
귀퉁이 서재
머신러닝 - 15. 그레디언트 부스트(Gradient Boost) 본문

앙상블 방법론에는 부스팅과 배깅이 있습니다. (머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)) 배깅의 대표적인 모델은 랜덤 포레스트가 있고, 부스팅의 대표적인 모델은 AdaBoost, Gradient Boost등이 있습니다. Gradient Boost의 변형 모델로는 XGBoost, LightGBM, CatBoost가 있습니다. XGBoost, LightGBM, CatBoost은 캐글에서 Top Ranker들이 많이 사용하고 있는 모델입니다. XGBoost, LightGBM, CatBoost에 대해서는 추후 알아보도록 하고, 이번 글에서는 Gradient Boost에 대해 알아보겠습니다.
본 글은 StatQuest의 Gradient Boost 유튜브를 정리한 글입니다. 많은 자료 중 Gradient Boost를 가장 이해하기 쉽게 잘 설명을 해놓은 동영상 자료입니다. Gradient Boost는 회귀와 분류에 모두 사용할 수 있는 모델입니다. 본 글은 회귀를 기준으로 설명을 했습니다. 분류도 일부 계산 절차가 다를 뿐 프로세스는 이와 유사합니다.
Gradient Boost를 이해하기 위해 사전지식으로 AdaBoost에 대해 알고 있으면 좋습니다.
AdaBoost와 Gradient Boost의 차이
AdaBoost는 stump로 구성되어 있습니다. 하나의 stump에서 발생한 error가 다음 stump에 영향을 줍니다. 이런식으로 여러 stump가 순차적으로 연결되어 최종 결과를 도출합니다.
반면, Gradient Boost는 stump나 tree가 아닌 하나의 leaf (single leaf)부터 시작합니다. 이 leaf는 타겟 값에 대한 초기 추정 값을 나타냅니다. 보통은 초기 추정 값을 평균으로 정합니다. 그 다음은 AdaBoost와 동일하게 이전 tree의 error는 다음 tree에 영향을 줍니다. 하지만 AdaBoost와 다르게 stump가 아닌 tree로 구성되어 있습니다. 보통은 leaf가 8개에서 32개되는 tree로 구성합니다.
Gradient Boost 프로세스
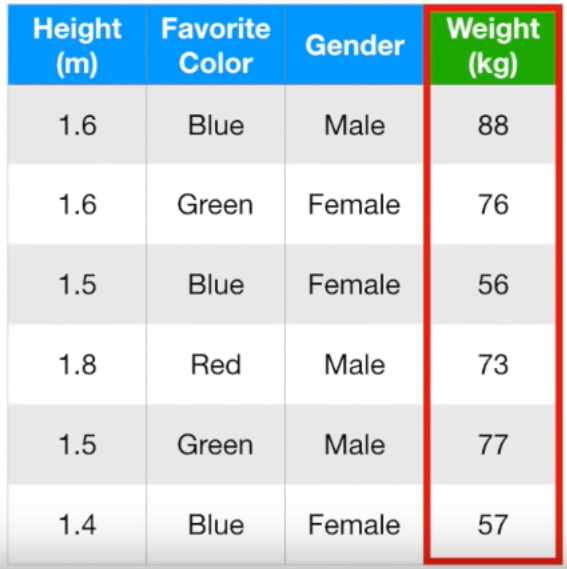
키, 좋아하는 색깔, 성별을 기반으로 몸무게를 예측하는 Gradient Boost 모델을 만들어보겠습니다.
Gradient Boost는 single leaf부터 시작하며, 그 single leaf 모델이 예측하는 타겟 추정 값은 모든 타겟 값의 평균이라고 했습니다.
(88 + 76 + 56 + 73 + 77 + 57) / 6 = 71.2
따라서, single leaf로 몸무게를 예측한다면 모든 사람은 71.2kg이라고 할 겁니다. 하지만 여기서 멈추면 안되겠죠!

single leaf에서 예측한 값과 실제 값의 차이(error)를 반영한 새로운 트리를 만들어야 합니다. 위 그림에서는 편의상 leaf가 4개인 트리를 그렸지만 실제로는 leaf가 8개에서 32개인 트리를 주로 씁니다.
error를 구해보겠습니다. 첫행의 실제 몸무게 값은 88kg인데 앞서 말씀드린 것처럼 leaf는 71.2kg로 예측했습니다. 따라서 차이는 16.8kg (=88kg - 71.2kg)입니다. 이를 Pseudo Residual이라고 합니다. 모든 행의 Pseudo Residual은 아래와 같습니다.
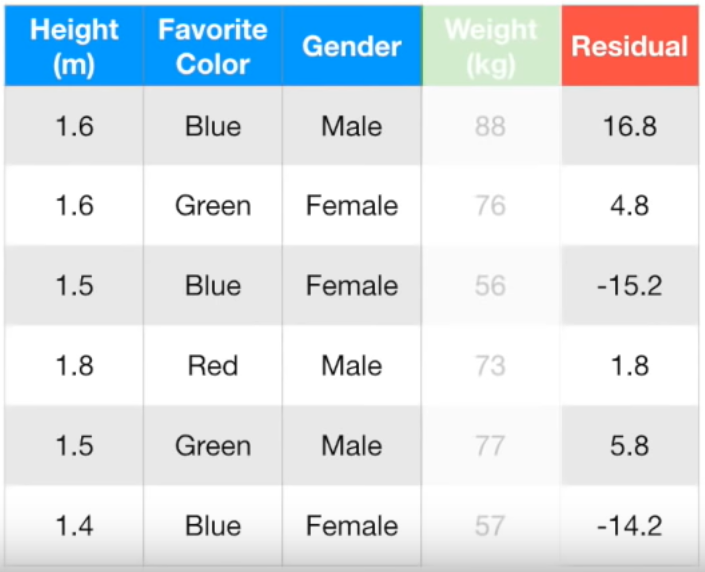
키, 좋아하는 색깔, 성별을 통해 Residual을 예측하는 트리를 만들어 보겠습니다. 몸무게가 아니라 Residual을 예측한다고요? 의아할 수 있겠지만 아래 글을 다 읽으면 왜 그런지 이해하실 수 있을 겁니다.
모델은 아래와 같이 만들었습니다. 맨 처음 노드에선 성별이 여자면 왼쪽, 남자면 오른쪽으로 갑니다. 두번째 노드에선 각각 키가 1.6m 미만이면 왼쪽, 이상이면 오른쪽, 좋아하는 색깔이 파란색이 아니면 왼쪽, 맞으면 오른쪽으로 갑니다.
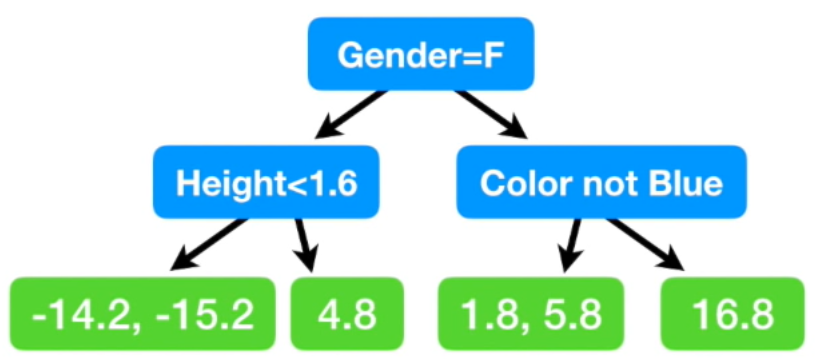
여기서 마지막 leaf 노드에 두개의 residual 값이 있는 경우가 있습니다. 그럴 땐 두 값의 평균으로 치환해 넣어주면 됩니다. {(-14.2) + (-15.2)} / 2 = -14.7이므로 -14.7을 첫번째 leaf 노드에 넣습니다. 세번째 leaf 노드도 마찬가지로 평균 값을 넣어줍니다.

이제, 초기에 구한 트리(여기서는 single leaf)와 두번째로 구한 트리를 조합하여 몸무게를 예측해보겠습니다.
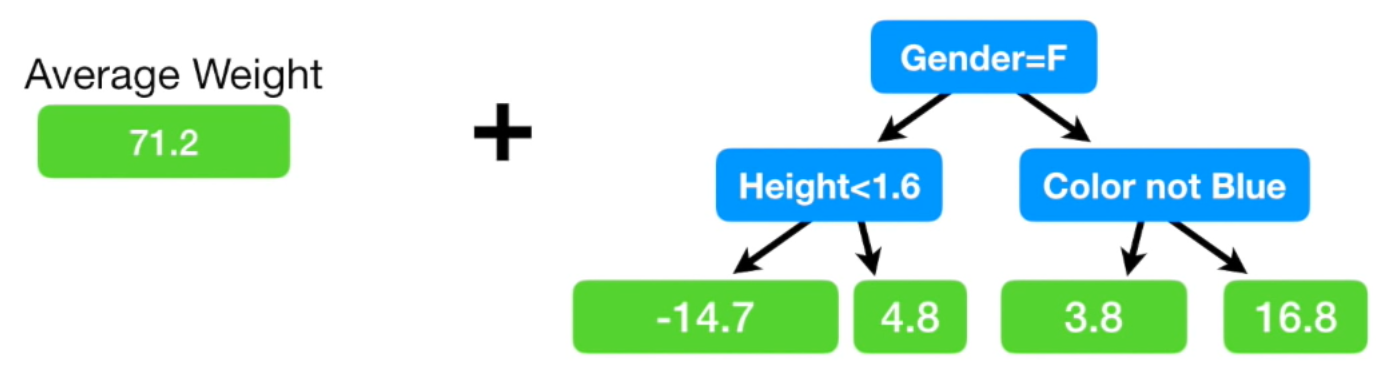
두번째 트리에서 성별이 남자고, 좋아하는 색깔이 파란색이면 residual을 16.8로 예측했습니다.
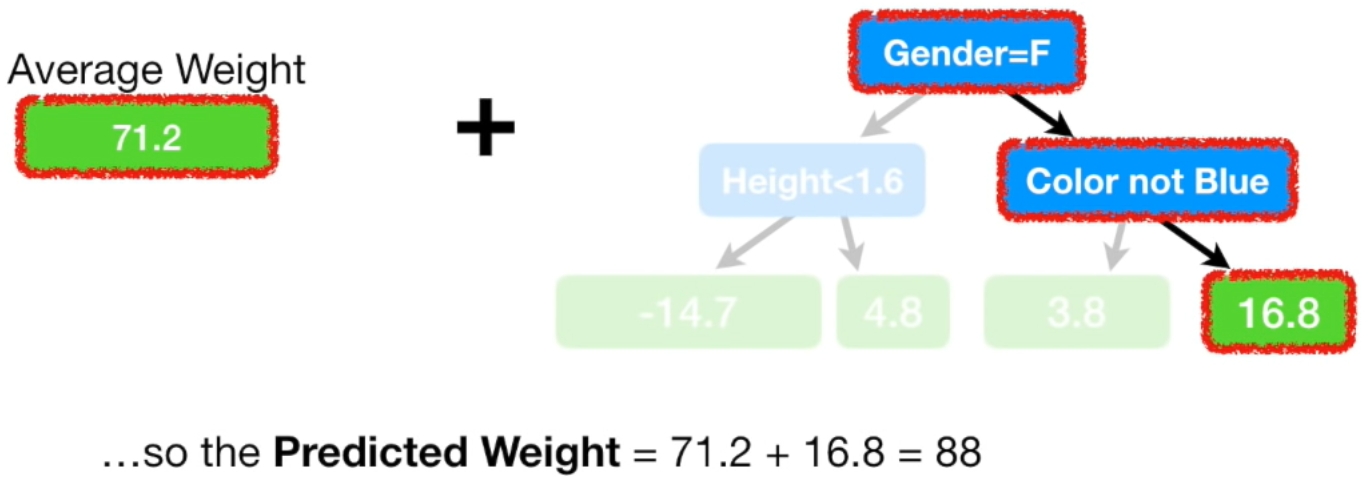
첫번째 트리의 몸무게 예측 값인 71.2kg와 두번째 트리의 residual 예측 값인 16.8kg을 더하면 88kg이 됩니다. 즉, 성별이 남자고, 좋아하는 색깔이 파란색이면 그 사람의 몸무게는 88kg라고 예측을 한 겁니다.
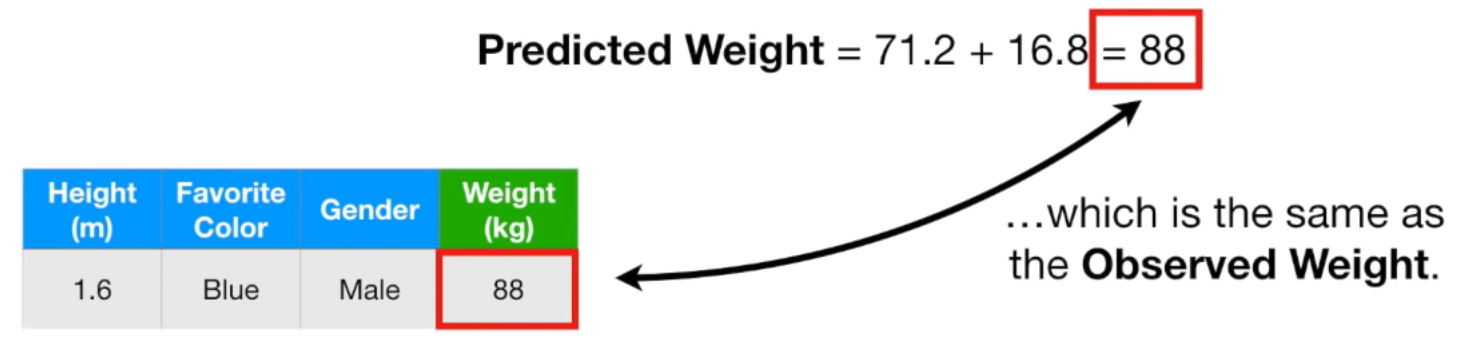
우리가 만들어준 모델이 예측한 몸무게와 실제 몸무게가 88kg으로 일치합니다. 놀라우신가요? 놀랄 일이 아닙니다. 이는 훈련 데이터에 너무 fit한 모델입니다. 즉 과적합 모델이라는 거죠. Bias는 작지만, Variance는 굉장히 클 수 있습니다. (Bias와 Variance에 대한 내용은 머신러닝 - 12. 편향(Bias)과 분산(Variance) Trade-off를 참고해주시기 바랍니다.
훈련 속도를 조절하거나 과적합 문제를 해결하기 위해 학습률(Learning Rate)이라는 값을 활용합니다. 학습률은 0부터 1사이의 값을 가집니다. Residual을 예측하는 모델에 학습률을 곱해줌으로써 과적합을 해결할 수 있습니다. 참고로, 학습률은 하이퍼 파라미터라서 우리가 직접 설정해줘야 합니다. 상황에 따라 다르지만 보통 0.1 ~ 0.001 범위의 값을 사용합니다.
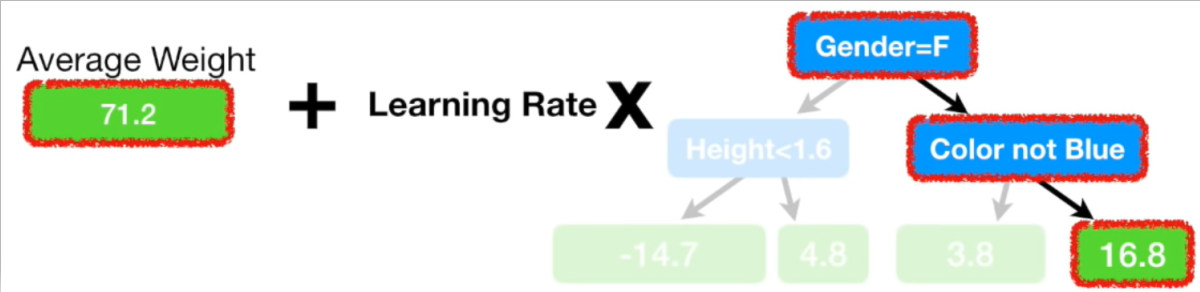
본 예제에선 학습률을 0.1로 세팅해보겠습니다.
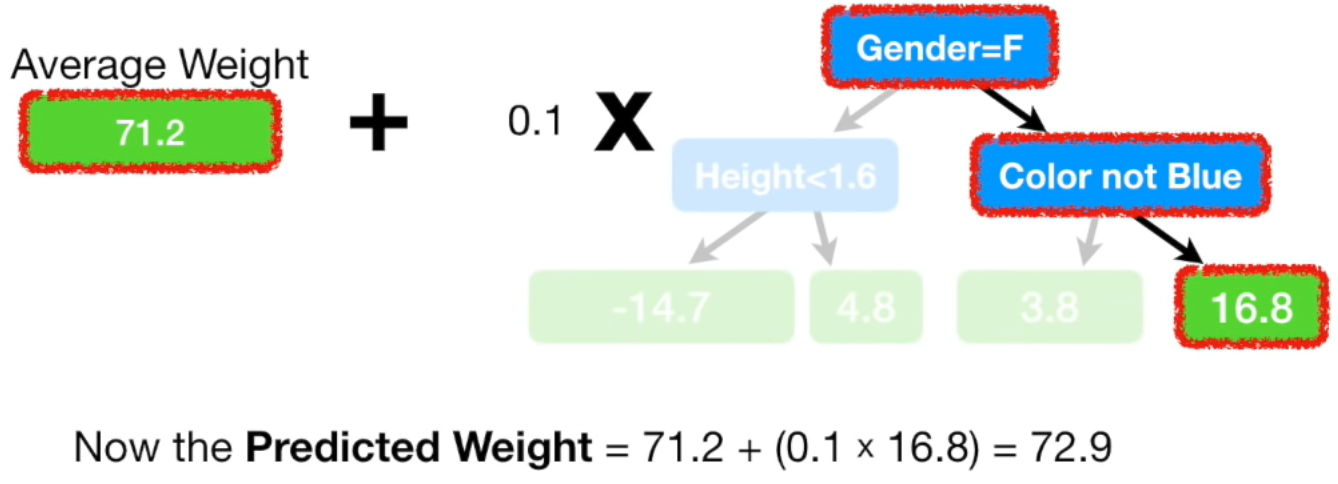
학습률이 0.1일 경우 모델이 예측한 몸무게는 72.9kg입니다. 첫 single leaf 모델이 예측한 71.2kg보다는 실제 값(88kg)에 더 가까워졌습니다. Gradient Boost 모델은 이런식으로 실제 값에 조금씩 가까워지는 방향으로 학습을 합니다.
Empirical evidence shows that taking lots of small steps in the right direction results in better predictions with a testing dataset, i.e. lower variance
- Jerome Friedman, Gardient Boost inventor -
올바른 방향으로 (즉, 실제 값과 가까워지는 방향으로) 조금씩 다가가는 식으로 학습된 모델은 테스트 데이터에서 좋은 성능을 보여준다고 합니다.
올바른 방향으로 한 걸음 더 가봅시다! 지금까지 만든 모델을 기반으로 Pseudo Residual을 다시 구해보겠습니다.
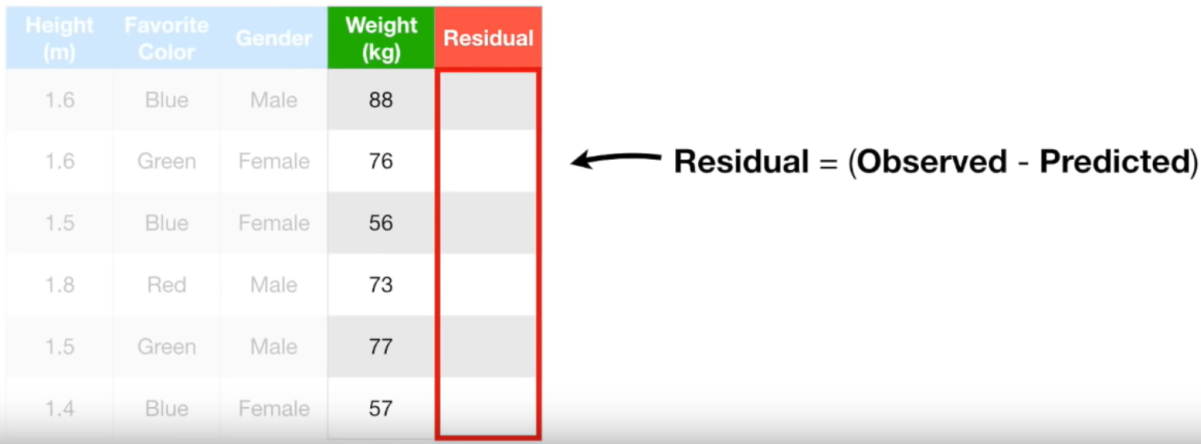
앞서 설명드린 것처럼 Pseudo Residual은 실제값 - 예측값입니다.
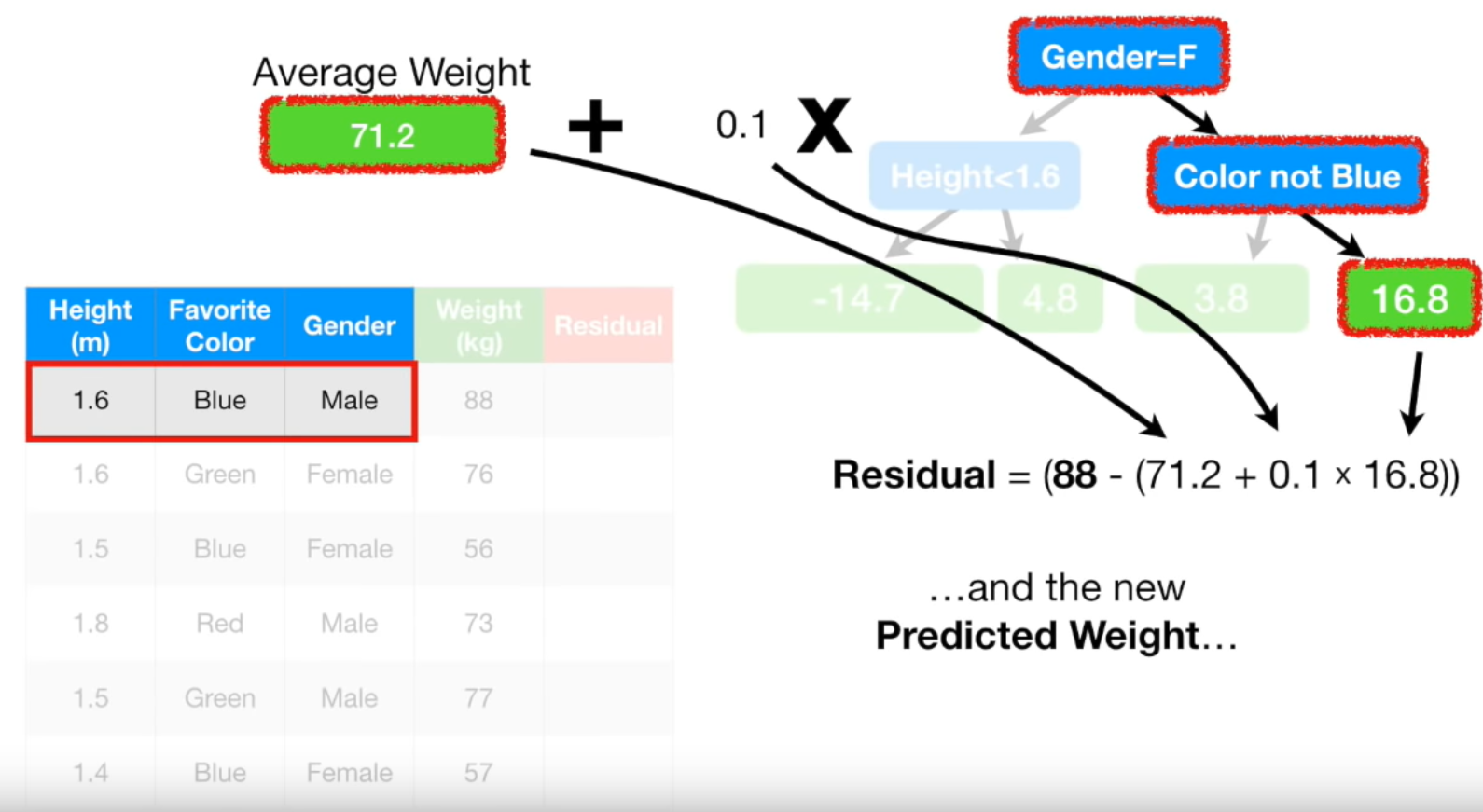
첫번째 데이터를 예로 들면, 실제값은 88kg이고 새로운 모델의 예측값은 71.2 + 0.1 * 16.8 입니다. 따라서 Pseudo Residual은 88 - (71.2 + 0.1 * 16.8) = 15.1kg입니다. 새로 구한 Pseudo Residual을 아래와 같습니다.
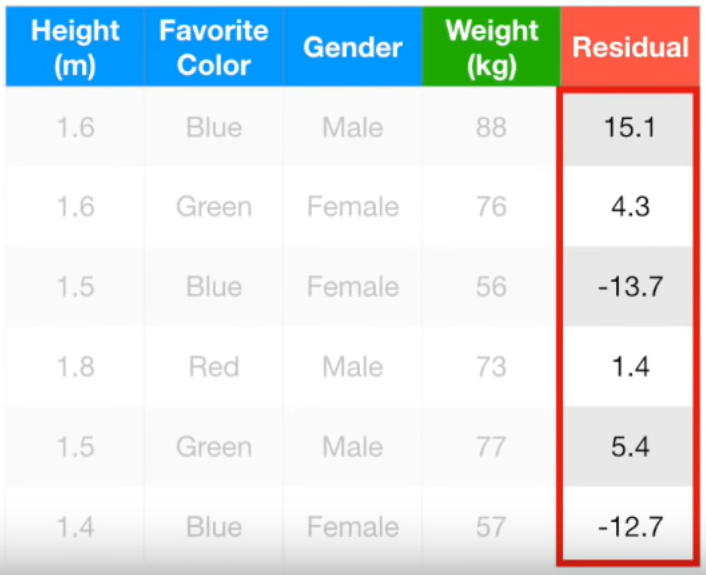
맨 처음 구한 Residual과 결합된 모델로 구한 Residual을 비교해보겠습니다.
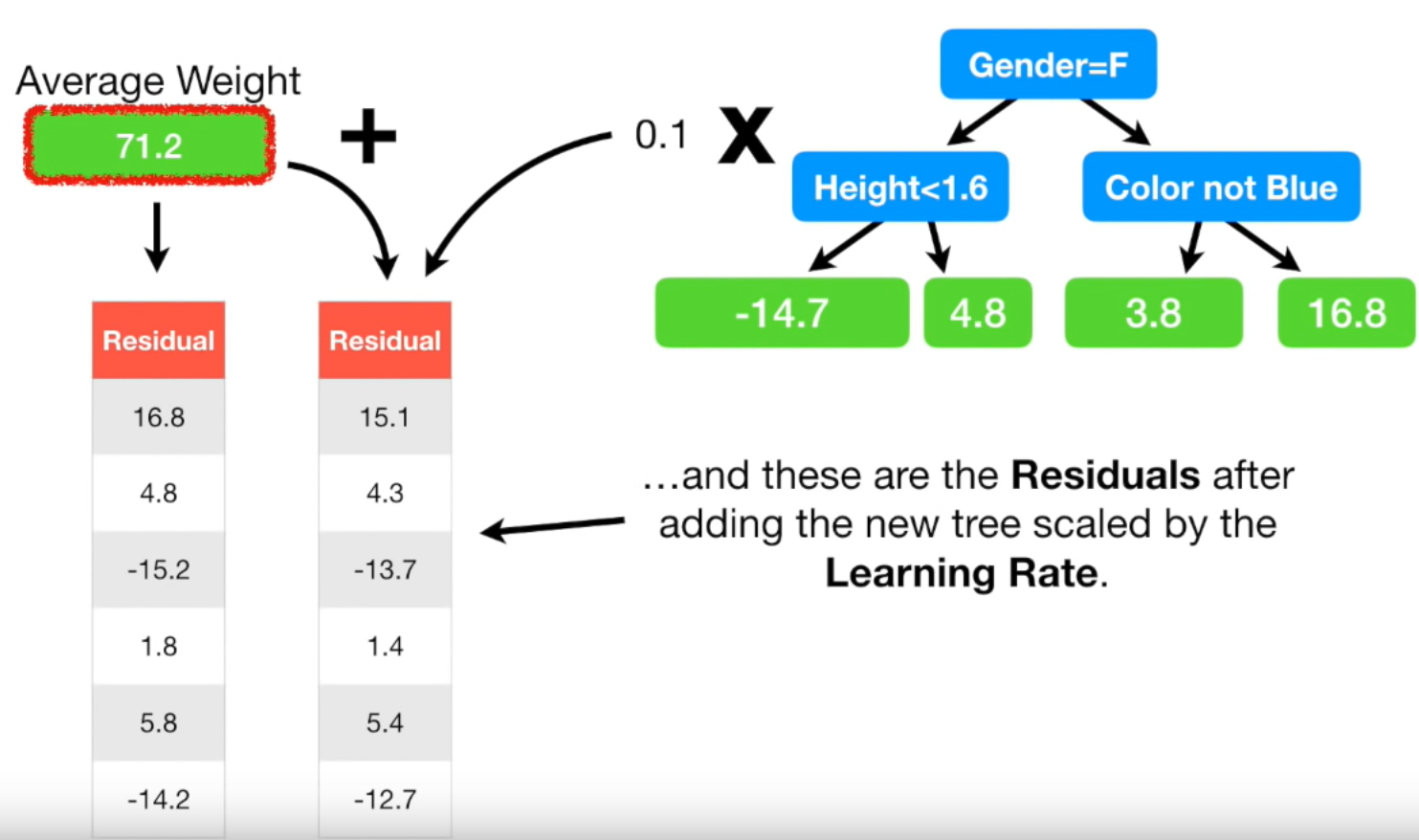
왼쪽이 처음 구한 Residual입니다. 이는 평균값인 71.2만 할용해서 구한 값입니다. 오른쪽이 결합된 모델로 구한 Residual입니다. 새로운 Residual은 초기 Residual보다 모두 작은 값입니다. Resiudal이 작아졌다는 뜻은 다른 말로 하면 실제 값과 예측 값의 차이가 작아졌다는 뜻입니다. 즉 조금씩 실제 값으로 다가가고 있다는 뜻입니다.
한 걸음 더 나아가 보겠습니다. 새로 구한 Residual로 트리도 새로 만들어보겠습니다.
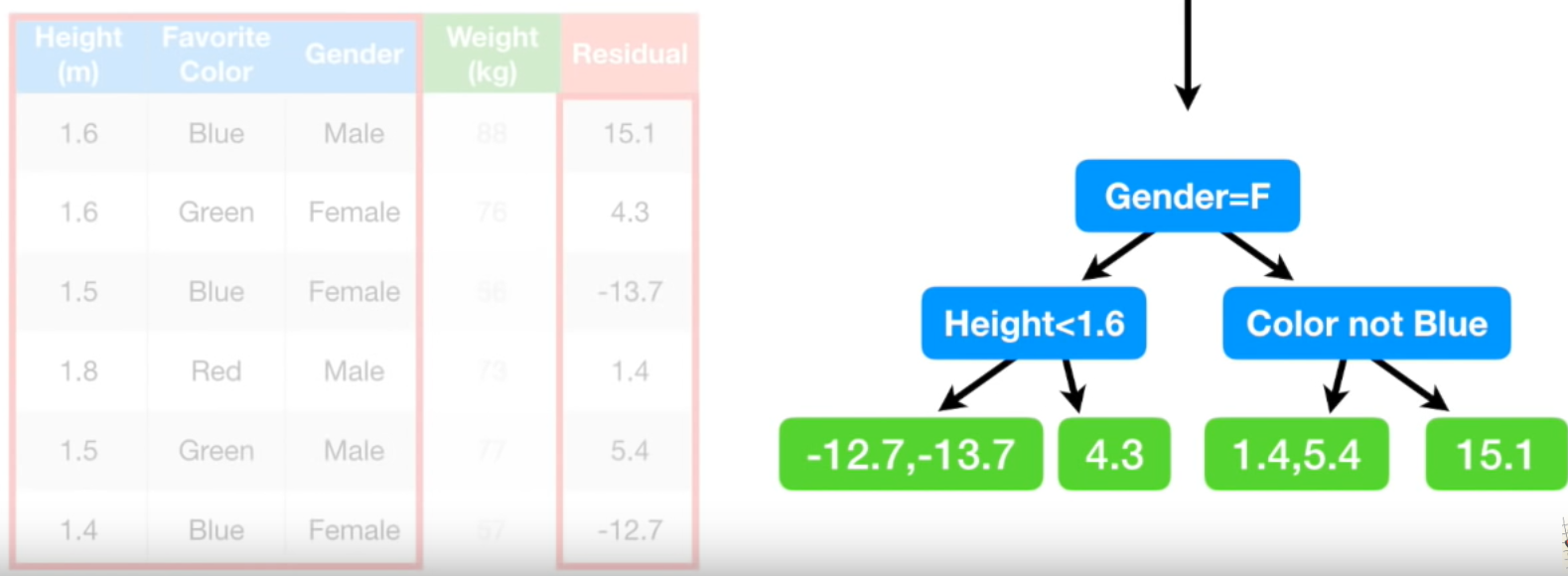
본 예제에서는 leaf가 4개인 트리를 계속 사용하지만 실제는 매 iteration마다 트리의 모양이 바뀔 수 있습니다. 즉, 첫 ietration에서는 leaf가 8개인 트리를 사용했다가, 두번째 iteration에서는 leaf가 16개인 트리를 사용할 수도 있습니다. 마찬가지로 두 값이 들어가 있는 첫번째 leaf와 세번째 leaf를 -12.7, -13.7의 평균값인 -13.2로 변경해주고, 1.4, 5.4의 평균값인 3.4로 변경해줍니다.
이제, 지금까지 구한 트리에 학습률을 곱한 뒤 합해줍니다.

'초기 leaf 트리+ (학습률 X 첫번째 residual 예측 트리) + (학습률 X 두번째 residual 예측 트리)'가 지금까지 구한 모델입니다.
지금까지 구한 모델을 통해 키 1.6m에 남자이고, 좋아하는 색깔이 파란색인 사람의 몸무게를 예측해보겠습니다.

74.4kg로 예측했습니다. 초기에는 평균 값인 71.2kg로 예측했고, 그 다음 스텝의 모델에선 71.2 + 0.1 * 16.8 = 72.9kg로 예측했고, 현재 모델에선 71.2 + 0.1 * 16.8 + 0.1 * 15.1 = 74.4kg로 예측했습니다. 실제 값은 88kg인데 실제 값과 조금씩 가까워지고 있습니다.
Residual도 구해보면 아래와 같습니다.
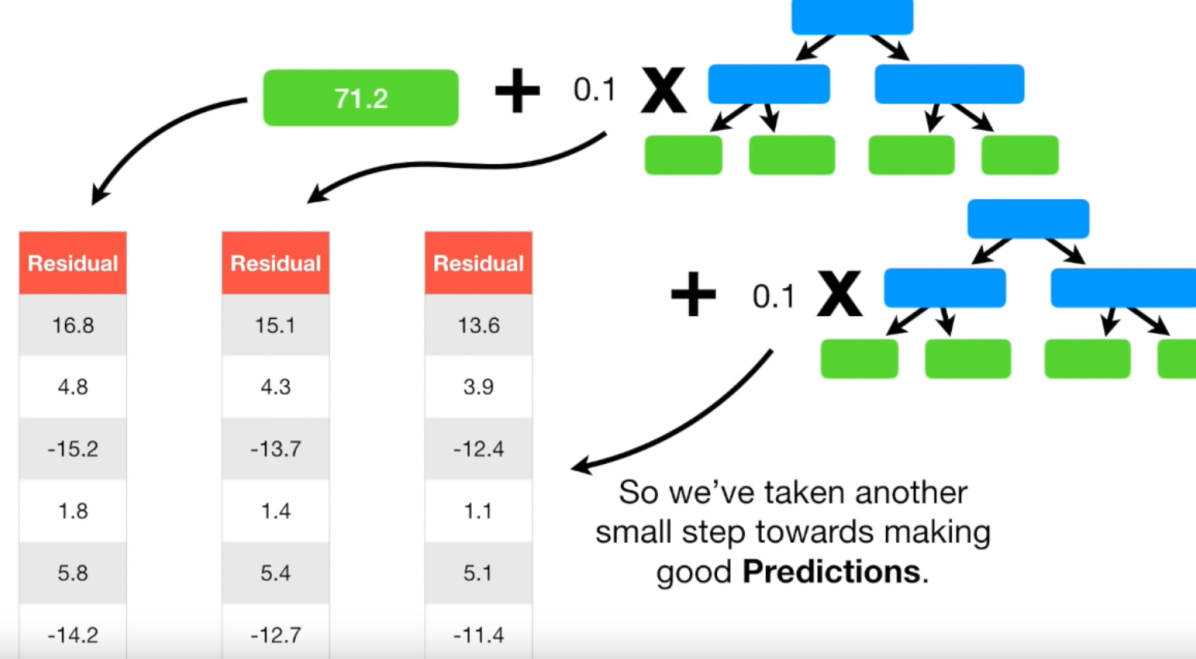
보시는 바와 같이 Residual을 점차 감소하고 있습니다. iteration을 할수록 Resiual이 감소합니다. 즉, 예측 정확도가 더 높아진다는 뜻입니다.
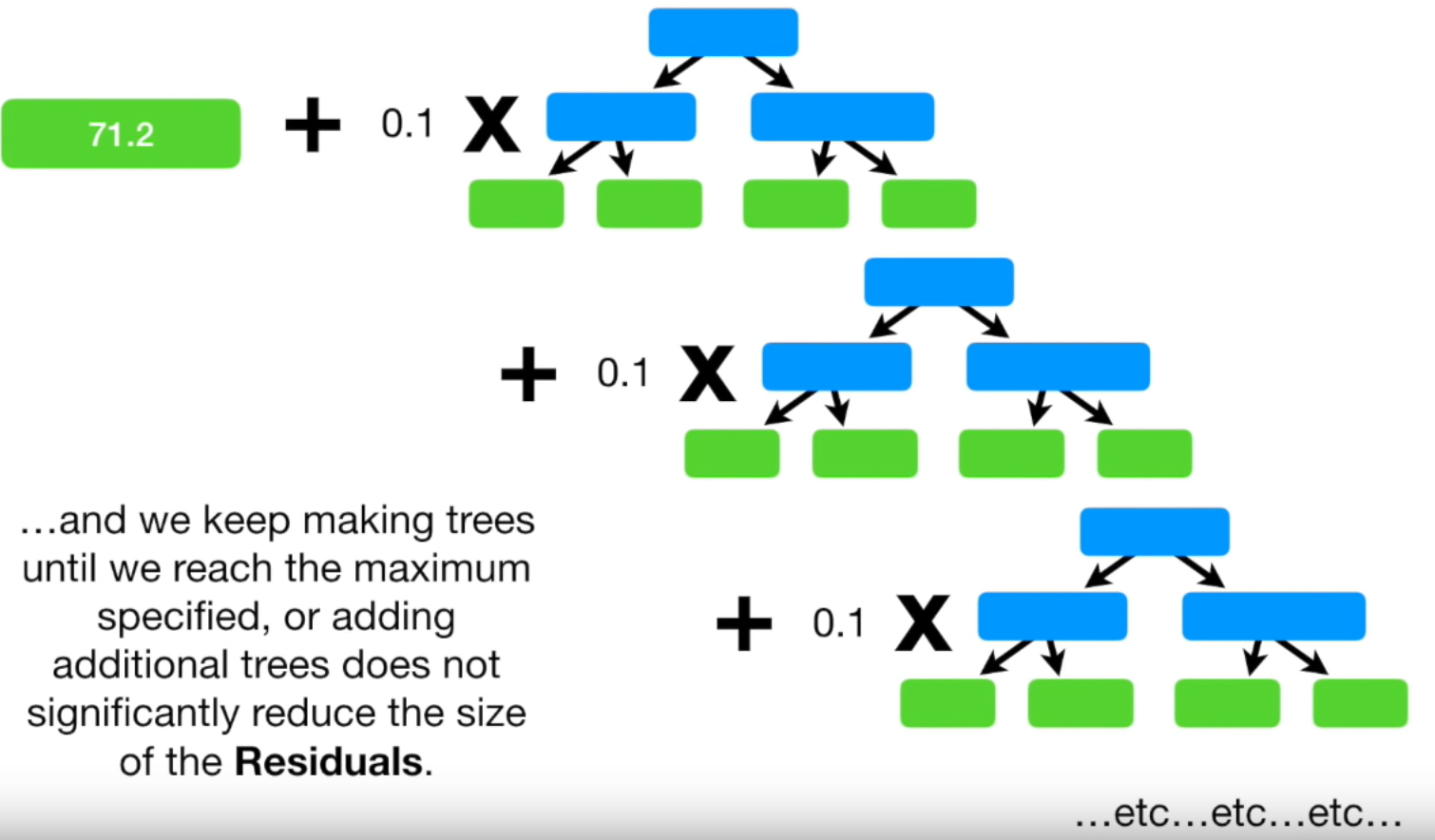
이렇게 계속 반복합니다. 언제까지? 사전에 하이퍼 파라미터로 정해 놓은 iteration 횟수에 도달하거나 더 이상 residual이 작아지지 않을 때까지 반복을 합니다. 모든 반복이 완료되었다면 최종적으로 Gradient Boost 모델이 구축된 것입니다. 이제 새로운 데이터가 주어지면 본 모델로 몸무게를 예측할 수 있습니다.
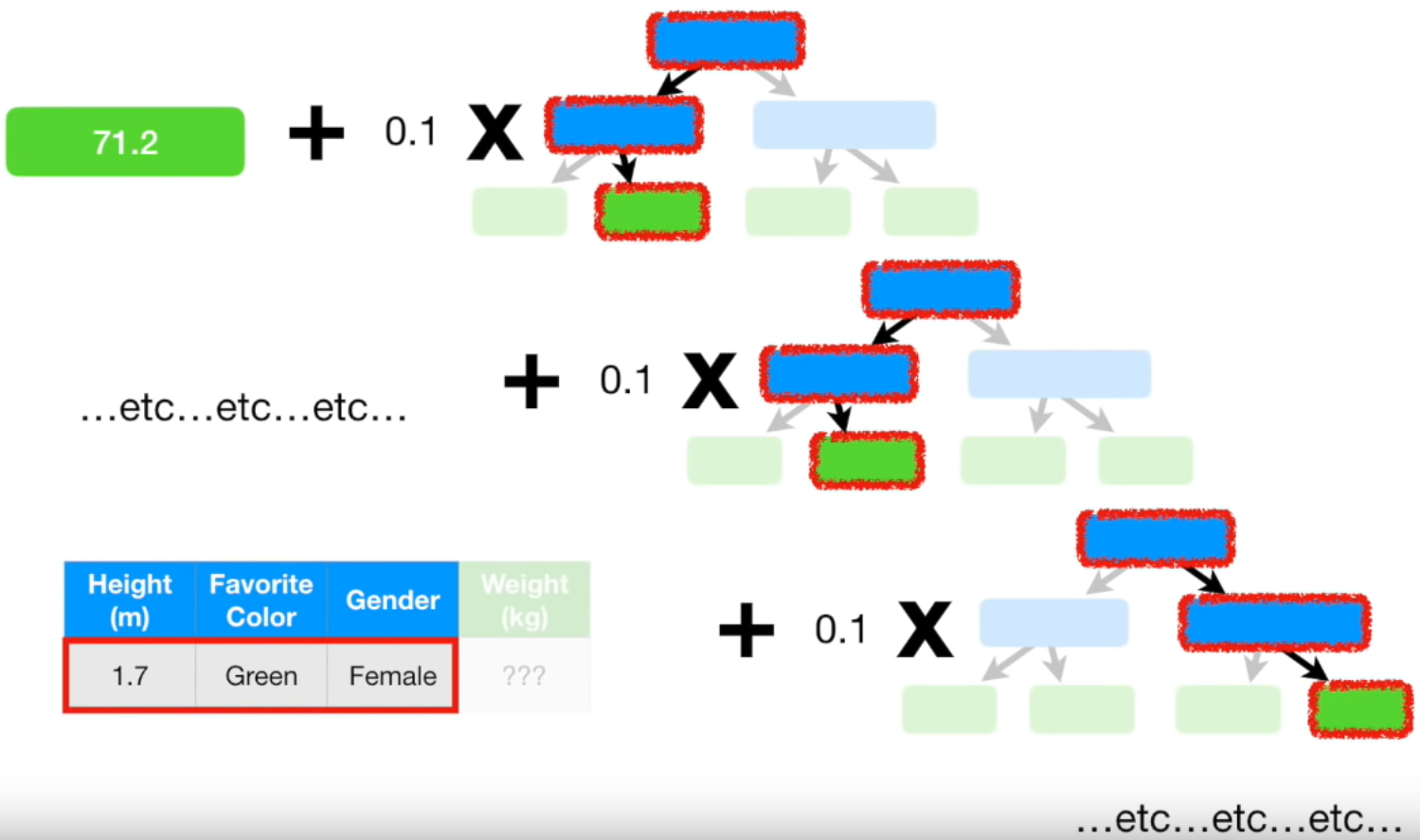
초기 평균 값인 71.2에 모든 트리의 학습률 * residual을 더해주면 몸무게를 예측할 수 있습니다. 키가 1.7m이고 좋아하는 색깔이 초록색이고 성별이 여자이면 몸무게는 70kg라는 결과를 얻을 수 있습니다.
Gradient Boost 모델은 이런 방식으로 학습됩니다.
앞서 말씀드린 것처럼 Gradient Boost를 발전시킨 모델이 XGBoost, Light GBM, CatBoost입니다. 더 빠르고 성능이 좋은 모델들이라고 보시면 됩니다.
Reference
Reference 1: StatQuest: Gradient Boost Part 1: Regression Main Ideas
'머신러닝' 카테고리의 다른 글
| 머신러닝 - 17. 회귀 평가 지표 (8) | 2019.12.06 |
|---|---|
| 머신러닝 - 16. NGBoost (16) | 2019.11.01 |
| 머신러닝 - 14. 에이다 부스트(AdaBoost) (19) | 2019.10.04 |
| 머신러닝 - 13. 파라미터(Parameter)와 하이퍼 파라미터(Hyper parameter) (12) | 2019.09.27 |
| 머신러닝 - 12. 편향(Bias)과 분산(Variance) Trade-off (0) | 2019.09.13 |



