다.
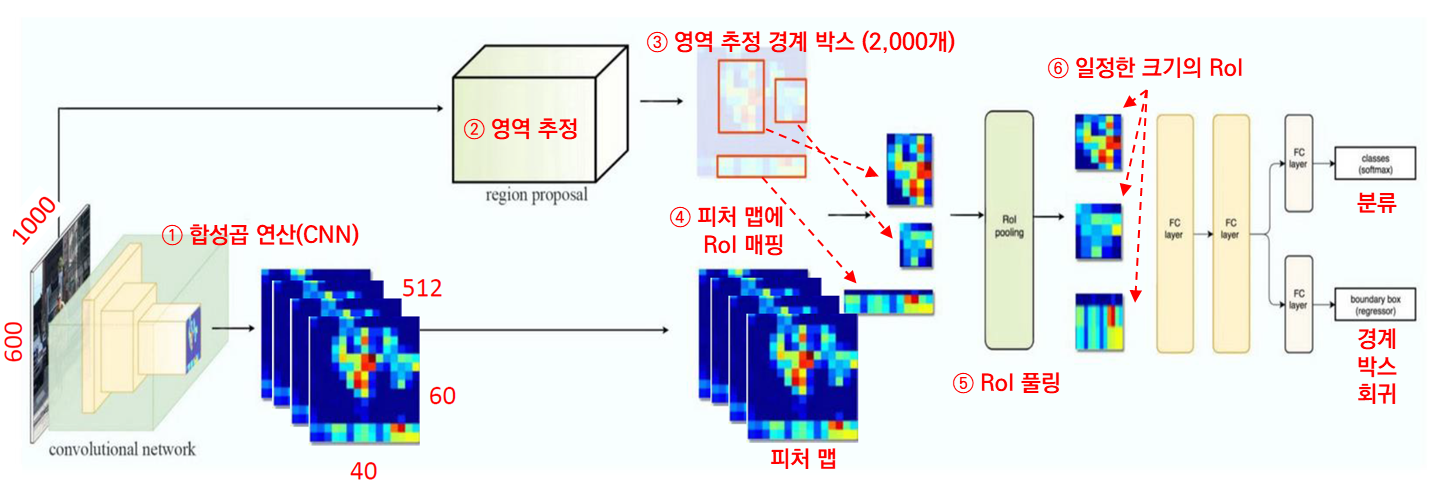
① 먼저 이미지 전체를 합성곱 연산합니다. 피처 맵이 구해지겠죠. ② 동시에 이미지 전체를 활용해 영역 추정도 합니다. ③ 영역 추정 경계 박스 2,000개를 만들어 둡니다. 앞서 구한 피처 맵에 ④ RoI(경계 박스)를 매핑합니다. RoI의 크기가 모두 다르죠? 크기를 일정하게 맞추기 위해 ⑤ RoI 풀링을 합니다. SPP-net에서는 여기서 공간 피라미드 풀링을 했죠? 피라미드 레벨(단계)을 여러 개로 나눠서 풀링을 했습니다. 반면 Fast R-CNN에서는 하나의 레벨로만 풀링을 수행합니다. 이게 RoI 풀링이죠. RoI 풀링을 거치면 ⑥ RoI가 일정한 크기로 바뀝니다. 일정한 크기로 바뀐 RoI를 전결합 계층에 입력합니다. 최종적으로 분류와 경계 박스 회귀를 수행하죠.
4. Faster R-CNN
RPN(Region Proposal Network, 영역 추정 네트워크)
기존 모델은 영역 추정 기법을 활용해 후보 영역을 구했습니다. 하지만 Faster R-CNN은 RPN(Region Proposal Network, 영역 추정 네트워크)을 훈련해 후보 영역을 구합니다. 영역 추정을 별도 모듈에서 할 필요가 없죠. 전체 이미지에 합성곱 연산을 한 뒤 구한 피처 맵을 RPN에 입력하고, RPN을 훈련하면 해당 RPN은 적절한 후보 영역을 구해줍니다.
Faster R-CNN은 기존 Fast R-CNN에 RPN을 더해 속도와 성능을 끌어올린 모델입니다. Faster R-CNN 이전 모델은 CPU에서 별도로 영역 추정을 했습니다. 따라서 영역 추정만으로도 시간이 꽤 걸렸죠. 반면 Faster R-CNN은 영역 추정도 GPU에서 수행합니다. 영역 추정을 합성곱 연산(CNN)으로 수행하기 때문이죠. 합성곱 연산으로 영역 추정을 하는 네트워크를 RPN라고 합니다. RPN 존재 여부가 Faster R-CNN과 Fast R-CNN의 가장 큰 차이입니다.
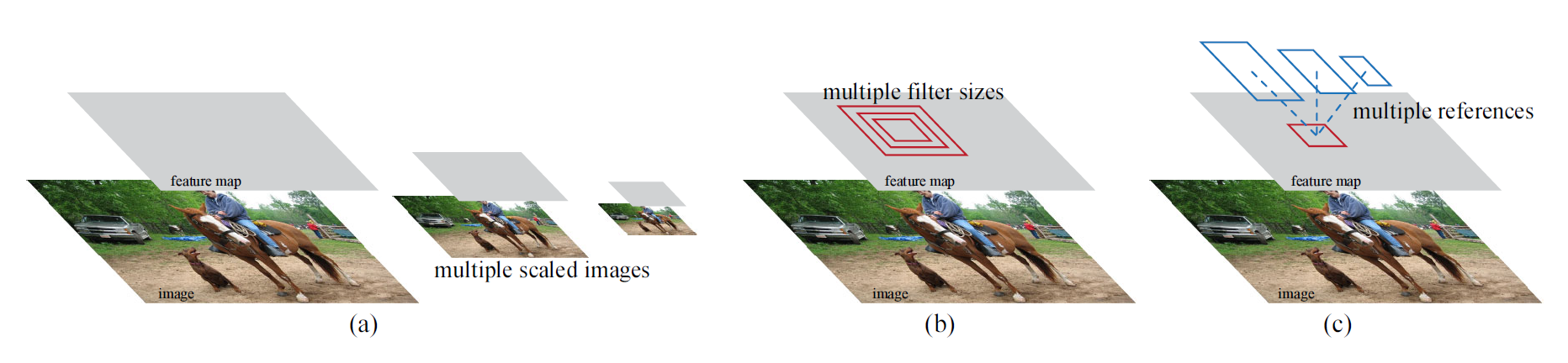
RPN은 다양한 스케일과 가로세로 비율을 갖는 영역 추정 경계 박스를 효과적으로 예측하도록 설계됐습니다. 이미지 피라미드(아래 그림에서 (a))나 필터 피라미드(아래 그림에서 (b)) 방식을 사용한 기존 모델과 다르게, Faster R-CNN은 앵커 박스(anchor boxes)를 사용합니다. 앵커 박스는 여러 스케일과 가로세로 비율을 갖습니다. 앵커 박스를 사용하면 다양한 스케일과 가로세로 비율을 갖는 이미지나 필터를 사용하지 않아도 되기 때문에, 다시 말해 단일 스케일 이미지만 사용해도 되기 때문에 속도가 빠릅니다.
Faster R-CNN 구조
Faster R-CNN 구조는 다음과 같습니다.
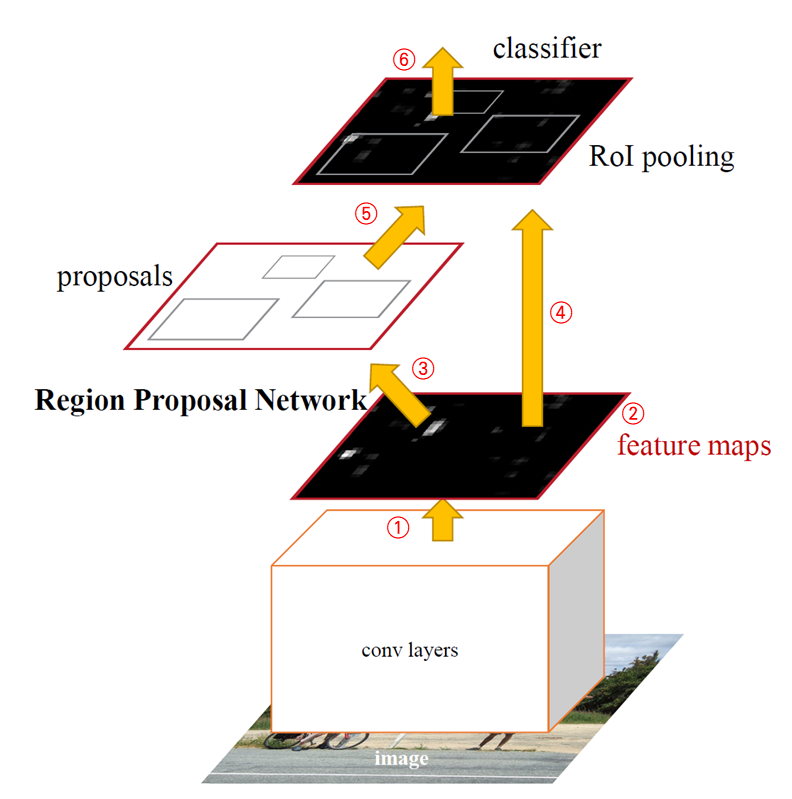
① 먼저 합성곱 계층을 활용해 전체 이미지에 합성곱 연산을 합니다. ② 그 결과 피처 맵을 구하죠. 피처 맵은 ③ RPN과 ④ 분류기(classifier)에 전달됩니다. 여기서 분류기는 Fast R-CNN에서 사용한 분류기와 같습니다. 피처 맵이 RPN과 분류기에 동시에 전달된다는 말은 RPN과 분류기가 피처 맵을 공유해서 사용한다는 뜻입니다. ③ RPN은 피처 맵을 기반으로 객체가 있을 만한 곳을 찾아줍니다. 곧, 영역 추정을 합니다. 이어서 ⑤ 영역 추정 결과를 RoI 풀링합니다. ⑥ 최종적으로, 피처 맵과 영역 추정 경계 박스를 활용해 객체 탐지를 수행합니다. 여기서 RPN은 객체가 어디에 있을지, 즉, 탐지기가 어디에 주목을 해야 하는지 말해줍니다. 어텐션 메커니즘과 비슷하죠. 이렇듯 Faster R-CNN은 영역 추정과 이미지 분류 모두를 하나의 통합 네트워크에서 수행합니다. 영역 추정을 독립된 모듈(CPU에서)로 수행하는 Fast R-CNN과 다르죠.
앵커 박스
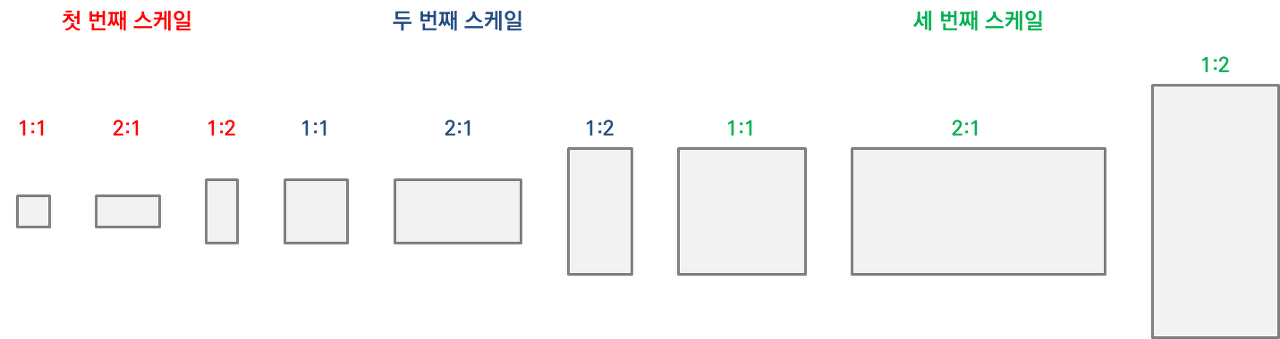
RPN에서 사용하는 경계 박스를 앵커 박스(anchor box)라고 합니다. Faster R-CNN 이전 모델에서는 영역 추정으로 경계 박스를 구했습니다. 하지만 Faster R-CNN에서는 영역 추정을 따로 하지 않고 RPN을 훈련해서 후보 영역을 구한다고 했죠. 이때 사용하는 경계 박스를 앵커 박스라고 하죠. 보통 앵커 박스를 9개 사용합니다. 3가지 스케일과 3가지 가로세로 비율(1:1, 2:1, 1:2)을 결합해 앵커 박스를 만들죠. 다음과 같이 말이죠.
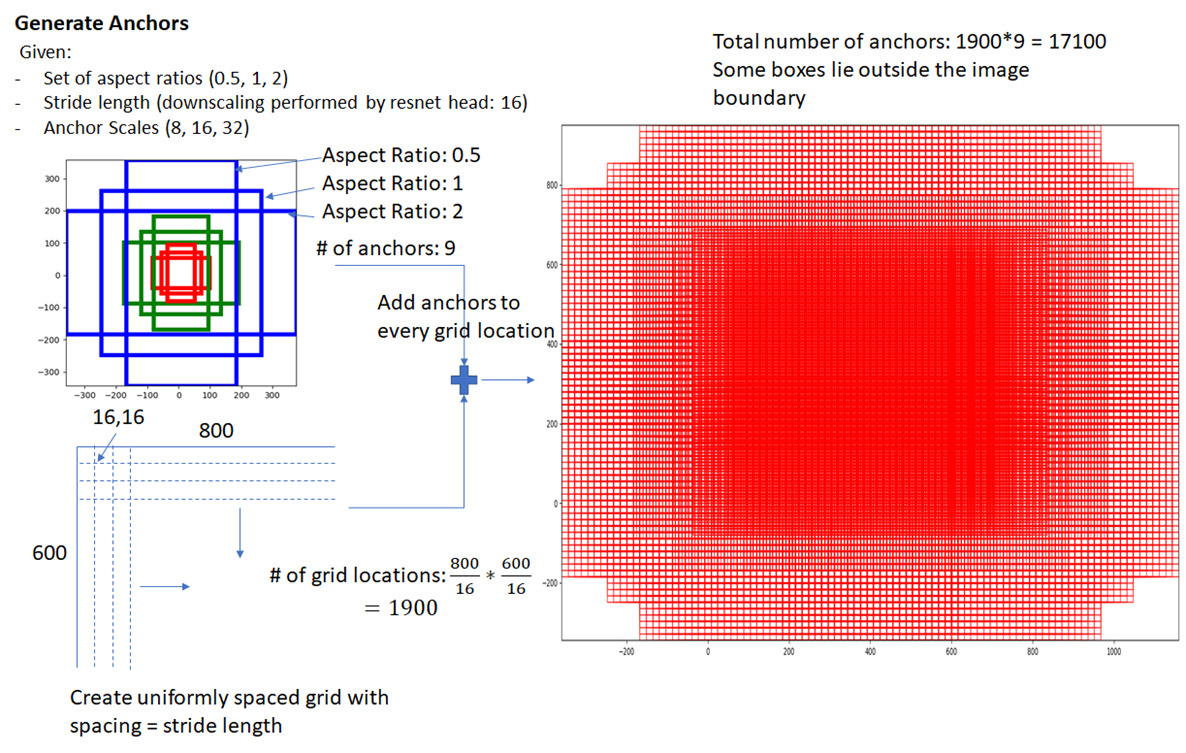
Faster R-CNN에서는 기존에 사용하던 이미지 피라미드, 필터 피라미드보다 더 빠르고 효율적인 앵커 피라미드(pyramids of anchors) 방식을 사용합니다. 다양한 크기의 앵커 박스를 활용해 객체 분류, 경계 박스 회귀를 수행하죠.
'합성곱 연산을 거친 피처 맵'에 촘촘하게 점(그리드)을 찍은 뒤(실제로 점을 찍는다는 말이 아니라 위치만 표시한다는 말), 모든 점(그리드)마다 앵커 박스 9개를 구합니다. 그러면 앵커 박스가 서로 굉장히 많이 겹치겠죠. 크기도 9개니 다양하고요. 이렇게 구한 많은 앵커 박스를 바탕으로 후보 영역 추정을 위해 훈련한다는 뜻입니다. 다음 그림은 앵커 박스 예시입니다. (800, 600) 크기를 갖는 이미지에 합성곱 연산을 해서 (800/16, 600/16) 크기의 피처 맵을 만듭니다. 이 피처 맵 위에 1,900개(= 800/16 * 600/16)의 그리드를 표시합니다. 1,900개의 각 그리드마다 앵커 박스를 9개씩 그립니다. 그러면 앵커 박스는 총 17,100개(=1,900 * 9)가 되겠죠. 앵커 박스가 이렇게나 많고 다양하니 어떤 객체든 포함할 겁니다. RPN은 이런 앵커 박스를 바탕으로 훈련해서 후보 영역을 추정해줍니다.
지금까지 초기 객체 탐지 모델인 R-CNN, SPP-net, Fast R-CNN, Faster R-CNN의 전체적인 구조를 알아봤습니다.
참고 자료
Fei-Fei Li & Andrej Karpathy & Justin Johnson - "Spatial Localization and Detection"
R-CNN 논문, SPP-net 논문, Fast R-CNN 논문, Faster R-CNN 논문
Yugesh Verma - "R-CNN vs Fast R-CNN vs Faster R-CNN – A Comparative Guide"
'컴퓨터 비전' 카테고리의 다른 글
| 컴퓨터 비전 - 12. 자세 추정(Pose Estimation)이란? (2) | 2023.06.02 |
|---|---|
| 컴퓨터 비전 - 11. YOLO v1, v2, v3 개요와 실습 (0) | 2023.05.06 |
| 컴퓨터 비전 - 9. 객체 탐지(Object Detection) 개요 (4) | 2023.03.14 |
| 컴퓨터 비전 - 8. 오토인코더 실습 (1) | 2023.03.13 |
| 컴퓨터 비전 - 7. 오토인코더(AutoEncoder)와 매니폴드 학습(Manifold Learning) (4) | 2023.03.12 |



