
귀퉁이 서재
DATA - 19. 가변수(dummy variables)를 활용하여 범주형 데이터 모델링하기 본문

본 챕터는 이전 챕터와 내용이 연결되어 있습니다.
가변수를 활용하여 범주형 데이터를 양적 데이터로 변환하기
이전 챕터에서 범주형 데이터(categorical data)를 제외하고 양적 데이터(quantitative data)만을 사용해서 회귀 결과를 도출했습니다. 본 챕터에서는 회귀 모형에서 범주형 데이터를 어떻게 사용할 수 있는지 알아보겠습니다. 가변수(dummy variables)라는 것을 활용하여 회귀 모형에 범주형 데이터를 추가할 수 있습니다.

이전 챕터에서 Neighborhood와 Style이 범주형 데이터였습니다. Neighborhood에는 A, B, C 총 3개의 데이터가 있습니다. 이 데이터를 양적 데이터로 바꾸기 위해서 위 그림과 같이 가변수(dummy variables)를 사용하는 것입니다. 먼저 A, B, C column을 만듭니다. A column에는 A가 있는 row만 1, 나머지는 0인 값을 채워 넣습니다. B column에는 B가 있는 row만 1, 나머지는 0인 값으로 채워 넣습니다. C도 마찬가지입니다. 여기서 0과 1은 수치로서 의미가 있지는 않습니다. 단지 A인지 B인지를 구분하기 위한 숫자에 불과합니다. 범주형 데이터를 양적 데이터로 변환한 겁니다. (이를 0, 1 encoding이라고 합니다.) 이렇게 하면 회귀 모형에서 Neighborhood column 대신 A, B, C column을 사용할 수 있습니다.
하지만, A, B, C column 모두 OLS 메서드에 넣지는 않습니다. A, B, C 중 하나의 가변수는 drop 해줘야 합니다.
A, B, C 중 하나의 가변수를 drop해줘야 하는 이유 (독립 변수 A, B, C를 행렬 X라고 하겠습니다.)
1. column 간 (즉, 독립 변수간) 독립성(independency)을 보장하기 위해 (Reference1)
- A, B, C columns 중 하나는 1입니다. A와 B가 0이면 C는 1입니다. 즉, 두 개의 column 값만 알면 나머지 column값이 무엇인지 유추할 수 있습니다. 이는 A, B값이 C의 값에 영향을 준다는 뜻이기 때문에 A, B, C가 서로 독립이 아니라는 뜻입니다. 독립 변수 X는 종속 변수 Y에만 영향을 주어야지 독립 변수끼리 영향을 주면 안 됩니다. 독립 변수끼리 서로 독립이 아니면 이전 챕터에서처럼 bedrooms와 price가 음의 상관관계라는 잘못된 결과가 나옵니다. A, B, C columns 중 하나를 drop 하면 독립 변수 간의 독립성이 보장됩니다.
2. X를 full rank로 만들기 위해
- 행렬 X의 모든 column과 row가 독립이면 X는 full rank라고 합니다. (Reference2)
3. X'X의 역행렬을 구하기 위해
- 이전 챕터에서 상관 계수를 구하는 선형대수식에 대해 알아봤습니다. X'X의 역행렬을 구하기 위해서는 X가 full rank이어야 합니다. 즉, X는 서로 독립이어야 합니다.
가변수 중 하나를 drop하지 않으면 독립 변수간 종속성이 발생합니다. 독립 변수간 상관관계가 나타나는 문제를 다중공선성(Multicollinearity)이라고 합니다. 범주형 데이터를 가변수화 했을 때 다중공선성이 발생하므로 이를 해결하기 위해 하나의 변수를 drop 하는 것입니다. 어떤 변수를 드랍하든 상관없습니다. 아무 변수나 drop 하면 되고, drop 한 변수를 baseline이라고 합니다.
0, 1 encoding 실습
역시 데이터셋은 제 깃헙에 있습니다.
import numpy as np
import pandas as pd
import statsmodels.api as sm;
import matplotlib.pyplot as plt
%matplotlib inline
df = pd.read_csv('house_prices.csv')
df.head()
pd.get_dummies(df.neighborhood)
이렇게 pandas의 get_dummies라는 메서드로 범주형 데이터를 쉽게 양적 데이터로 바꿀 수 있습니다.
df['intercept'] = 1
df_new = df.join(pd.get_dummies(df.neighborhood))
sm.OLS(df_new['price'], df_new[['A', 'B', 'C', 'intercept']]).fit().summary()
A, B, C의 신뢰 구간(confidence interval) 범위가 아주 아주 아주 큽니다. 의미 없는 신뢰 구간입니다. 이는 독립 변수 행렬 X가 full rank가 아닐 때, 즉 독립 변수가 independent가 아닐 때 발생합니다. 의미 없는 결과를 수정하기 위해서는 아래처럼 A, B, C 중 하나의 column을 drop 한 뒤 모델링해줘야 합니다. (dataframe에서 실제로 column을 drop 하는 게 아니라 모델링할 때 변수로 안 넣는 것뿐입니다.)
sm.OLS(df_new['price'], df_new[['intercept', 'B', 'C']]).fit().summary()

drop한 변수를 baseline variable이라고 했습니다. 위 예시에서는 A를 drop 했습니다. intercept 계수가 541,100입니다. 이는 Neighborhood가 A일 때의 평균 집 값이 $541,000이라는 뜻입니다. baseline을 intercept로 보면 됩니다. B의 coef는 529,500입니다. 이는 baseline 대비 차이입니다. 따라서 Neighborhood가 B일 때 평균 집 값은 A일 때보다 529,500 높은 541,000 + 529,500 = $1,070,500입니다. 마찬가지로 C일 때 평균 집 값은 A일 때보다 332만큼 작습니다. 즉, 541,000 - 332 = $540,668입니다. drop 한 가변수를 intercept로 보고, 나머지 가변수의 coef는 baseline 대비 차이로 보시면 됩니다. 결론적으로 집 값은 B > A > C 순으로 비쌉니다.
'neighborhood B와 A의 평균 집 값이 차이가 있다'는 가설을 검정하기 위해서는 p-value를 보면 됩니다. p-value가 0이므로 이 가설은 통계적으로 유의합니다. 'neighborhood B와 C의 평균 집 값이 차이가 있다'는 가설을 검정하기 위해서는 신뢰 구간을 보면 됩니다. 신뢰 구간이 겹치지 않기 때문에 이 가설도 통계적으로 유의합니다. A(baseline)와 B, C를 비교하기 위해서는 p-value를 보면 되고, B와 C를 비교하기 위해서는 신뢰 구간을 보면 됩니다. 정리하자면 Baseline과의 차이이에 대한 가설 검정은 p-value로 해야 하고, 가변수끼리의 차이 가설 검정은 신뢰 구간으로 하면 되는 것입니다.
-1, 0, 1 encoding
0, 1 encoding 말고 -1, 0, 1로 encoding을 할 수 있습니다. 0, 1 encoding은 baseline 변수와 비교를 하지만 -1, 0, 1 encoding은 변수의 평균과 비교를 합니다.
import numpy as np
import pandas as pd
import statsmodels.api as sm
df = pd.read_csv('house_prices.csv')
## The below function creates 1, 0, -1 coded dummy variables.
def dummy_cat(df, col):
'''
INPUT:
df - the dataframe where col is stored
col - the categorical column you want to dummy (as a string)
OUTPUT:
df - the dataframe with the added columns
for dummy variables using 1, 0, -1 coding
'''
for idx, val_0 in enumerate(df[col].unique()):
if idx + 1 < df[col].nunique():
df[val_0] = df[col].apply(lambda x: 1 if x == val_0 else 0)
else:
df[val_0] = df[col].apply(lambda x: -1 if x == val_0 else 0)
for idx, val_1 in enumerate(df[col].unique()):
if idx + 1 < df[col].nunique():
df[val_1] = df[val_0] + df[val_1]
else:
del df[val_1]
return df
new_df = dummy_cat(df, 'style') # Use on style
new_df.head(10)
ranch와 vitorian column이 -1, 0, 1로 encoding 되었습니다. ranch column에서 1은 ranch, 0은 victorian, -1은 lodge입니다. victorian에서 1은 victorian, 0은 ranch, -1은 lodge입니다.
new_df['intercept'] = 1
lm = sm.OLS(new_df['price'], new_df[['intercept', 'ranch', 'victorian']])
results = lm.fit()
results.summary()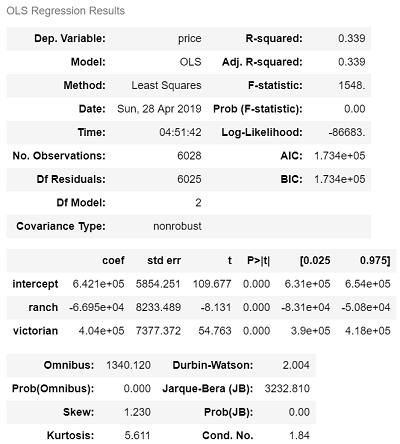
0, 1 encoding에선 intercept coef이 baseline 변수에 대한 값이었습니다. -1, 0, 1 encoding에선 intercept coef에 모든 변수의 평균값이 나옵니다. 즉 home style에 상관 없이 집 값의 평균은 $642,100입니다. victorian의 coef는 404,000입니다. 이는 모든 다른 변수가 동일할 때, vitorian의 평균 집 값이 전체 집 값 평균에 비해 $404,000 비싸다는 뜻입니다.
lodge style의 집 값은 intercept coef - ranch coef - victorian coef을 계산해 구할 수 있습니다. intercept coef는 전체 변수의 평균입니다. ranch coef와 victorian coef에 - 를 붙이는 이유는 맨 처음 -1, 0, 1 encoding을 할 때 lodge를 -1로 치환했기 때문입니다. 따라서 전체 집값의 평균에 비해 lodge style의 평균 집 값은 642,100 - (-66,950) - (404,000) = $305,050만큼 비쌉니다.
추가로, 양적 데이터를 모델링할 때는 coefficient가 'x가 1 증가할 때 y의 증가량'이었습니다. 하지만 범주형 데이터에서는 적용되지 않습니다. 따라서 victorian coef가 404,000라고 해서 victorian style이 하나 증가할 때마다 집 값이 404,000만큼 증가한다고 말할 수 없습니다. victorian style은 범주형 데이터이기 때문에 victorian style이 하나 증가한다는 것도 말이 안 되는 것입니다.
References
Reference1 : DUMMY VARIABLE TRAP IN REGRESSION MODELS
Reference2 : FAQ: What does it mean for a non-square matrix to be full rank?
'데이터 분석' 카테고리의 다른 글
| DATA - 21. Higher order term (3) | 2019.05.02 |
|---|---|
| DATA - 20. 다중공선성(Multicollinearity)과 VIF(Variance Inflation Factors) (9) | 2019.05.01 |
| DATA - 18. 다중 선형 회귀 (Multiple linear regression) (4) | 2019.04.30 |
| DATA - 17. 최소자승법(OLS)을 활용한 단순 선형 회귀 (Simple Linear Regression) (8) | 2019.04.28 |
| DATA - 16. A/B Test (4) | 2019.04.25 |



