
귀퉁이 서재
머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting) 본문
머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)
Baek Kyun Shin 2019. 9. 12. 21:49
앙상블(Ensemble)
앙상블은 조화 또는 통일을 의미합니다.
어떤 데이터의 값을 예측한다고 할 때, 하나의 모델을 활용합니다. 하지만 여러 개의 모델을 조화롭게 학습시켜 그 모델들의 예측 결과들을 이용한다면 더 정확한 예측값을 구할 수 있을 겁니다.
앙상블 학습은 여러 개의 결정 트리(Decision Tree)를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신러닝 기법입니다. 앙상블 학습의 핵심은 여러 개의 약 분류기 (Weak Classifier)를 결합하여 강 분류기(Strong Classifier)를 만드는 것입니다. 그리하여 모델의 정확성이 향상됩니다.
앙상블 학습법에는 두 가지가 있습니다. 배깅(Bagging)과 부스팅(Boosting)입니다. 이를 이해하기 위해서는 부트스트랩(Bootstrap)과 결정 트리(Deicison Tree)에 대한 개념이 선행되어야 합니다. 부트스트랩과 결정 트리에 대해 잘 모르신다면 (DATA - 12. 부트스트랩(Bootstrap))과 (머신러닝 - 4. 결정 트리(Decision Tree))를 참고하시기 바랍니다.
배깅(Bagging)
Bagging은 Bootstrap Aggregation의 약자입니다. 배깅은 샘플을 여러 번 뽑아(Bootstrap) 각 모델을 학습시켜 결과물을 집계(Aggregration)하는 방법입니다. 아래 그림을 보겠습니다.

우선, 데이터로부터 부트스트랩을 합니다. (복원 랜덤 샘플링) 부트스트랩한 데이터로 모델을 학습시킵니다. 그리고 학습된 모델의 결과를 집계하여 최종 결과 값을 구합니다.
Categorical Data는 투표 방식(Votinig)으로 결과를 집계하며, Continuous Data는 평균으로 집계합니다.
Categorical Data일 때, 투표 방식으로 한다는 것은 전체 모델에서 예측한 값 중 가장 많은 값을 최종 예측값으로 선정한다는 것입니다. 6개의 결정 트리 모델이 있다고 합시다. 4개는 A로 예측했고, 2개는 B로 예측했다면 투표에 의해 4개의 모델이 선택한 A를 최종 결과로 예측한다는 것입니다.
평균으로 집계한다는 것은 말 그대로 각각의 결정 트리 모델이 예측한 값에 평균을 취해 최종 Bagging Model의 예측값을 결정한다는 것입니다.
배깅은 간단하면서도 파워풀한 방법입니다. 배깅 기법을 활용한 모델이 바로 랜덤 포레스트입니다.
부스팅(Boosting)
부스팅은 가중치를 활용하여 약 분류기를 강 분류기로 만드는 방법입니다. 배깅은 Deicison Tree1과 Decision Tree2가 서로 독립적으로 결과를 예측합니다. 여러 개의 독립적인 결정 트리가 각각 값을 예측한 뒤, 그 결과 값을 집계해 최종 결과 값을 예측하는 방식입니다. 하지만 부스팅은 모델 간 팀워크가 이루어집니다. 처음 모델이 예측을 하면 그 예측 결과에 따라 데이터에 가중치가 부여되고, 부여된 가중치가 다음 모델에 영향을 줍니다. 잘못 분류된 데이터에 집중하여 새로운 분류 규칙을 만드는 단계를 반복합니다. 아래 그림을 통해 설명해보겠습니다.
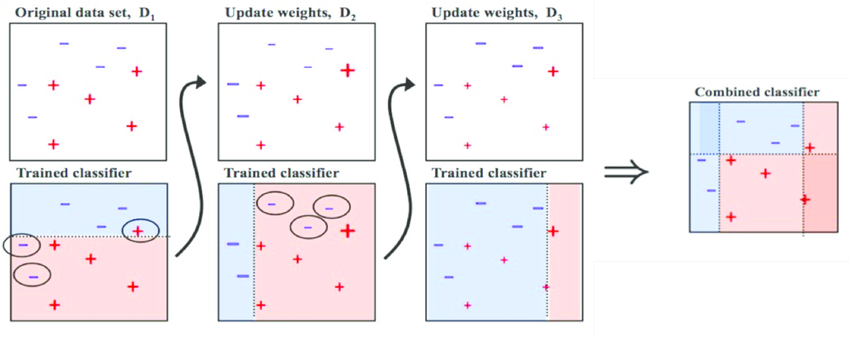
+와 -로 구성된 데이터셋을 분류하는 문제입니다.
D1에서는 2/5 지점을 횡단하는 구분선으로 데이터를 나누어주었습니다. 하지만 위쪽의 +는 잘못 분류가 되었고, 아래쪽의 두 -도 잘못 분류되었습니다. 잘못 분류가 된 데이터는 가중치를 높여주고, 잘 분류된 데이터는 가중치를 낮추어 줍니다.
D2를 보면 D1에서 잘 분류된 데이터는 크기가 작아졌고(가중치가 낮아졌고) 잘못 분류된 데이터는 크기가 커졌습니다.(가중치가 커졌습니다.) 분류가 잘못된 데이터에 가중치를 부여해주는 이유는 다음 모델에서 더 집중해 분류하기 위함입니다. D2에서는 오른쪽 세 개의 -가 잘못 분류되었습니다.
따라서 D3에서는 세 개의 -의 가중치가 커졌습니다. 맨 처음 모델에서 가중치를 부여한 +와 -는 D2에서는 잘 분류가 되었기 때문에 D3에서는 가중치가 다시 작아졌습니다.
D1, D2, D3의 Classifier를 합쳐 최종 Classifier를 구할 수 있습니다. 최종 Classfier는 +와 -를 정확하게 구분해줍니다.
배깅과 부스팅 차이

위 그림에서 나타내는 바와 같이 배깅은 병렬로 학습하는 반면, 부스팅은 순차적으로 학습합니다. 한번 학습이 끝난 후 결과에 따라 가중치를 부여합니다. 그렇게 부여된 가중치가 다음 모델의 결과 예측에 영향을 줍니다.
오답에 대해서는 높은 가중치를 부여하고, 정답에 대해서는 낮은 가중치를 부여합니다. 따라서 오답을 정답으로 맞추기 위해 오답에 더 집중할 수 있게 되는 것입니다.
부스팅은 배깅에 비해 error가 적습니다. 즉, 성능이 좋습니다. 하지만 속도가 느리고 오버 피팅이 될 가능성이 있습니다. 그렇다면 실제 사용할 때는 배깅과 부스팅 중 어떤 것을 선택해야 할까요? 상황에 따라 다르다고 할 수 있습니다. 개별 결정 트리의 낮은 성능이 문제라면 부스팅이 적합하고, 오버 피팅이 문제라면 배깅이 적합합니다.
References
Reference1: Medium (Ensemble Learning - Bagging and Boosting)
'머신러닝' 카테고리의 다른 글
| 머신러닝 - 13. 파라미터(Parameter)와 하이퍼 파라미터(Hyper parameter) (12) | 2019.09.27 |
|---|---|
| 머신러닝 - 12. 편향(Bias)과 분산(Variance) Trade-off (0) | 2019.09.13 |
| 머신러닝 - 10. 교차검증(Cross Validation)과 혼동행렬(Confusion Matrix) (0) | 2019.08.13 |
| 머신러닝 - 9. 차원 축소와 PCA (Principal Components Analysis) (9) | 2019.08.11 |
| 머신러닝 - 8. Feature Scaling & Feature Selection (0) | 2019.08.04 |



