
귀퉁이 서재
머신러닝 - 10. 교차검증(Cross Validation)과 혼동행렬(Confusion Matrix) 본문

교차검증 (Cross Validation)
교차검증은 모델을 평가하는 방법 중 하나입니다. 기본적으로 훈련 데이터를 기반으로 모델링을 하고 테스트 데이터로 해당 모델의 성능을 측정합니다. 하지만 테스트 데이터의 수가 적다면 성능 평가의 신뢰성이 떨어집니다. 테스트 데이터를 어떻게 잡느냐에 따라 성능이 상이하게 나온다면 신뢰성이 떨어지겠죠. 그렇다고 훈련 데이터를 줄이고 테스트 데이터를 늘리면 정상적인 학습이 되지 않습니다. 이런 문제점을 해결하기 위한 방법이 교차검증입니다.
훈련 데이터의 종속 변수값을 얼마나 잘 예측하였는지를 나타내는 것을 표본내 성능 검증 (in-sample testing)이라고 하고, 테스트 데이터의 종속 변수값을 얼마나 잘 예측하였는지를 나타내는 것을 표본외 성능 검증 (out-of-sample testing) 혹은 교차검증(cross validation)이라고 합니다. (Reference1)
K-fold 교차검증(K-fold Cross Validation)
교차검증이라고 하면 일반적으로 K-fold 교차검증을 말합니다. K-fold 교차검증의 프로세스는 아래와 같습니다.
1. 데이터를 K개로 쪼갠다.
2. 하나는 검증 데이터, 나머지는 훈련 데이터로 사용해 성능을 구한다.
3. 또 다른 부분을 검증 데이터, 나머지를 훈련 데이터로 사용해 성능을 구한다.
4. K번 반복한다.
5. K번의 성능의 평균을 구한다.
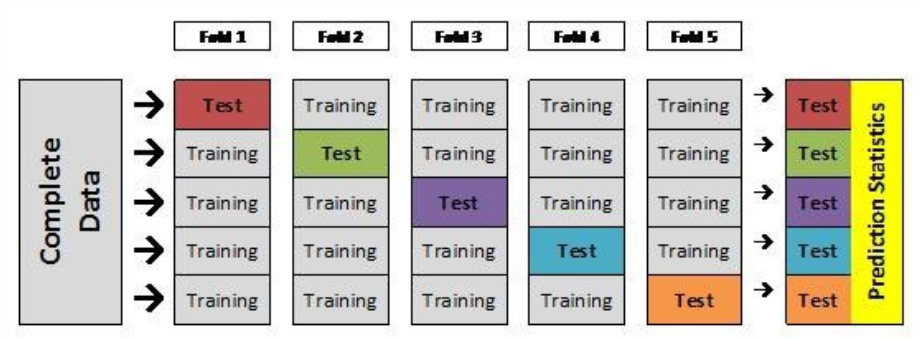
K번의 성능 평균이 최종 성능이 되는 것입니다. 위 예제에서는 K=5입니다. 이렇게 하면 모든 데이터가 한번씩은 검증 데이터로 쓰입니다. 따라서 데이터의 편향으로 인해 성능이 잘못 도출되는 일을 예방할 수 있습니다. 성능을 보다 정확하게 구할 수 있다는 장점이 있지만 시간과 메모리를 많이 쓰겠죠?
Stratified K-fold 교차검증
Stratified K-fold는 불균형한(imbalanced) 분포도를 가진 레이블(타겟 값) 데이터 집합을 위한 K-fold 교차검증 방식입니다. 예를 들어 대출 사기 데이터를 에측한다고 가정해 봅시다. 데이터 세트는 1만건이고, 그 중 사기 건수는 10건이라고 해 봅시다. 사기 건수는 10건 밖에 안되므로 K-fold를 하더라도 특정 훈련 데이터 세트에는 사기 건수가 아예 없을 수도 있습니다. 사기 건수에 대한 데이터가 없이 training을 한다면 사기에 대한 예측을 전혀 할 수 없겠죠. 의미 없는 모델이 만들어질 겁니다. 이를 방지하기 위해 사기 건수에 대한 데이터를 균일하게 나누어 주는 방식이 Stratified K-fold입니다. fold = 5라고 했을 때 fold1에 사기 건수 2개, fold2에 사기 건수 2개, .... , fold5에 사기 건수 2개씩 골고루 들어가게 하는 방식입니다.
혼동행렬(Confusion Matrix)
Confusion Matirx는 훈련된 모델의 성능을 측정하기 위한 Matrix입니다. (Reference2)
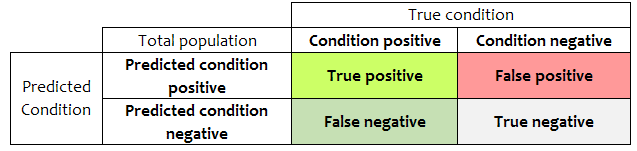
TP(True Positive): True를 True로 잘 예측한 것
TN(True Negative): False를 False로 잘 예측한 것
FP(False Positive): False를 True로 잘 못 예측한 것
FN(False Negative): True를 False로 잘 못 예측한 것
정확도, 정밀도, 재현율
Confusion Matrix를 통해 측정할 수 있는 대표적인 모델 성능지표는 아래와 같습니다.
Accuracy(정확도): (TP + TN) / Total
전체 클래스 중 True는 True로 False는 False로 잘 예측했는지?
정확도는 타겟값이 불균형한 데이터에서는 적절한 평가지표가 아닙니다. 예를 들어, 신용 카드 사기 건수에 대한 데이터가 있다고 합시다. 100,000개의 데이터 중 99,900개가 정상 거래고, 100개가 사기 거래입니다. 예측을 할 때 그냥 '모든 거래가 다 정상 거래이다'라고 예측해도 정확도는 99.9%입니다. 하지만 우리가 원하는 건 사기 거래에 대한 예측입니다. 이렇듯 타겟값이 불균형할 땐 정확도는 적저러한 평가지표가 아닙니다.
Precision(정밀도): TP / (TP + FP)
모델이 True로 예측한 값들 중에서 정말로 예측한 값이 맞는지?
정밀도는 양성 예측도라고도 불립니다. 정밀도가 상대적으로 더 중요한 지표인 경우는 실제 Negative 음성인 데이터 예측을 Positive로 잘못 판단하게 되면 업무상 큰 불이익이 발생하는 경우입니다.
Recall(재현율): TP / (TP + FN)
True 클래스 중 모델이 잘 예측한 클래스의 비율?
재현율은 민감도(Sensitivity) 혹은 TPR(True Positive Rate)라고도 불립니다. 재현율이 상대적으로 더 중요한 지표인 경우는 실제 Positive 양성인 데이터 예측을 Negative로 잘못 판단하게 되면 업무상 큰 불이익이 발생하는 경우입니다.
F1 Score
정밀도와 재현율은 상호 보완할 수 있는 수준에서 적용돼야 합니다. 그렇지 않고 단순히 하나의 성능 지표 수치를 높이기 위한 수단으로 사용해서는 안 됩니다. 정밀도와 재현율을 결합한 지표를 F1 Score라고 합니다. F1 Score는 정밀도와 재현율이 어느 한쪽으로 치우치지 않는 수치를 나타낼 때 상대적으로 높은 값을 가집니다.
F1 Score = 2 X (정밀도 X 재현율) / (정밀도 + 재현율)
이상으로 모델의 성능 측정을 위한 Confusion matrix, 그리고 성능 평가 신뢰성을 높일 수 있는 K-fold 교차검증에 대해 알아봤습니다.
References
Reference1: 데이터 사이언스 스쿨 (4.4 교차검증)
Refernece2: Confusion matrix, accuracy, f1 score, precision, recall
'머신러닝' 카테고리의 다른 글
| 머신러닝 - 12. 편향(Bias)과 분산(Variance) Trade-off (0) | 2019.09.13 |
|---|---|
| 머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting) (12) | 2019.09.12 |
| 머신러닝 - 9. 차원 축소와 PCA (Principal Components Analysis) (9) | 2019.08.11 |
| 머신러닝 - 8. Feature Scaling & Feature Selection (0) | 2019.08.04 |
| 머신러닝 - 7. K-평균 클러스터링(K-means Clustering) (4) | 2019.07.29 |



